Papers positioned by semantic similarity (SPECTER embeddings + t-SNE). Shape encodes publication type, color encodes year. Click any paper to explore.
MIT Initiative for New Manufacturing
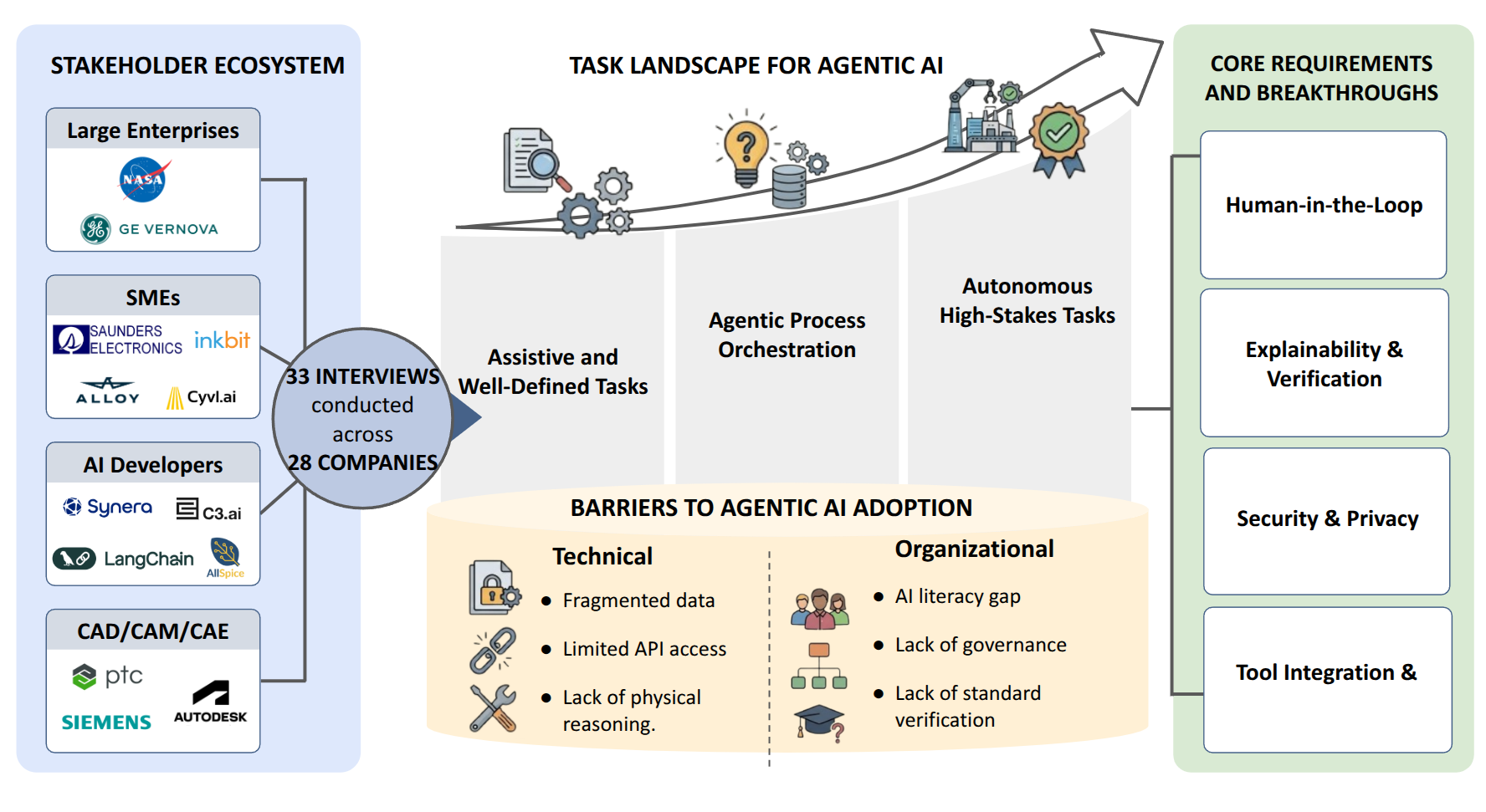
This work examines how AI, especially agentic systems, is being adopted in engineering and manufacturing workflows, what value it provides today, and what is needed for broader deployment. This is an exploratory and qualitative state-of-practice study grounded in over 30 interviews across four stakeholder groups (large enterprises, small/medium firms, AI developers, and CAD/CAM/CAE vendors). We find that near-term AI gains cluster around structured, repetitive work and data-intensive synthesis, while higher-value agentic gains come from orchestrating multi-step workflows across tools. Adoption is constrained less by model capability than by fragmented and machine-unfriendly data, stringent security and regulatory requirements, and limited API-accessible legacy toolchains. Reliability, verification, and auditability are central requirements for adoption, driving human-in-the-loop frameworks and governance aligned with existing engineering reviews.
Under Review
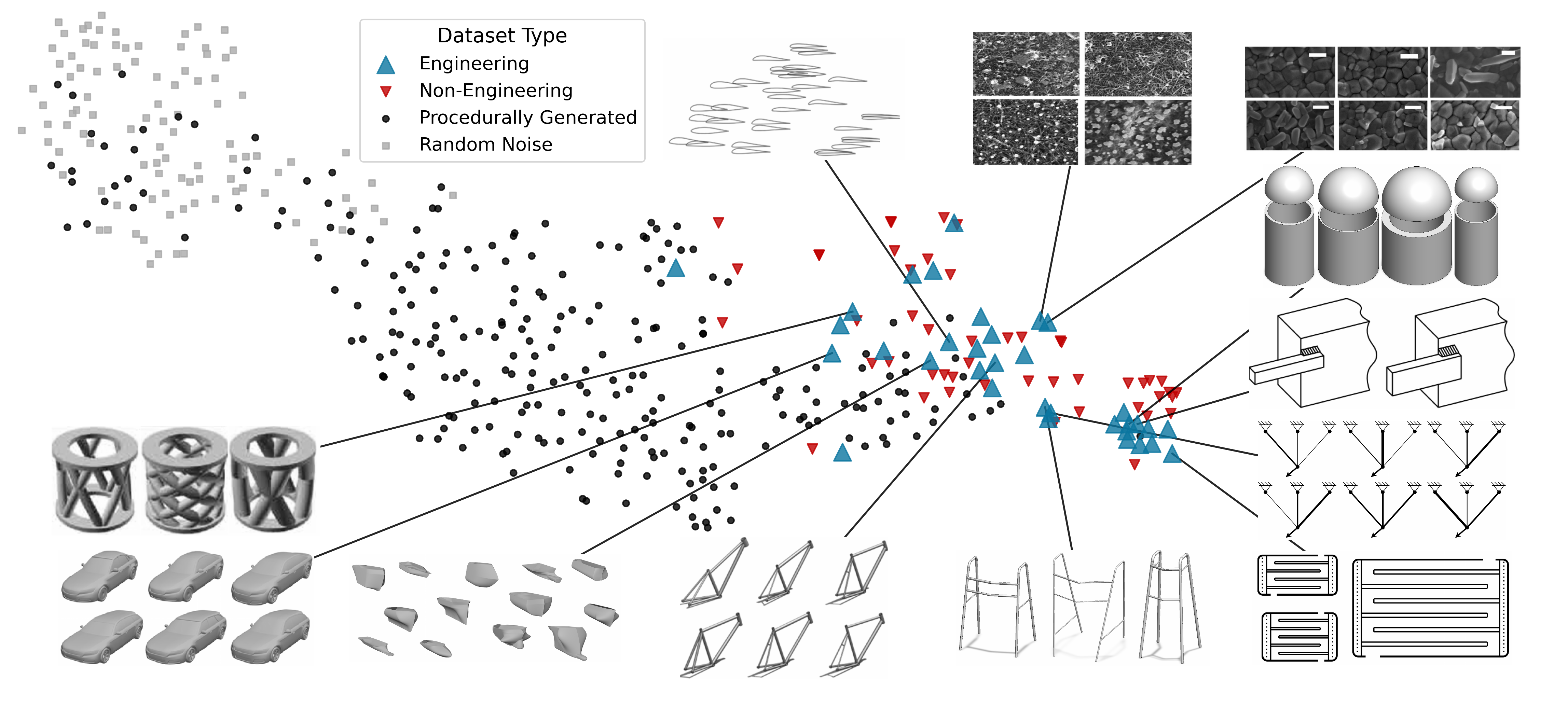
Predictive modeling in engineering applications has long been dominated by bespoke models and small, siloed tabular datasets, limiting the applicability of large-scale learning approaches. Despite recent progress in tabular foundation models, the resulting synthetic training distributions used for pre-training may not reflect the statistical structure of engineering data, limiting transfer to engineering regression. We introduce TREDBench, a curated collection of 83 real-world tabular regression datasets with expert engineering/non-engineering labels, and use TabPFN 2.5's dataset-level embedding to study domain structure in a common representation space. We find that engineering datasets are partially distinguishable from non-engineering datasets, while standard procedurally generated datasets are highly distinguishable from engineering datasets, revealing a substantial synthetic-real domain gap. To bridge this gap without training on real engineering samples, we propose an embedding-guided synthetic data curation method: we generate and identify "engineering-like" synthetic datasets, and perform continued pre-training of TabPFN 2.5 using only the selected synthetic tasks. Across 35 engineering regression datasets, this synthetic-only adaptation improves predictive accuracy and data efficiency, outperforming TabPFN 2.5 on 29/35 datasets and AutoGluon on 27/35, with mean multiplicative data-efficiency gains of 1.75x and 4.44x, respectively. More broadly, our results indicate that principled synthetic data curation can convert procedural generators into domain-relevant "data engines," enabling foundation models to improve in data-sparse scientific and industrial domains where real data collection is the primary bottleneck.

In ICLR 2026
Bayesian optimization (BO) effectively optimizes expensive black-box functions but faces significant challenges in high-dimensional spaces (dimensions exceeding 100) due to the curse of dimensionality. Existing high-dimensional BO methods typically leverage low-dimensional embeddings or structural assumptions to mitigate this challenge, yet these approaches frequently incur considerable computational overhead and rigidity due to iterative surrogate retraining and fixed assumptions. To address these limitations, we propose Gradient-Informed Bayesian Optimization using Tabular Foundation Models (GIT-BO), an approach that utilizes a pre-trained tabular foundation model (TFM) as a surrogate, leveraging its gradient information to adaptively identify low-dimensional subspaces for optimization. We propose a way to exploit internal gradient computations from the TFM's forward pass by creating a gradient-informed diagnostic matrix that reveals the most sensitive directions of the TFM's predictions, enabling optimization in a continuously re-estimated active subspace without the need for repeated model retraining. Extensive empirical evaluation across 23 synthetic and real-world benchmarks demonstrates that GIT-BO consistently outperforms four state-of-the-art Gaussian process-based high-dimensional BO methods, showing superior scalability and optimization performances, especially as dimensionality increases up to 500 dimensions. This work establishes foundation models, augmented with gradient-informed adaptive subspace identification, as highly competitive alternatives to traditional Gaussian process-based approaches for high-dimensional Bayesian optimization tasks.
Under Review
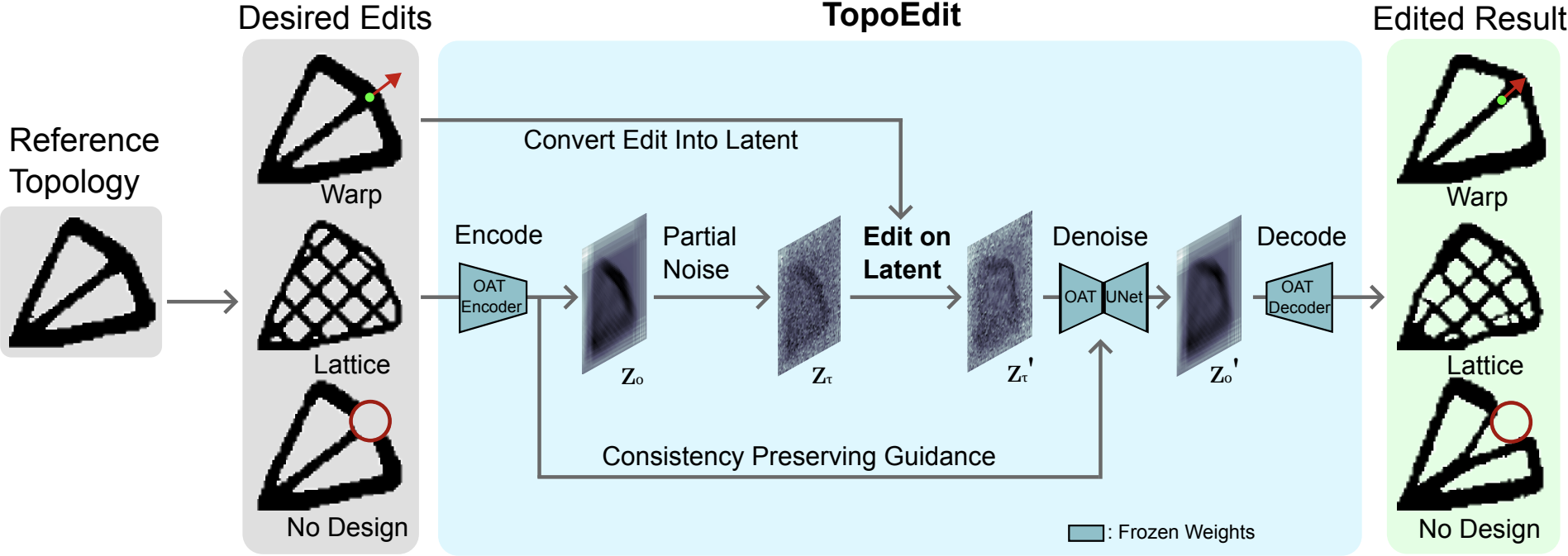
Despite topology optimization producing high-performance structures, late-stage localized revisions remain brittle: direct density-space edits (e.g., warping pixels, inserting holes, swapping infill) can sever load paths and sharply degrade compliance, while re-running optimization is slow and may drift toward a qualitatively different design. We present TopoEdit, a fast post-optimization editor that demonstrates how structured latent embeddings from a pre-trained topology foundation model (OAT) can be repurposed as an interface for physics-aware engineering edits. Given an optimized topology, TopoEdit encodes it into OAT's spatial latent, applies partial noising to preserve instance identity while increasing editability, and injects user intent through an edit-then-denoise diffusion pipeline. We instantiate three edit operators: drag-based topology warping with boundary-condition-consistent conditioning updates, shell-infill lattice replacement using a lattice-anchored reference latent with updated volume-fraction conditioning, and late-stage no-design region enforcement via masked latent overwrite followed by diffusion-based recovery. A consistency-preserving guided DDIM procedure localizes changes while allowing global structural adaptation; multiple candidates can be sampled and selected using a compliance-aware criterion, with optional short SIMP refinement for warps. Across diverse case studies and large edit sweeps, TopoEdit produces intention-aligned modifications that better preserve mechanical performance and avoid catastrophic failure modes compared to direct density-space edits, while generating edited candidates in sub-second diffusion time per sample.

In Computer Methods in Applied Mechanics and Engineering 2026
A major obstacle to establishing reliable structure-property (SP) linkages in materials engineering is the scarcity of diverse 3D microstructure datasets. Limited dataset availability and insufficient control over the analysis and design space restrict the variety of achievable microstructure morphologies, hindering progress in solving the inverse (property-to-structure) design problem. To address these challenges, we introduce MicroLad, a latent diffusion framework specifically designed for reconstructing 3D microstructures from 2D data. Trained on 2D images and employing multi-plane denoising diffusion sampling in the latent space, the framework reliably generates stable and coherent 3D volumes that remain statistically consistent with the original data. While this reconstruction capability enables dimensionality expansion (2D-to-3D) for generating statistically equivalent 3D samples from 2D data, effective exploration of microstructure design requires methods to guide the generation process toward specific objectives. To achieve this, MicroLad integrates score distillation sampling (SDS), which combines a differentiable score loss with microstructural descriptor-matching and property-alignment terms. This approach updates encoded 2D slices of the 3D volume in the latent space, enabling robust inverse-controlled 2D-to-3D microstructure generation. Consequently, the method facilitates exploration of an expanded 3D microstructure analysis and design space in terms of both microstructural descriptors and material properties.
Under Review
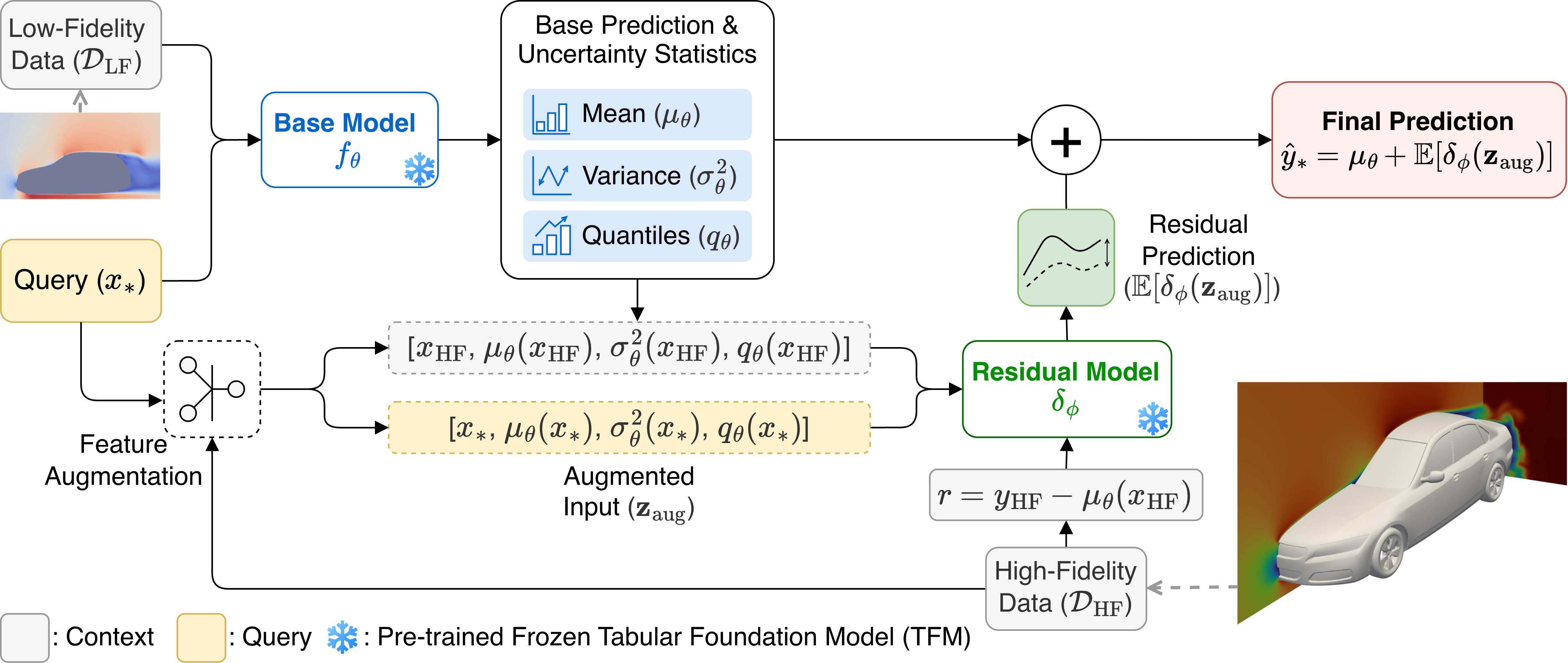
Multi-fidelity (MF) regression often operates in regimes of extreme data imbalance, where the commonly-used Gaussian-process (GP) surrogates struggle with cubic scaling costs and overfit to sparse high-fidelity observations, limiting efficiency and generalization in real-world applications. We introduce FIRE, a training-free MF framework that couples tabular foundation models (TFMs) to perform zero-shot in-context Bayesian inference via a high-fidelity correction model conditioned on the low-fidelity model's posterior predictive distributions. This cross-fidelity information transfer via distributional summaries captures heteroscedastic errors, enabling robust residual learning without model retraining. Across 31 benchmark problems spanning synthetic and real-world tasks (e.g., DrivAerNet, LCBench), FIRE delivers a stronger performance-time trade-off than seven state-of-the-art GP-based or deep learning MF regression methods, ranking highest in accuracy and uncertainty quantification with runtime advantages. Limitations include context window constraints and dependence on the quality of the pre-trained TFM's.
Under Review
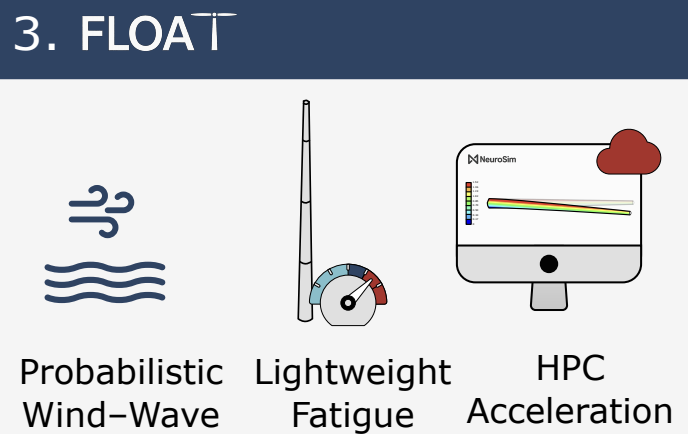
Upscaling is central to offshore wind's cost-reduction strategy, with increasingly large rotors and nacelles requiring taller and stronger towers. In Floating Offshore Wind Turbines (FOWTs), this trend amplifies fatigue loads due to coupled wind-wave dynamics and platform motion. Conventional fatigue evaluation requires millions of high-fidelity simulations, creating prohibitive computational costs and slowing design innovation. This paper presents FLOAT (Fatigue-aware Lightweight Optimization and Analysis for Towers), a framework that accelerates fatigue-aware tower design. It integrates three key contributions: a lightweight fatigue estimation method that enables efficient optimization, a Monte Carlo-based probabilistic wind-wave sampling approach that reduces required simulations, and enhanced high-fidelity modeling through pitch/heave-platform calibration and High-Performance Computing (HPC) execution. The framework is applied to the IEA 22 MW FOWT tower, delivering, to the authors' knowledge, the first fatigue-oriented redesign of this benchmark model: FLOAT 22 MW FOWT tower. Validation against 6,468 simulations demonstrates that the optimized tower extends the estimated fatigue life from ~9 months to 25 years while avoiding resonance, and that the lightweight fatigue estimator provides conservative predictions with a mean relative error of -8.6%. Achieving this lifetime requires increased tower mass, and the final design represents the lowest-mass fatigue-compliant configuration within the selected design space. All results and the reported lifetime extension are obtained within the considered fatigue scope, namely DLC 1.2 under aligned wind-wave conditions for the selected site distributions. By reducing simulation requirements by orders of magnitude, FLOAT provides a computationally efficient pathway for reliable and scalable tower design in next-generation FOWTs, bridging industrial needs and academic research while generating high-fidelity datasets that can support data-driven design methodologies.
In NeurIPS 2025
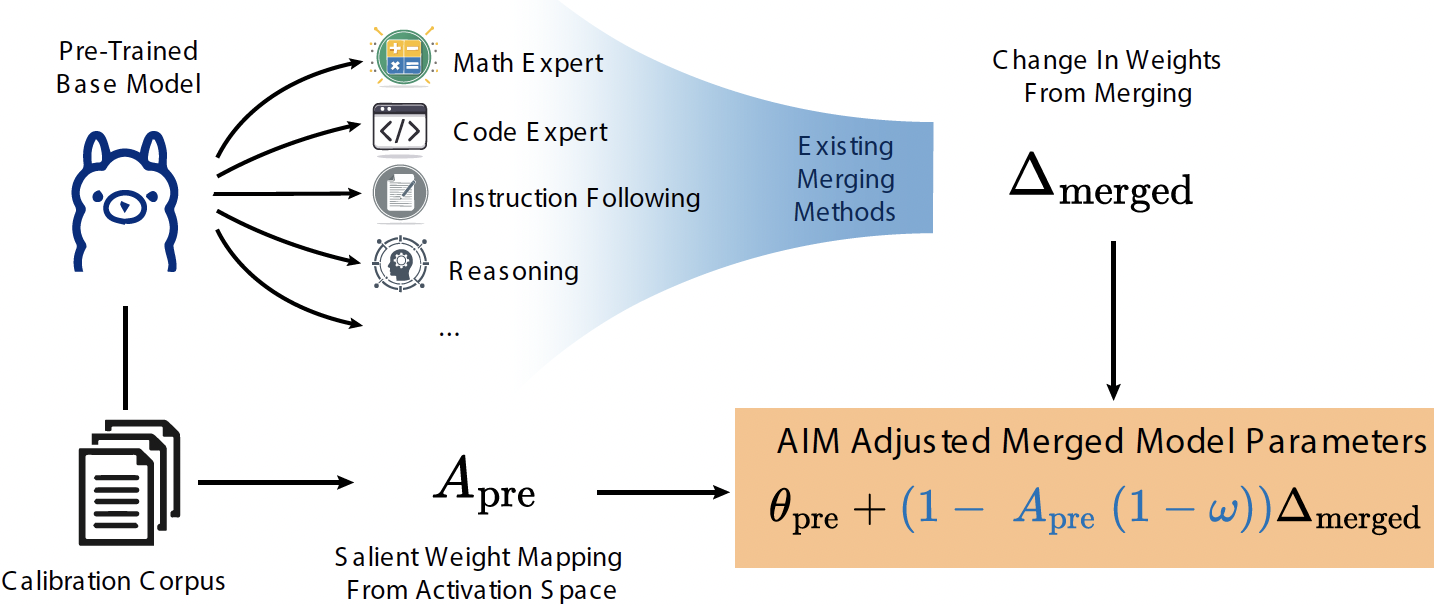
Model merging, a method that combines the parameters and embeddings of multiple fine-tuned large language models (LLMs), offers a promising approach to enhance model performance across various tasks while maintaining computational efficiency. This paper introduces Activation-Informed Merging (AIM), a technique that integrates the information from the activation space of LLMs into the merging process to improve performance and robustness. AIM is designed as a flexible, complementary solution that is applicable to any existing merging method. It aims to preserve critical weights from the base model, drawing on principles from continual learning (CL) and model compression. Utilizing a task-agnostic calibration set, AIM selectively prioritizes essential weights during merging. We empirically demonstrate that AIM significantly enhances the performance of merged models across multiple benchmarks. Our findings suggest that considering the activation-space information can provide substantial advancements in the model merging strategies for LLMs, with up to a 40% increase in benchmark performance.
In NeurIPS 2025
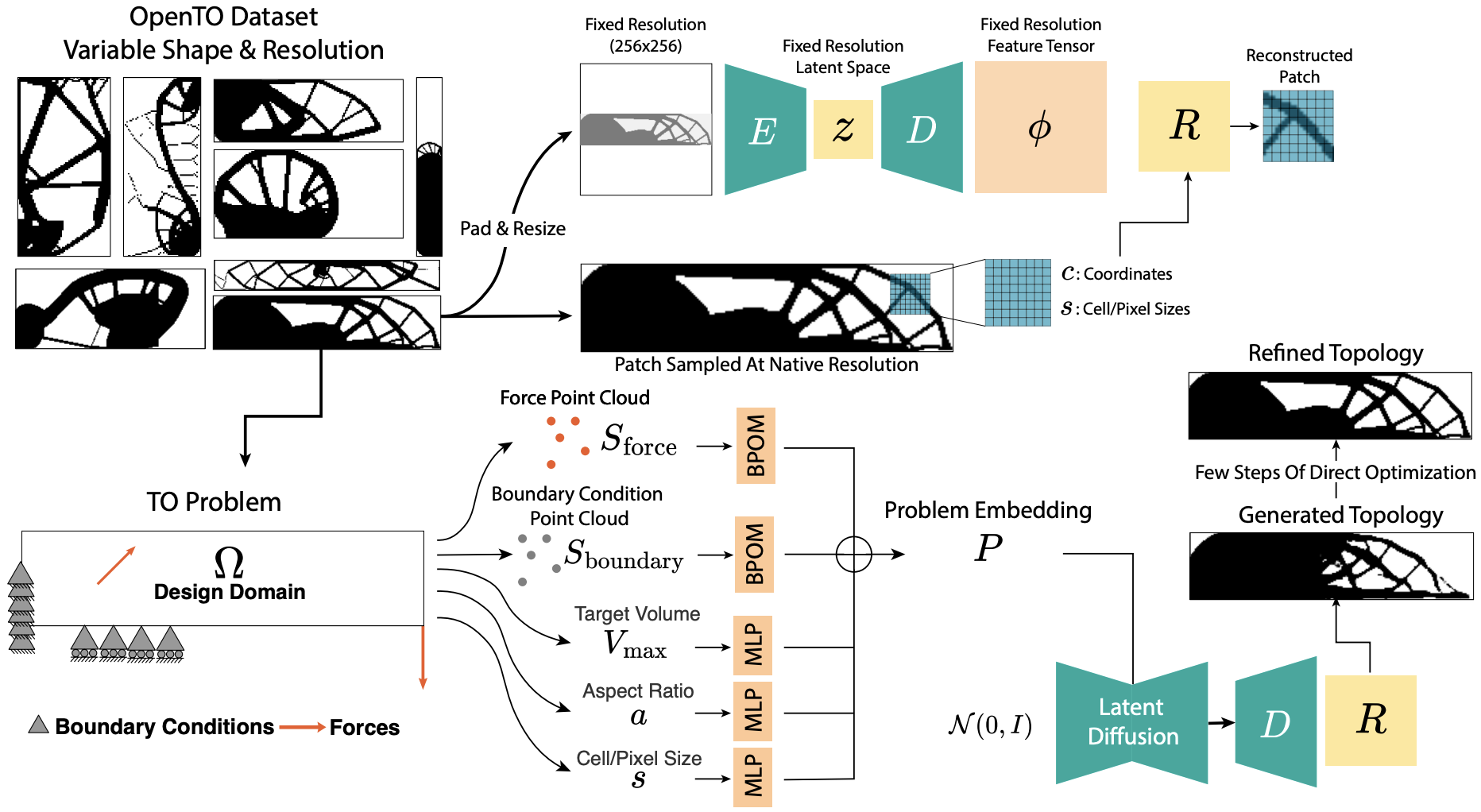
Structural topology optimization (TO) is central to engineering design but remains computationally intensive due to complex physics and hard constraints. Existing deep-learning methods are limited to fixed square grids, a few hand-coded boundary conditions, and post-hoc optimization, preventing general deployment. We introduce Optimize Any Topology (OAT), a foundation-model framework that directly predicts minimum-compliance layouts for arbitrary aspect ratios, resolutions, volume fractions, loads, and fixtures. OAT combines a resolution- and shape-agnostic autoencoder with an implicit neural-field decoder and a conditional latent-diffusion model trained on OpenTO, a new corpus of 2.2 million optimized structures covering 2 million unique boundary-condition configurations. On four public benchmarks and two challenging unseen tests, OAT lowers mean compliance up to 90% relative to the best prior models and delivers sub-1 second inference on a single GPU across resolutions from 64 x 64 to 256 x 256 and aspect ratios as high as 10:1. These results establish OAT as a general, fast, and resolution-free framework for physics-aware topology optimization and provide a large-scale dataset to spur further research in generative modeling for inverse design.
In NeurIPS 2025
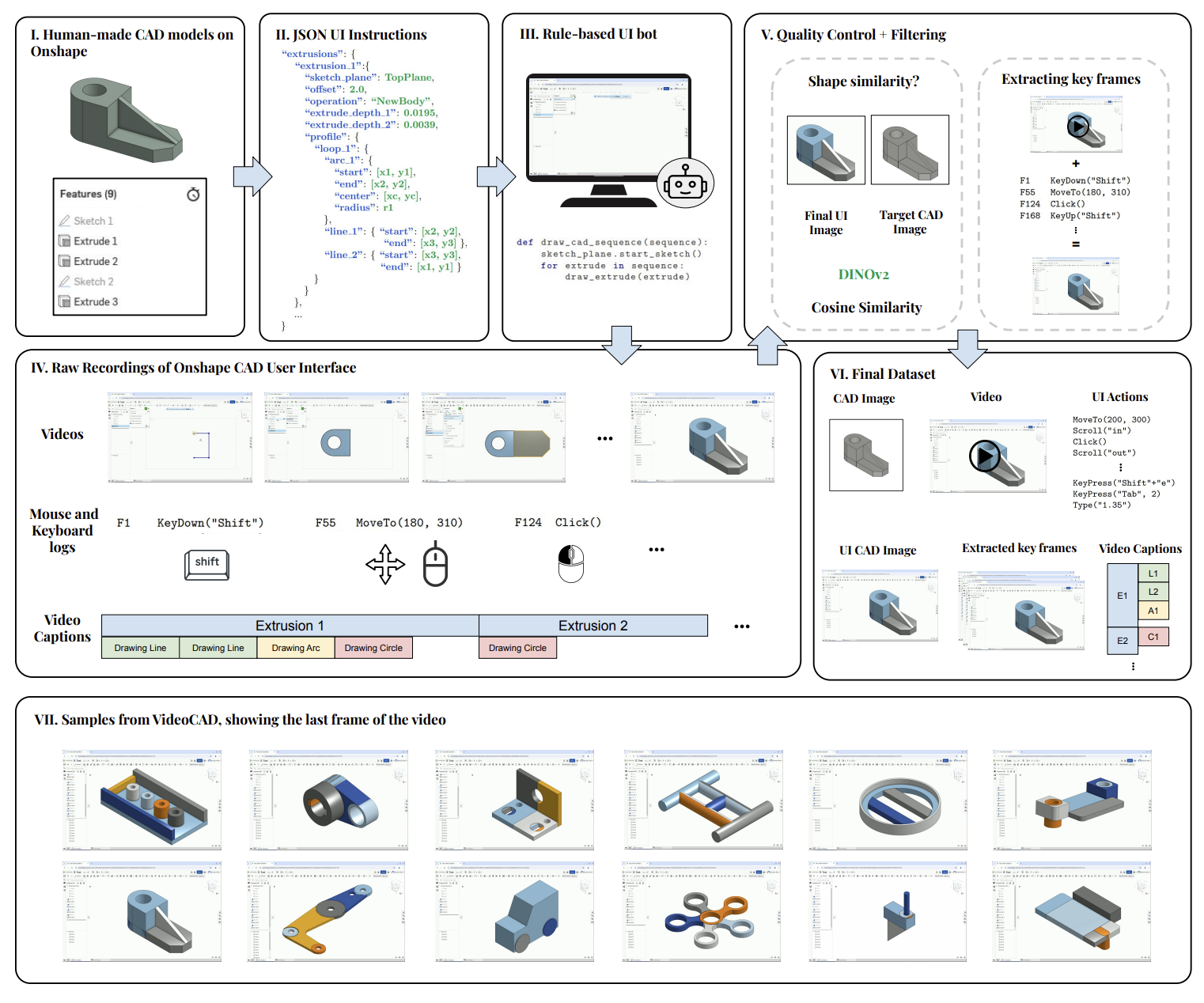
Computer-Aided Design (CAD) is a time-consuming and complex process, requiring precise, long-horizon user interactions with intricate 3D interfaces. While recent advances in AI-driven user interface (UI) agents show promise, most existing datasets and methods focus on short, low-complexity tasks in mobile or web applications, failing to capture the demands of professional engineering tools. In this work, we introduce VideoCAD, the first attempt at engineering UI interaction learning for precision tasks. Specifically, VideoCAD is a large-scale synthetic dataset consisting of over 41K annotated video recordings of CAD operations, generated using an automated framework for collecting high-fidelity UI action data from human-made CAD designs. Compared to existing datasets, VideoCAD offers an order of magnitude higher complexity in UI interaction learning for real-world engineering tasks, having up to a 20x longer time horizon than other datasets. We show two important downstream applications of VideoCAD: learning UI interactions from professional precision 3D CAD tools and a visual question-answering (VQA) benchmark designed to evaluate multimodal large language models' (LLM) spatial reasoning and video understanding abilities. To learn the UI interactions, we propose VideoCADFormer - a state-of-the-art model in learning CAD interactions directly from video, which outperforms multiple behavior cloning baselines. Both VideoCADFormer and the VQA benchmark derived from VideoCAD reveal key challenges in the current state of video-based UI understanding, including the need for precise action grounding, multi-modal and spatial reasoning, and long-horizon dependencies.
In NeurIPS 2025
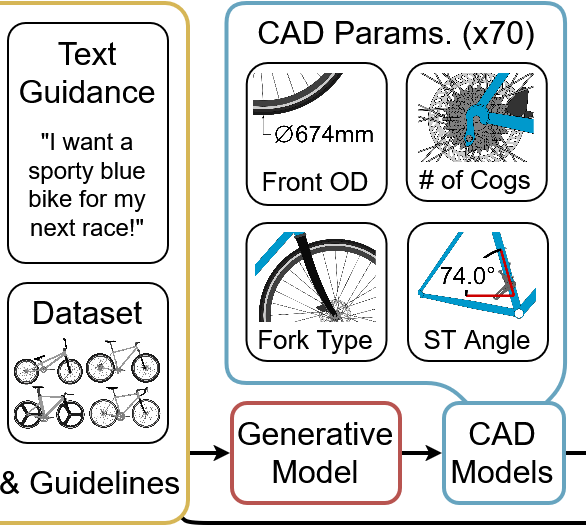
We introduce Bike-Bench, an engineering design benchmark for evaluating generative models on problems with multiple real-world objectives and constraints. As generative AI's reach continues to grow, evaluating its capability to understand physical laws, human guidelines, and hard constraints grows increasingly important. Engineering product design lies at the intersection of these difficult tasks, providing new challenges for AI capabilities. Bike-Bench evaluates AI models' capability to generate designs that not only resemble the dataset, but meet specific performance objectives and constraints. To do so, Bike-Bench quantifies a variety of human-centered and multiphysics performance characteristics, such as aerodynamics, ergonomics, structural mechanics, human-rated usability, and similarity to subjective text or image prompts. Supporting the benchmark are several datasets of simulation results, a dataset of 10K human-rated bicycle assessments, and a synthetically-generated dataset of 1.4M designs, each with a parametric, CAD/XML, SVG, and PNG representation. Bike-Bench is uniquely configured to evaluate tabular generative models, LLMs, design optimization, and hybrid algorithms side-by-side. Our experiments indicate that LLMs and tabular generative models fall short of optimization and optimization-augmented generative models in both validity and optimality scores, suggesting significant room for improvement. We hope Bike-Bench, a first-of-its-kind benchmark, will help catalyze progress in generative AI for constrained multi-objective engineering design problems.
Under Review
Despite progress in machine learning based aerodynamic surrogates, the scarcity of large, field-resolved datasets limits progress on accurate pointwise prediction and reproducible inverse design for aircraft. We introduce BlendedNet++, a large-scale aerodynamic dataset and benchmark focused on blended wing body (BWB) aircraft. The dataset contains over 12,000 unique geometries, each simulated at a single flight condition, yielding 12,490 aerodynamic results for steady RANS CFD. For every case, we provide (i) integrated force/moment coefficients CL, CD, CM and (ii) dense surface fields of pressure and skin friction coefficients - Cp and (Cfx, Cfy, Cfz). Using this dataset, we standardize a forward-surrogate benchmark to predict pointwise fields across six model families: GraphSAGE, GraphUNet, PointNet, a coordinate Transformer (Transolver-style), a FiLMNet (coordinate MLP with feature-wise modulation), and a Graph Neural Operator Transformer (GNOT). Finally, we present an inverse design task of achieving a specified lift-to-drag ratio under fixed flight conditions, implemented via a conditional diffusion model. To assess performance, we benchmark this approach against gradient-based optimization on the same surrogate and a diffusion-optimization hybrid that first samples with the conditional diffusion model and then further optimizes the designs. BlendedNet++ provides a unified forward and inverse protocol with multi-model baselines, enabling fair, reproducible comparison across architectures and optimization paradigms. We expect BlendedNet++ to catalyze reproducible research in field-level aerodynamics and inverse design; resources (dataset, splits, baselines, and scripts) will be released upon acceptance.

In Physics of Fluids 37(12), 2025
The computational cost of traditional Computational Fluid Dynamics (CFD)-based Aerodynamic Shape Optimization severely restricts design space exploration. This paper introduces TripOptimizer, a fully differentiable deep learning framework for rapid aerodynamic analysis and shape optimization directly from vehicle point cloud data. TripOptimizer integrates a Variational Autoencoder with a triplane-based implicit neural representation for high-fidelity three-dimensional geometry reconstruction and a drag coefficient prediction head. Trained on DrivAerNet++, a large-scale dataset of 8000 unique vehicle geometries with corresponding drag coefficients computed via Reynolds-Averaged Navier-Stokes simulations, the model learns a latent representation that encodes aerodynamically salient geometric features. The framework's primary contribution is a novel optimization strategy that modifies a subset of the encoder parameters to steer an initial geometry toward a target drag value, and we demonstrate its efficacy in case studies where optimized designs achieved drag coefficient reductions up to 11.8%. These results were subsequently validated using independent, high-fidelity Computational Fluid Dynamics simulations with more than 150 x 10^6 cells. A key advantage of the implicit representation is its inherent robustness to geometric imperfections, enabling optimization of non-watertight meshes, a significant challenge for traditional adjoint-based methods. The framework enables a more agile Aerodynamic Shape Optimization workflow, reducing reliance on computationally intensive CFD simulations, especially during early design stages.
Under Review
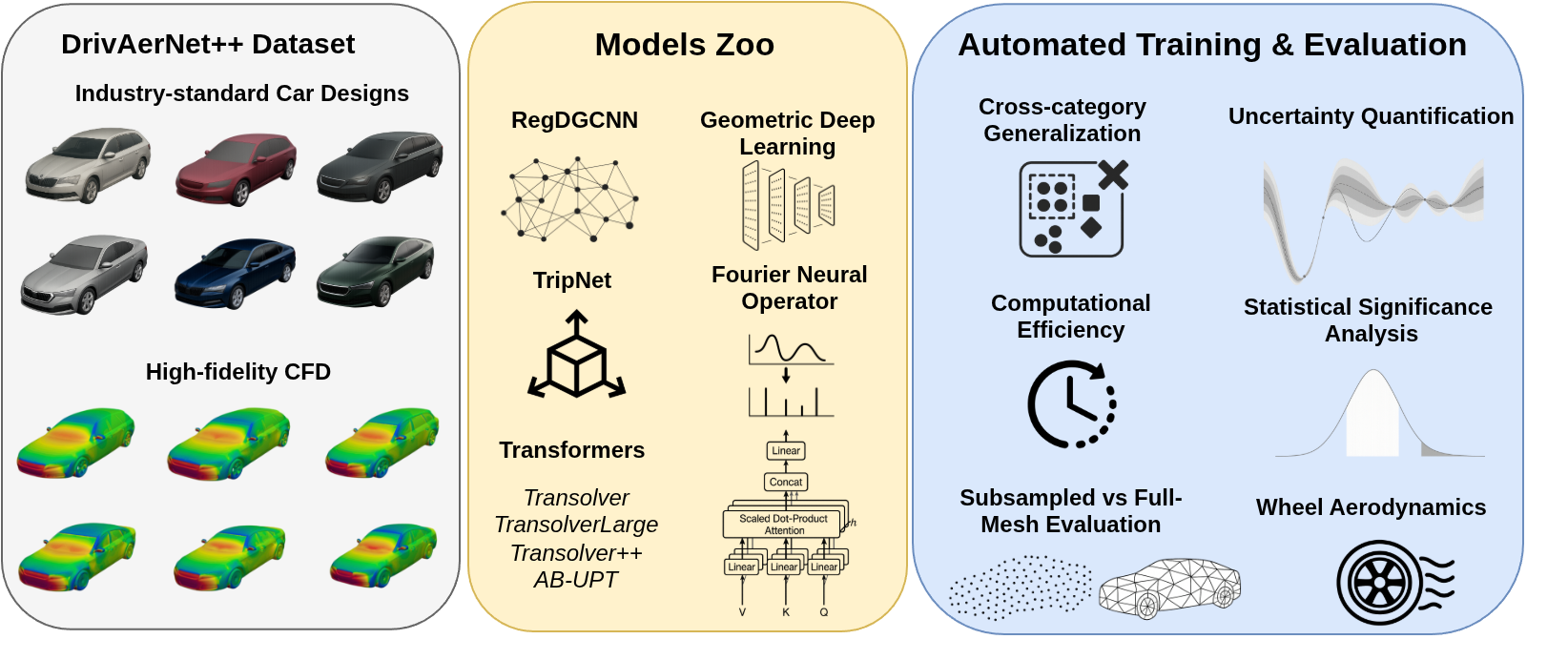
Benchmarking has been the cornerstone of progress in computer vision, natural language processing, and the broader deep learning domain, driving algorithmic innovation through standardized datasets and reproducible evaluation protocols. The growing availability of large-scale Computational Fluid Dynamics (CFD) datasets has opened new opportunities for applying machine learning to aerodynamic and engineering design. Yet, despite this progress, there exists no standardized benchmark for large-scale numerical simulations in engineering design. In this work, we introduce CarBench, the first comprehensive benchmark dedicated to large-scale 3D car aerodynamics, performing a large-scale evaluation of state-of-the-art models on DrivAerNet++, the largest public dataset for automotive aerodynamics, containing over 8,000 high-fidelity car simulations. We assess eleven architectures spanning neural operator methods (e.g., Fourier Neural Operator), geometric deep learning (PointNet, RegDGCNN, PointMAE, PointTransformer), transformer-based neural solvers (Transolver, Transolver++, AB-UPT), and implicit field networks (TripNet). Beyond standard interpolation tasks, we perform cross-category experiments in which transformer-based solvers trained on a single car archetype are evaluated on unseen categories. Our analysis covers predictive accuracy, physical consistency, computational efficiency, and statistical uncertainty. To accelerate progress in data-driven engineering, we open-source the benchmark framework, including training pipelines, uncertainty estimation routines based on bootstrap resampling, and pretrained model weights, establishing the first reproducible foundation for large-scale learning from high-fidelity CFD simulations.
Under Review
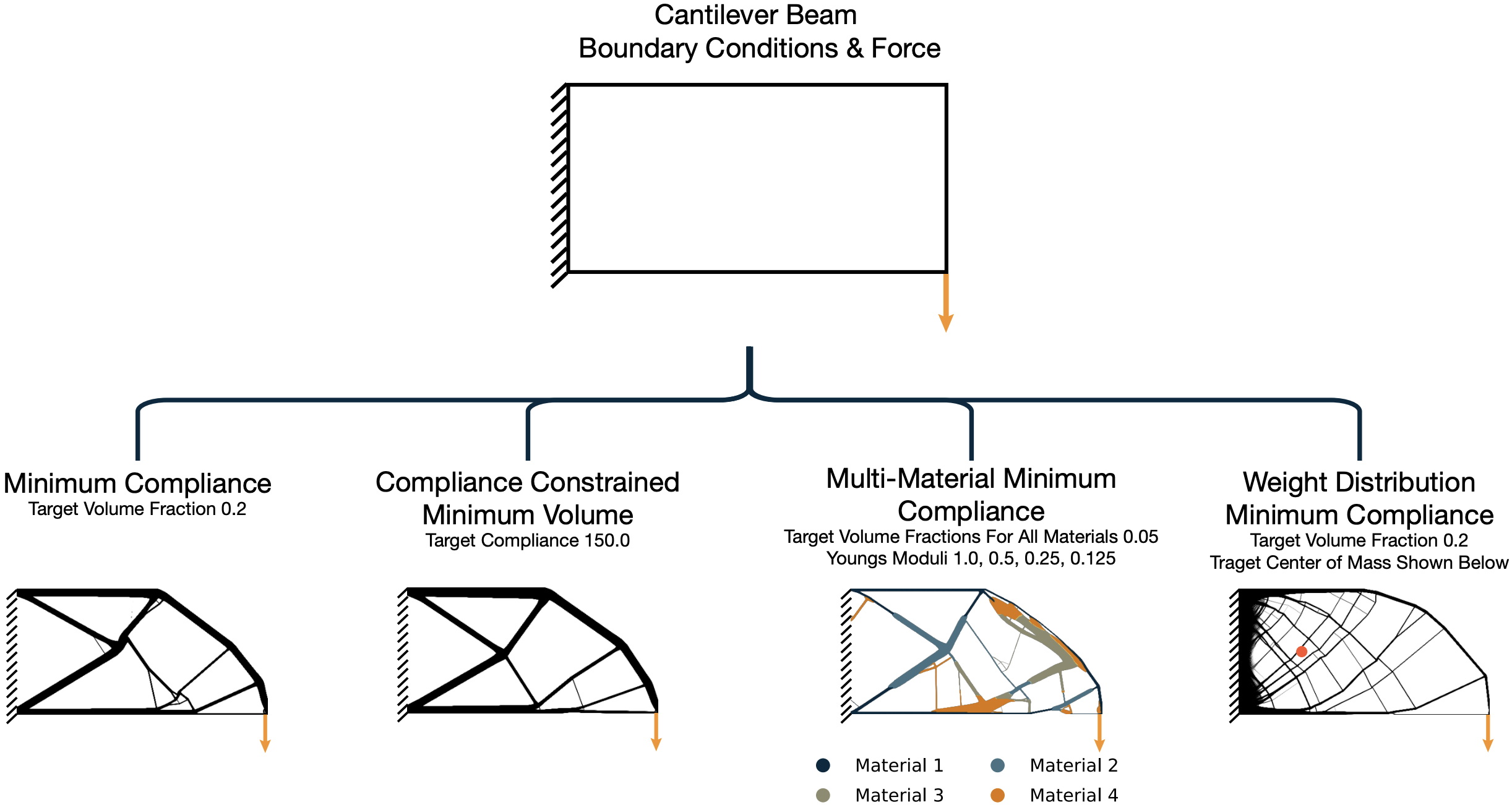
Projected Gradient Descent (PGD) methods offer a simple and scalable approach to topology optimization (TO), yet they often struggle with nonlinear and multi-constraint problems due to the complexity of active-set detection. This paper introduces PGD-TO, a framework that reformulates the projection step into a regularized convex quadratic problem, eliminating the need for active-set search and ensuring well-posedness even when constraints are infeasible. The framework employs a semismooth Newton solver for general multi-constraint cases and a binary search projection for single or independent constraints, achieving fast and reliable convergence. It further integrates spectral step-size adaptation and nonlinear conjugate-gradient directions for improved stability and efficiency. We evaluate PGD-TO on four benchmark families representing the breadth of TO problems: (i) minimum compliance with a linear volume constraint, (ii) minimum volume under a nonlinear compliance constraint, (iii) multi-material minimum compliance with four independent volume constraints, and (iv) minimum compliance with coupled volume and center-of-mass constraints. Across these single- and multi-constraint, linear and nonlinear cases, PGD-TO achieves convergence and final compliance comparable to the Method of Moving Asymptotes (MMA) and Optimality Criteria (OC), while reducing per-iteration computation time by 10–43x on general problems and 115–312x when constraints are independent. Overall, PGD-TO establishes a fast, robust, and scalable alternative to MMA, advancing topology optimization toward practical large-scale, multi-constraint, and nonlinear design problems. Public code available at: https://github.com/ahnobari/pyFANTOM.

In IDETC 2025
BlendedNet is a publicly available aerodynamic dataset of 999 blended wing body (BWB) geometries. Each geometry is simulated across about nine flight conditions, yielding 8830 converged RANS cases with the Spalart-Allmaras model and 9 to 14 million cells per case. The dataset is generated by sampling geometric design parameters and flight conditions, and includes detailed pointwise surface quantities needed to study lift and drag. We also introduce an end-to-end surrogate framework for pointwise aerodynamic prediction. The pipeline first uses a permutation-invariant PointNet regressor to predict geometric parameters from sampled surface point clouds, then conditions a Feature-wise Linear Modulation (FiLM) network on the predicted parameters and flight conditions to predict pointwise coefficients Cp, Cfx, and Cfz. Experiments show low errors in surface predictions across diverse BWBs. BlendedNet addresses data scarcity for unconventional configurations and enables research on data-driven surrogate modeling for aerodynamic design.
In IDETC 2025
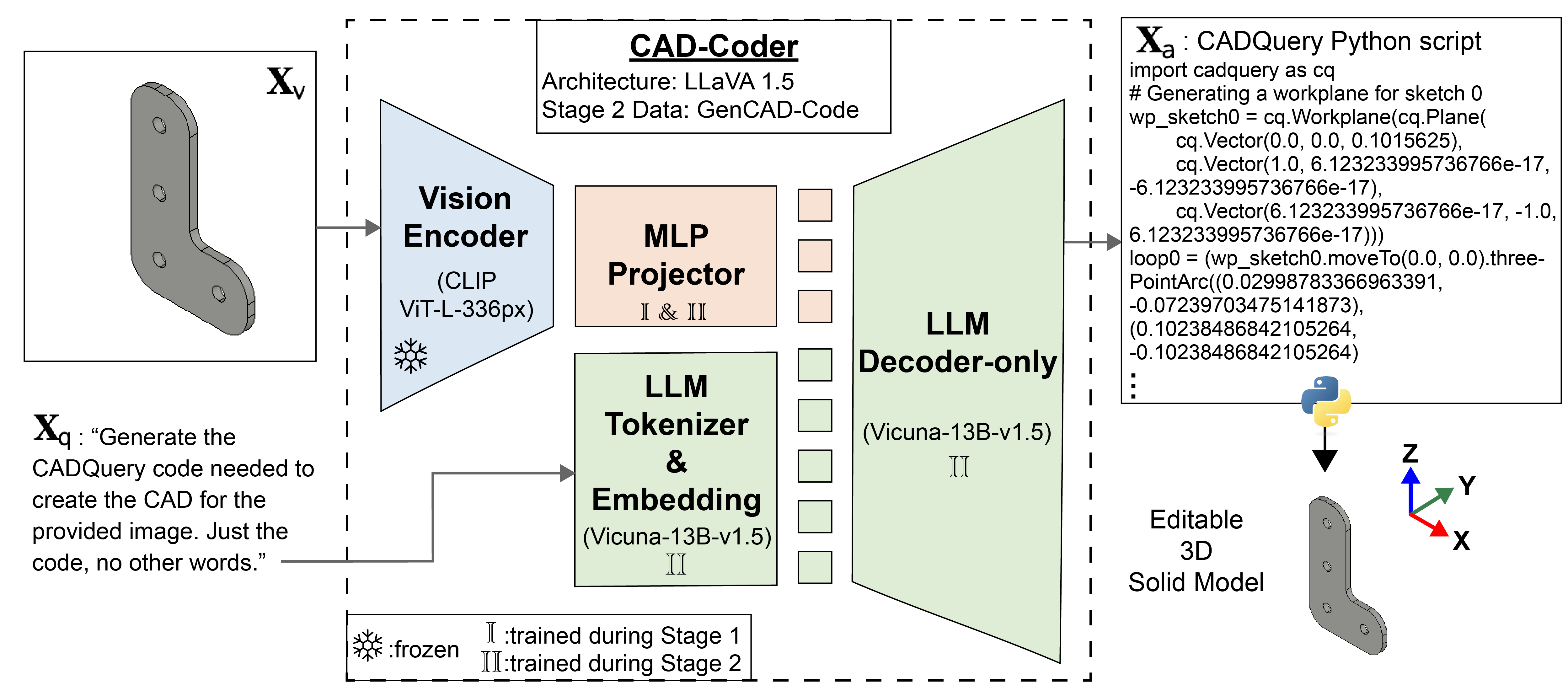
Efficient creation of accurate and editable 3D CAD models is critical in engineering design, significantly impacting cost and time-to-market in product innovation. Current manual workflows remain highly time-consuming and demand extensive user expertise. While recent developments in AI-driven CAD generation show promise, existing models are limited by incomplete representations of CAD operations, inability to generalize to real-world images, and low output accuracy. This paper introduces CAD-Coder, an open-source Vision-Language Model (VLM) explicitly fine-tuned to generate editable CAD code (CadQuery Python) directly from visual input. Leveraging a novel dataset that we created--GenCAD-Code, consisting of over 163k CAD-model image and code pairs--CAD-Coder outperforms state-of-the-art VLM baselines such as GPT-4.5 and Qwen2.5-VL-72B, achieving a 100% valid syntax rate and the highest accuracy in 3D solid similarity. Notably, our VLM demonstrates some signs of generalizability, successfully generating CAD code from real-world images and executing CAD operations unseen during fine-tuning. The performance and adaptability of CAD-Coder highlights the potential of VLMs fine-tuned on code to streamline CAD workflows for engineers and designers.

In Journal of Mechanical Design 2026
CAD programs, structured as parametric sequences of commands that compile into precise 3D geometries, are fundamental to accurate and efficient engineering design processes. Generating these programs from nonparametric data such as point clouds and meshes remains a crucial yet challenging task, typically requiring extensive manual intervention. Current deep generative models aimed at automating CAD generation are significantly limited by imbalanced and insufficiently large datasets, particularly those lacking representation for complex CAD programs. To address this, we introduce GenCAD-3D, a multimodal generative framework utilizing contrastive learning for aligning latent embeddings between CAD and geometric encoders, combined with latent diffusion models for CAD sequence generation and retrieval. Additionally, we present SynthBal, a synthetic data augmentation strategy specifically designed to balance and expand datasets, notably enhancing representation of complex CAD geometries. Our experiments show that SynthBal significantly boosts reconstruction accuracy, reduces the generation of invalid CAD models, and markedly improves performance on high-complexity geometries, surpassing existing benchmarks. These advancements hold substantial implications for streamlining reverse engineering and enhancing automation in engineering design.

In Journal of Mechanical Design 2026
Guest editorial introducing the JMD special issue on design datasets. It highlights the role of data‑driven methods in engineering design, identifies challenges in creating and sharing multi‑modal, high‑quality datasets, and outlines recommendations and a vision for dataset standards and reuse.
arXiv preprint arXiv:2510.22491
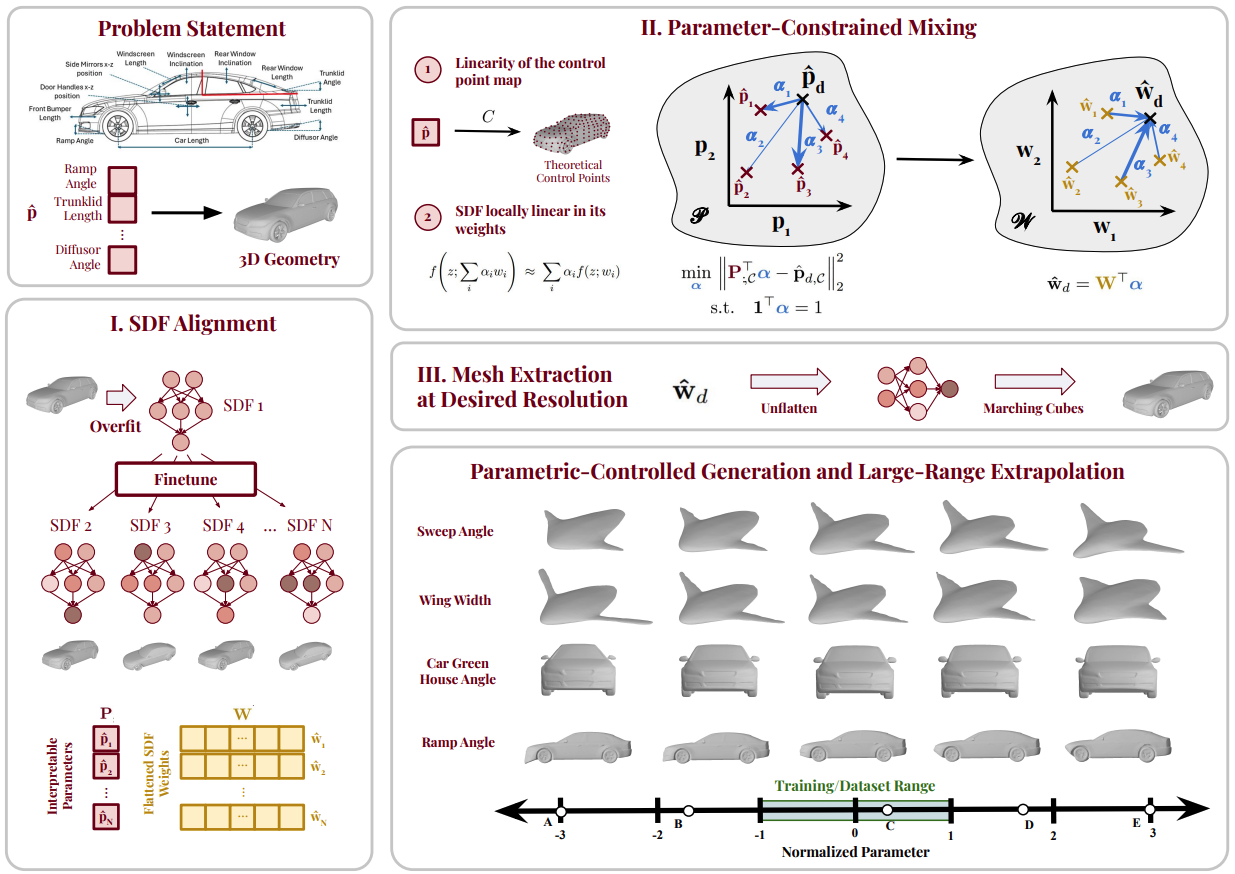
Generating high-fidelity 3D geometries that satisfy specific parameter constraints has broad applications in design and engineering. However, current methods typically rely on large training datasets and struggle with controllability and generalization beyond the training distributions. To overcome these limitations, we introduce LAMP (Linear Affine Mixing of Parametric shapes), a data-efficient framework for controllable and interpretable 3D generation. LAMP first aligns signed distance function (SDF) decoders by overfitting each exemplar from a shared initialization, then synthesizes new geometries by solving a parameter-constrained mixing problem in the aligned weight space. To ensure robustness, we further propose a safety metric that detects geometry validity via linearity mismatch. We evaluate LAMP on two 3D parametric benchmarks: DrivAerNet++ and BlendedNet. We found that LAMP enables (i) controlled interpolation within bounds with as few as 100 samples, (ii) safe extrapolation by up to 100% parameter difference beyond training ranges, and (iii) physics performance-guided optimization under fixed parameters. LAMP significantly outperforms conditional autoencoder and Deep Network Interpolation (DNI) baselines in both extrapolation and data efficiency. Our results demonstrate that LAMP advances controllable, data-efficient, and safe 3D generation for design exploration, dataset generation, and performance-driven optimization.

In Journal of Mechanical Design 2025
This article introduces a generative model designed for multimodal control over text-to-image foundation generative artificial intelligence (AI) models such as Stable Diffusion, specifically tailored for engineering design synthesis. Our model proposes parametric, image, and text control modalities to enhance design precision and diversity. First, it handles both partial and complete parametric inputs using a diffusion model that acts as a design autocomplete copilot, coupled with a parametric encoder to process the information. Second, the model utilizes assembly graphs to systematically assemble input component images, which are then processed through a component encoder to capture essential visual data. Third, textual descriptions are integrated via CLIP encoding, ensuring a comprehensive interpretation of design intent. These diverse inputs are synthesized through a multimodal fusion technique, creating a joint embedding that acts as the input to a module inspired by ControlNet. This integration allows the model to apply robust multimodal control to foundation models, facilitating the generation of complex and precise engineering designs. This approach broadens the capabilities of AI-driven design tools and demonstrates significant advancements in precise control based on diverse data modalities for enhanced design generation.
In IDETC 2025
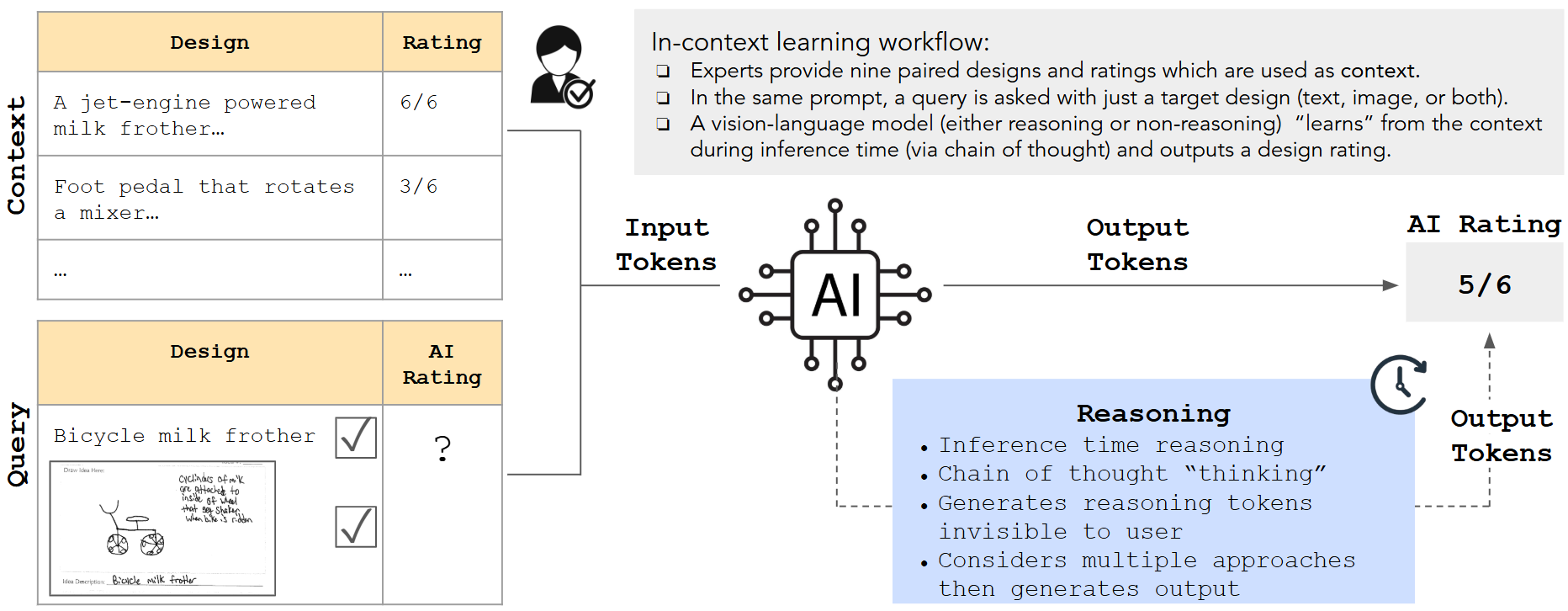
The subjective evaluation of early stage engineering designs, such as conceptual sketches, traditionally relies on human experts. However, expert evaluations are time-consuming, expensive, and sometimes inconsistent. Recent advances in vision-language models (VLMs) offer the potential to automate design assessments, but it is crucial to ensure that these AI ``judges'' perform on par with human experts. However, no existing framework assesses expert equivalence. This paper introduces a rigorous statistical framework to determine whether an AI judge's ratings match those of human experts. We apply this framework in a case study evaluating four VLM-based judges on key design metrics (uniqueness, creativity, usefulness, and drawing quality). These AI judges employ various in-context learning (ICL) techniques, including uni- vs. multimodal prompts and inference-time reasoning. The same statistical framework is used to assess three trained novices for expert-equivalence. Results show that the top-performing AI judge, using text- and image-based ICL with reasoning, achieves expert-level agreement for uniqueness and drawing quality and outperforms or matches trained novices across all metrics. In 6/6 runs for both uniqueness and creativity, and 5/6 runs for both drawing quality and usefulness, its agreement with experts meets or exceeds that of the majority of trained novices. These findings suggest that reasoning-supported VLM models can achieve human-expert equivalence in design evaluation. This has implications for scaling design evaluation in education and practice, and provides a general statistical framework for validating AI judges in other domains requiring subjective content evaluation.
In Journal of Computer and Information Science in Engineering 2025
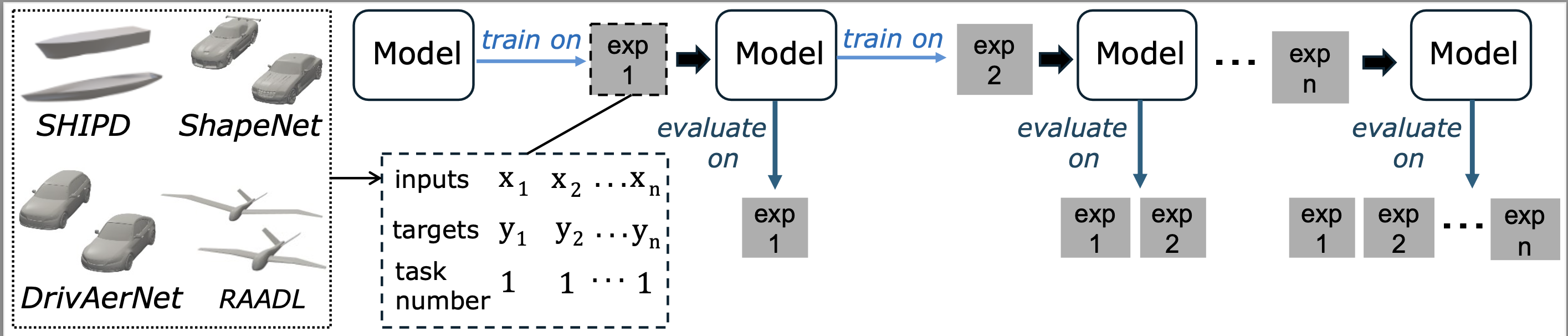
Engineering problems that apply machine learning often involve computationally intensive methods but rely on limited datasets. As engineering data evolve with new designs and constraints, models must incorporate new knowledge over time. However, high computational costs make retraining models from scratch infeasible. Continual learning (CL) offers a promising solution by enabling models to learn from sequential data while mitigating catastrophic forgetting, where a model forgets previously learned mappings. This work introduces CL to engineering design by benchmarking several CL methods on representative regression tasks. We apply these strategies to five engineering datasets and construct nine new engineering CL benchmarks to evaluate their ability to address forgetting and improve generalization. Preliminary results show that applying existing CL methods to these tasks improves performance over naive fine-tuning. In particular, the replay strategy achieved performance comparable to retraining in several benchmarks while reducing training time by nearly half, demonstrating its potential for real-world engineering workflows.

In Journal of Mechanical Design 2025
This study introduces DrivAerNet, a large-scale high-fidelity CFD dataset of 3D industry-standard car shapes, and RegDGCNN, a dynamic graph convolutional neural network model for regression, both aimed at aerodynamic car design through machine learning. DrivAerNet, with its 4000 detailed 3D car meshes using 0.5 million surface mesh faces and comprehensive aerodynamic performance data comprising of full 3D pressure, velocity fields, and wall-shear stresses, addresses the critical need for extensive datasets to train deep learning models in engineering applications. It is 60% larger than the previously available largest public dataset of cars and is the only open-source dataset that also models wheels and underbody. RegDGCNN leverages this large-scale dataset to provide high-precision drag estimates directly from 3D meshes, bypassing traditional limitations such as the need for 2D image rendering or signed distance fields (SDFs). By enabling fast drag estimation in seconds, RegDGCNN facilitates rapid aerodynamic assessments, offering a substantial leap toward integrating data-driven methods in automotive design. Together, DrivAerNet and RegDGCNN promise to accelerate the car design process and contribute to the development of more efficient cars. To lay the groundwork for future innovations in the field, the dataset and code used in our study are publicly accessible.
Under Review
The field of engineering is shaped by the tools and methods used to solve problems. Optimization is one such class of powerful, robust, and effective engineering tools proven over decades of use. Within just a few years, generative artificial intelligence (GenAI) has risen as another promising tool for general-purpose problem-solving. While optimization shines at finding high-quality and precise solutions that satisfy constraints, GenAI excels at inferring problem requirements, bridging solution domains, handling mixed data modalities, and rapidly generating copious numbers of solutions. These differing attributes also make the two frameworks complementary. Hybrid generative optimization algorithms present a new paradigm for engineering problem-solving and have shown promise across a few engineering applications. We expect significant developments in the near future around generative optimization, leading to changes in how engineers solve problems using computational tools. We offer our perspective on existing methods, areas of promise, and key research questions.
In Applied Energy 2025
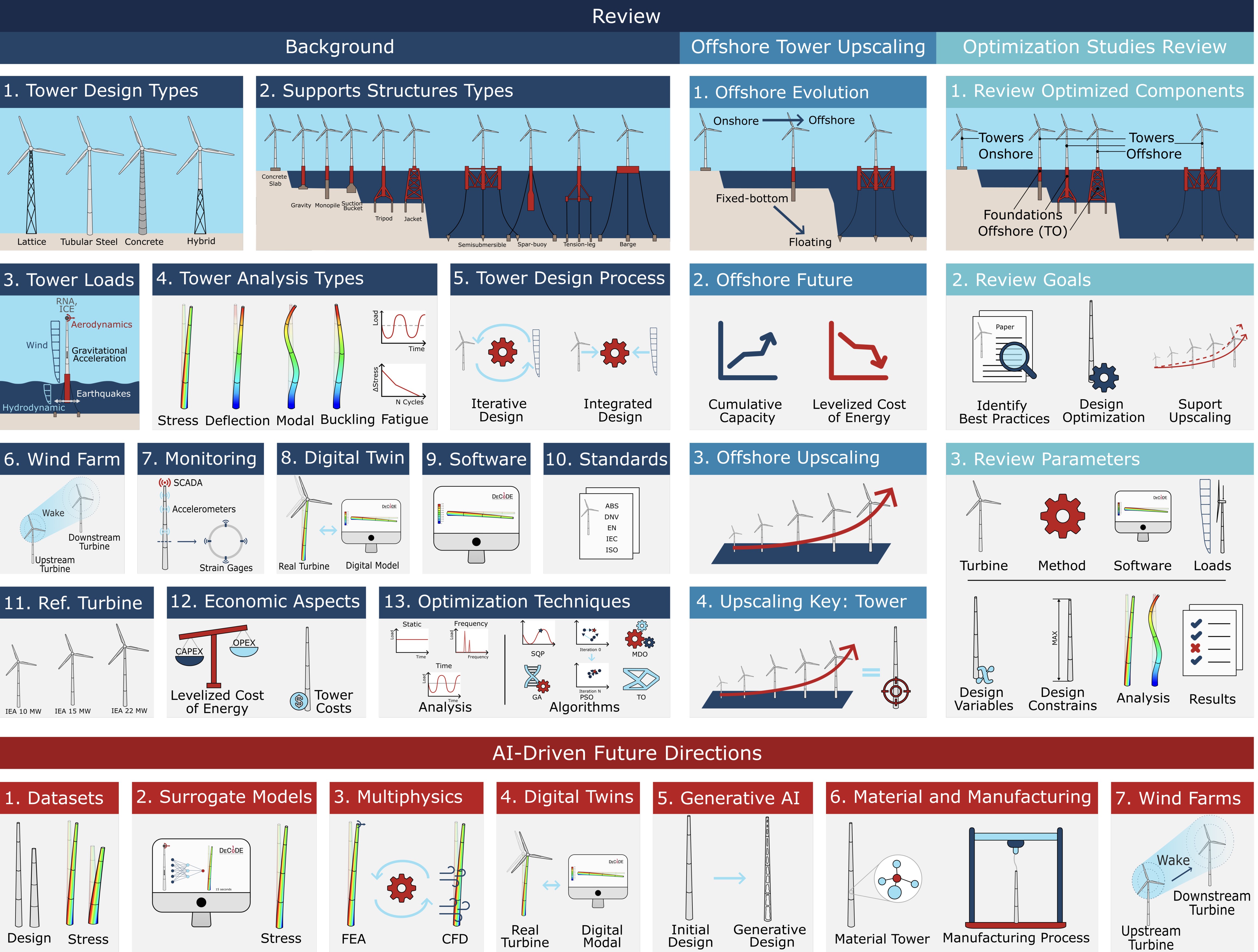
Offshore wind energy leverages the high intensity and consistency of oceanic winds, playing a key role in the transition to renewable energy. As energy demands grow, larger turbines are required to optimize power generation and reduce the Levelized Cost of Energy (LCoE), which represents the average cost of electricity over a project’s lifetime. However, upscaling turbines introduces engineering challenges, particularly in the design of supporting structures, especially towers. These towers must support increased loads while maintaining structural integrity, cost-efficiency, and transportability, making them essential to offshore wind projects’ success. This paper presents a comprehensive review of the latest advancements, challenges, and future directions driven by Artificial Intelligence (AI) in the design optimization of Offshore Wind Turbine (OWT) structures, with a focus on towers. It provides an in-depth background on key areas such as design types, load types, analysis methods, design processes, monitoring systems, Digital Twin (DT), software, standards, reference turbines, economic factors, and optimization techniques. Additionally, it includes a state-of-the-art review of optimization studies related to tower design optimization, presenting a detailed examination of turbine, software, loads, optimization method, design variables and constraints, analysis, and findings, motivating future research to refine design approaches for effective turbine upscaling and improved efficiency. Lastly, the paper explores future directions where AI can revolutionize tower design optimization, enabling the development of efficient, scalable, and sustainable structures. By addressing the upscaling challenges and supporting the growth of renewable energy, this work contributes to shaping the future of offshore wind turbine towers and others supporting structures.
In IDETC 2025
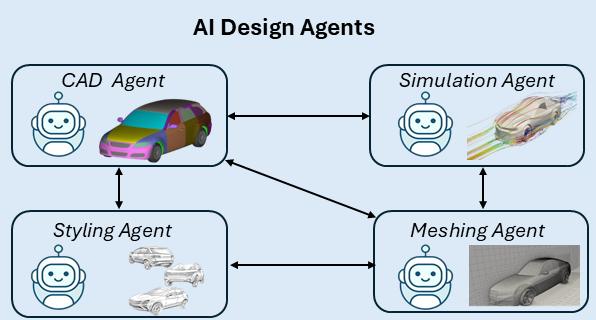
We introduce the concept of 'Design Agents' for engineering applications, particularly focusing on the automotive design process, while emphasizing that our approach can be readily extended to other engineering and design domains. Our framework integrates AI-driven design agents into the traditional engineering workflow, demonstrating how these specialized computational agents interact seamlessly with engineers and designers to augment creativity, enhance efficiency, and significantly accelerate the overall design cycle. By automating and streamlining tasks traditionally performed manually, such as conceptual sketching, styling enhancements, 3D shape retrieval and generative modeling, computational fluid dynamics (CFD) meshing, and aerodynamic simulations, our approach reduces certain aspects of the conventional workflow from weeks and days down to minutes. These agents leverage state-of-the-art vision-language models (VLMs), large language models (LLMs), and geometric deep learning techniques, providing rapid iteration and comprehensive design exploration capabilities. We ground our methodology in industry-standard benchmarks, encompassing a wide variety of conventional automotive designs, and utilize high-fidelity aerodynamic simulations to ensure practical and applicable outcomes. Furthermore, we present design agents that can swiftly and accurately predict simulation outcomes, empowering engineers and designers to engage in more informed design optimization and exploration. This research underscores the transformative potential of integrating advanced generative AI techniques into complex engineering tasks, paving the way for broader adoption and innovation across multiple engineering disciplines.
In Transactions on Machine Learning Research
Generative models have recently achieved remarkable success and widespread adoption in society, yet they often struggle to generate realistic and accurate outputs. This challenge extends beyond language and vision into fields like engineering design, where safety-critical engineering standards and non-negotiable physical laws tightly constrain what outputs are considered acceptable. In this work, we introduce a novel training method to guide a generative model toward constraint-satisfying outputs using `negative data' -- examples of what to avoid. Our negative-data generative model (NDGM) formulation easily outperforms classic models, generating 1/6 as many constraint-violating samples using 1/8 as much data in certain problems. It also consistently outperforms other baselines, achieving a balance between constraint satisfaction and distributional similarity that is unsurpassed by any other model in 12 of the 14 problems tested. This widespread superiority is rigorously demonstrated across numerous synthetic tests and real engineering problems, such as ship hull synthesis with hydrodynamic constraints and vehicle design with impact safety constraints. Our benchmarks showcase both the best-in-class performance of our new NDGM formulation and the overall dominance of NDGMs versus classic generative models.
In Transactions on Machine Learning Research
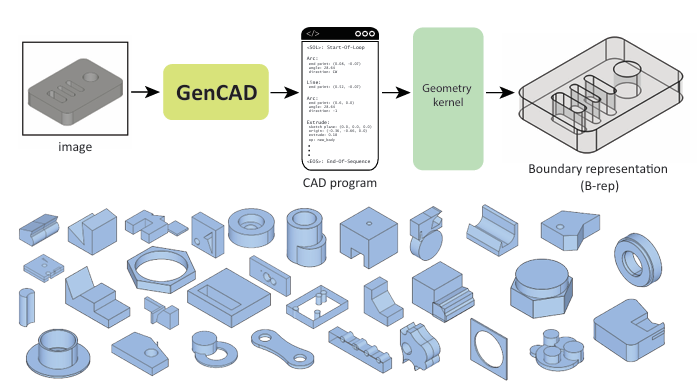
The creation of manufacturable and editable 3D shapes through Computer-Aided Design (CAD) remains a highly manual and time-consuming task, hampered by the complex topology of boundary representations of 3D solids and unintuitive design tools. While most work in the 3D shape generation literature focuses on representations like meshes, voxels, or point clouds, practical engineering applications demand the modifiability and manufacturability of CAD models and the ability for multi-modal conditional CAD model generation. This paper introduces GenCAD, a generative model that employs autoregressive transformers with a contrastive learning framework and latent diffusion models to transform image inputs into parametric CAD command sequences, resulting in editable 3D shape representations. Extensive evaluations demonstrate that GenCAD significantly outperforms existing state-of-the-art methods in terms of the unconditional and conditional generations of CAD models. Additionally, the contrastive learning framework of GenCAD facilitates the retrieval of CAD models using image queries from large CAD databases, which is a critical challenge within the CAD community. Our results provide a significant step forward in highlighting the potential of generative models to expedite the entire design-to-production pipeline and seamlessly integrate different design modalities.
In Journal of Mechanical Design 2025
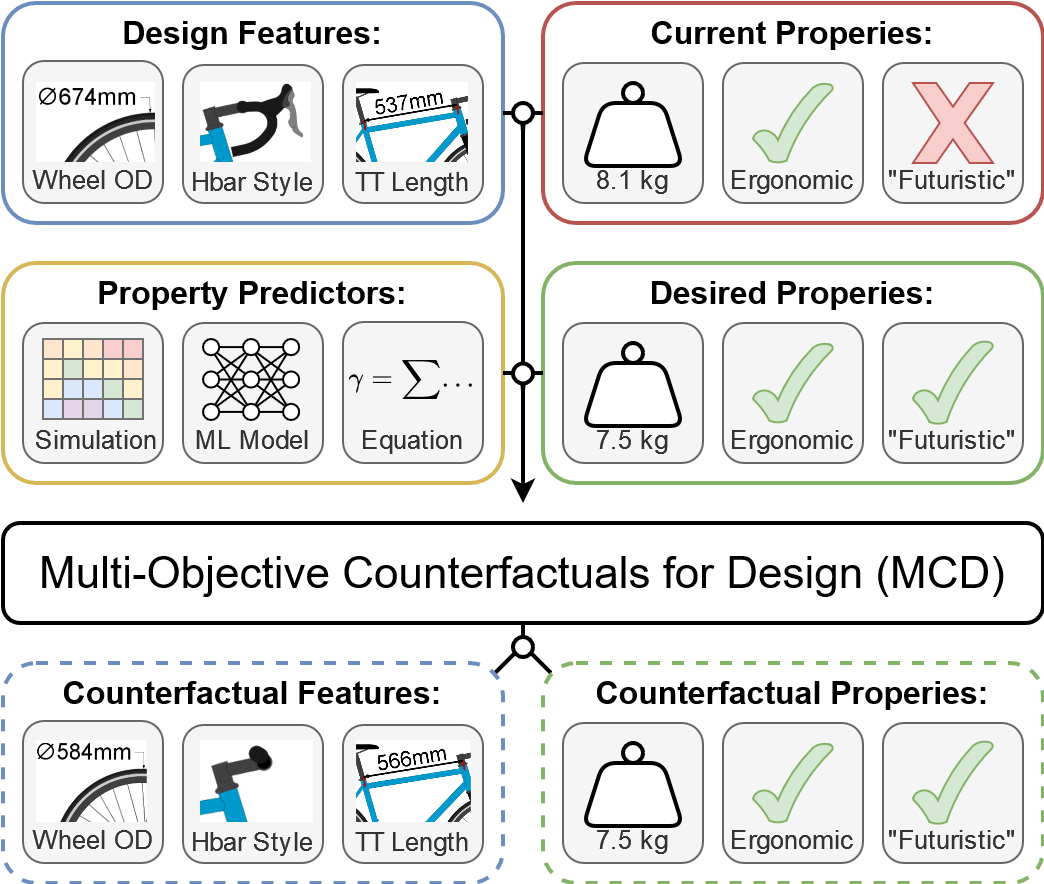
Designers may often ask themselves how to adjust their design concepts to achieve demanding functional goals. To answer such questions, designers must often consider counterfactuals, weighing design alternatives and their projected performance. This paper introduces Multi-objective Counterfactuals for Design (MCD), a computational tool that automates and streamlines the counterfactual search process and recommends targeted design modifications that meet designers' unique requirements. MCD improves upon existing counterfactual search methods by supporting multi-objective requirements, which are crucial in design problems, and by decoupling the counterfactual search and sampling processes, thus enhancing efficiency and facilitating objective trade-off visualization. The paper showcases MCD's capabilities in complex engineering tasks using three demonstrative bicycle design challenges. In the first, MCD effectively identifies design modifications that quantifiably enhance functional performance, strengthening the bike frame and saving weight. In the second, MCD modifies parametric bike models in a cross-modal fashion to resemble subjective text prompts or reference images. In a final multidisciplinary case study, MCD tackles all the quantitative and subjective design requirements introduced in the first two problems, while simultaneously customizing a bike design to an individual rider's biomechanical attributes. By exploring hypothetical design alterations and their impact on multiple design objectives, MCD recommends effective design modifications for practitioners seeking to make targeted enhancements to their designs.

In Journal of Computing and Information Science in Engineering 25(2), 2025
This research introduces DesignQA, a novel benchmark aimed at evaluating the proficiency of multimodal large language models (MLLMs) in comprehending and applying engineering requirements in technical documentation. Developed with a focus on real-world engineering challenges, DesignQA uniquely combines multimodal data-including textual design requirements, CAD images, and engineering drawings-derived from the Formula SAE student competition. Different from many existing MLLM benchmarks, DesignQA contains document-grounded visual questions where the input image and input document come from different sources. The benchmark features automatic evaluation metrics and is divided into segments-Rule Comprehension, Rule Compliance, and Rule Extraction-based on tasks that engineers perform when designing according to requirements. We evaluate state-of-the-art models like GPT4 and LLaVA against the benchmark, and our study uncovers the existing gaps in MLLMs' abilities to interpret complex engineering documentation. Key findings suggest that while MLLMs demonstrate potential in navigating technical documents, substantial limitations exist, particularly in accurately extracting and applying detailed requirements to engineering designs. This benchmark sets a foundation for future advancements in AI-supported engineering design processes. DesignQA is publicly available at: https://github.com/anniedoris/design_qa/.

In Transactions on Machine Learning Research
Topology optimization is a critical task in engineering design, where the goal is to optimally distribute material in a given space for maximum performance. We introduce Neural Implicit Topology Optimization (NITO), a novel approach to accelerate topology optimization problems using deep learning. NITO stands out as one of the first frameworks to offer a resolution-free and domain-agnostic solution in deep learning-based topology optimization. NITO synthesizes structures with up to seven times better structural efficiency compared to SOTA diffusion models and does so in a tenth of the time. In the NITO framework, we introduce a novel method, the Boundary Point Order-Invariant MLP (BPOM), to represent boundary conditions in a sparse and domain-agnostic manner, moving away from expensive simulation-based approaches. Crucially, NITO circumvents the domain and resolution limitations that restrict Convolutional Neural Network (CNN) models to a structured domain of fixed size -- limitations that hinder the widespread adoption of CNNs in engineering applications. This generalizability allows a single NITO model to train and generate solutions in countless domains, eliminating the need for numerous domain-specific CNNs and their extensive datasets. Despite its generalizability, NITO outperforms SOTA models even in specialized tasks, is an order of magnitude smaller, and is practically trainable at high resolutions that would be restrictive for CNNs. This combination of versatility, efficiency, and performance underlines NITO's potential to transform the landscape of engineering design optimization problems through implicit fields.

In Structural and Multidisciplinary Optimization
Bayesian Optimization (BO) is a foundational strategy in the field of engineering design optimization for efficiently handling black-box functions with many constraints and expensive evaluations. This paper introduces a fast and accurate BO framework that leverages Pre-trained Transformers for Bayesian Optimization (PFN4sBO) to address constrained optimization problems in engineering. Unlike traditional BO methods that rely heavily on Gaussian Processes (GPs), our approach utilizes Prior-data Fitted Networks (PFNs), a type of pre-trained transformer, to infer constraints and optimal solutions without requiring any iterative retraining. We demonstrate the effectiveness of PFN-based BO through a comprehensive benchmark consisting of fifteen test problems, encompassing synthetic, structural, and engineering design challenges. Our findings reveal that PFN-based BO significantly outperforms Constrained Expected Improvement and Penalty-based GP methods by an order of magnitude in speed while also outperforming them in accuracy in identifying feasible, optimal solutions. This work showcases the potential of integrating machine learning with optimization techniques in solving complex engineering challenges, heralding a significant leap forward for optimization methodologies, opening up the path to using PFN-based BO to solve other challenging problems, such as enabling user-guided interactive BO, adaptive experiment design, or multi-objective design optimization. Additionally, we establish a benchmark for evaluating BO algorithms in engineering design, offering a robust platform for future research and development in the field. This benchmark framework for evaluating new BO algorithms in engineering design will be published at this https URL.
In Dynamic Data Driven Applications Systems (DDDAS) 2024
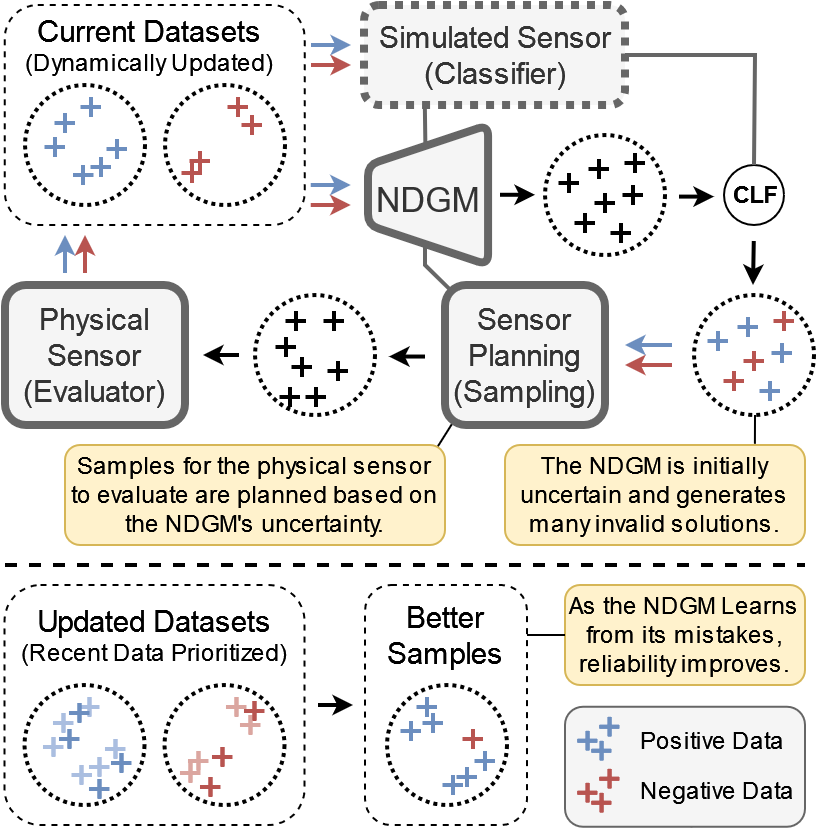
Generative Artificial Intelligence has the potential to transform engineering sectors by enhancing design innovation and automating processes. However, despite advances in their data, training, and architectures, generative models still struggle to effectively and reliably satisfy constraints. This shortcoming presents a significant challenge with their adoption in engineering design tasks, where design constraints are ubiquitous. This difficulty is rooted in the similarity-based training objective of generative AI models, in which they learn to mimic the statistical distribution of a dataset of constraint-satisfying examples (positive data). We assert that generative models can be more effectively trained by examining constraint-violating examples (negative data) in addition to positive data. These “Negative Data Generative Models” (NDGMs) can thereby learn to avoid sampling from constraint-violating regions of the sample space. To demonstrate this principle, we propose a type of NDGM, then benchmark this formulation against vanilla models on two 2D test problems and two engineering design problems related to gearbox and concrete beam design. We showcase that NDGMs achieve significantly (2-30x) better constraint satisfaction compared to vanilla generative models. Moreover, they learn these constraints with only a fraction of the training data compared to vanilla generative models. Since NDGMs require only a handful of example to adjust their learned densities, they are significantly more agile and adaptable than vanilla generative models and may be much more effective in continuous data streams as seen in Dynamic Data-Driven Application Systems (DDDAS). Our findings suggest that NDGMs could play a crucial role in overcoming the constraints satisfaction challenges in current generative models, thereby broadening the scope and applicability of generative AI in critical engineering domains.
Under Review
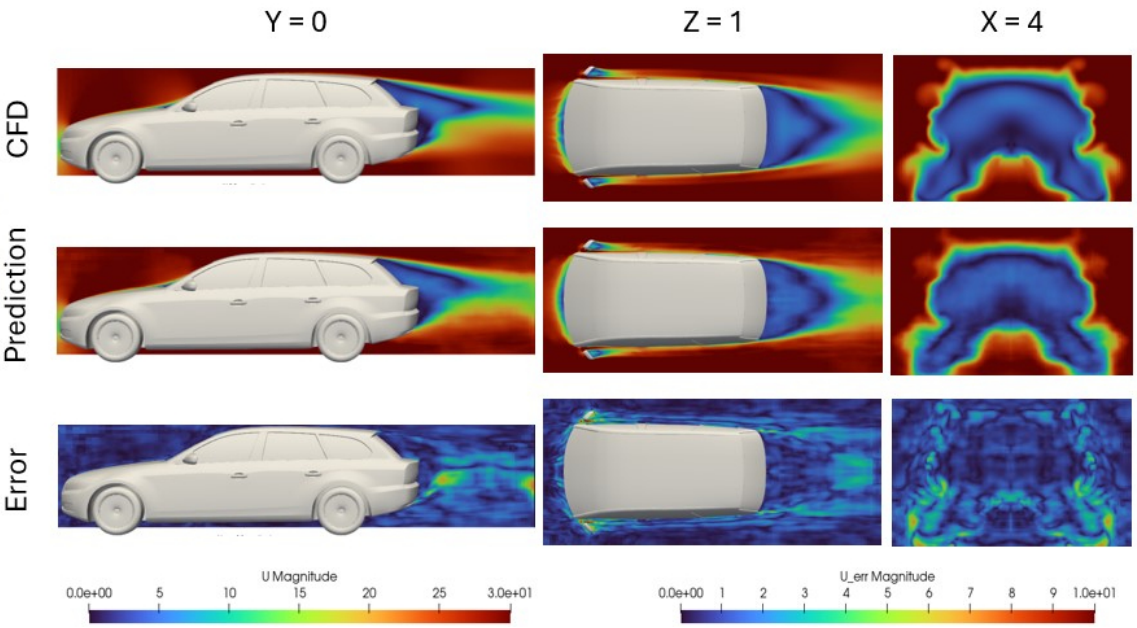
Computational Fluid Dynamics (CFD) simulations are essential in product design, providing insights into fluid behavior around complex geometries in aerospace and automotive applications. However, high-fidelity CFD simulations are computationally expensive, making rapid design iterations challenging. To address this, we propose TripNet, Triplane CFD Network, a machine learning-based framework leveraging triplane representations to predict the outcomes of large-scale, high-fidelity CFD simulations with significantly reduced computation cost. Our method encodes 3D geometry into compact yet information-rich triplane features, maintaining full geometry fidelity and enabling accurate aerodynamic predictions. Unlike graph- and point cloud-based models, which are inherently discrete and provide solutions only at the mesh nodes, TripNet allows the solution to be queried at any point in the 3D space. Validated on high-fidelity DrivAerNet and DrivAerNet++ car aerodynamics datasets, TripNet achieves state-of-the-art performance in drag coefficient prediction, surface field estimation, and full 3D flow field simulations of industry-standard car designs. By utilizing a shared triplane backbone across multiple tasks, our approach offers a scalable, accurate, and efficient alternative to traditional CFD solvers.

In NeurIPS 2024
We present DrivAerNet++, the largest and most comprehensive multimodal dataset for aerodynamic car design. DrivAerNet++ comprises 8,000 diverse car designs modeled with high-fidelity computational fluid dynamics (CFD) simulations. The dataset includes diverse car configurations such as fastback, notchback, and es- tateback, with different underbody and wheel designs to represent both internal combustion engines and electric vehicles. Each entry in the dataset features detailed 3D meshes, parametric models, aerodynamic coefficients, and extensive flow and surface field data, along with segmented parts for car classification and point cloud data. This dataset supports a wide array of machine learning applications including data-driven design optimization, generative modeling, surrogate model training, CFD simulation acceleration, and geometric classification. With more than 39 TB of publicly available engineering data, DrivAerNet++ fills a significant gap in available resources, providing high-quality, diverse data to enhance model training, promote generalization, and accelerate automotive design processes. Along with rigorous dataset validation, we also provide ML benchmarking results on the task of aerodynamic drag prediction, showcasing the breadth of applications supported by our dataset. This dataset is set to significantly impact automotive design and broader engineering disciplines by fostering innovation and improving the fidelity of aerodynamic evaluations.

In Transactions on Machine Learning Research
In this paper, we introduce LInK, a novel framework that integrates contrastive learning of performance and design space with optimization techniques for solving complex inverse problems in engineering design with discrete and continuous variables. We focus on the path synthesis problem for planar linkage mechanisms. By leveraging a multi-modal and transformation-invariant contrastive learning framework, LInK learns a joint representation that captures complex physics and design representations of mechanisms, enabling rapid retrieval from a vast dataset of over 10 million mechanisms. This approach improves precision through the warm start of a hierarchical unconstrained nonlinear optimization algorithm, combining the robustness of traditional optimization with the speed and adaptability of modern deep learning methods. Our results on an existing benchmark demonstrate that LInK outperforms existing methods with 28 times less error compared to a state-of-the-art approach while taking 20 times less time on an existing benchmark. Moreover, we introduce a significantly more challenging benchmark, named LINK-ABC, which involves synthesizing linkages that trace the trajectories of English capital alphabets - an inverse design benchmark task that existing methods struggle with due to large non-linearities and tiny feasible space. Our results demonstrate that LInK not only advances the field of mechanism design but also broadens the applicability of contrastive learning and optimization to other areas of engineering.

In IDETC 2024
Topology optimization is a ubiquitous task in engineering design, involving the optimal distribution of material in a prescribed spatial domain. Recently, data-driven methods such as deep generative AI models have been proposed as an alternative to iterative optimization methods. However, existing data-driven approaches are often trained on datasets using fixed grid resolutions and domain shapes, reducing their applicability to different resolutions or different domain shapes. In this paper, we introduce two key innovations — a fast TO solver and a neural implicit field architecture to address these limitations. First, we introduce a fast, parallelizable, iterative GPU-based TO solver optimized for high-throughput dataset generation for 3D unstructured meshes. Our solver generated 122K optimized 3D topologies, an order of magnitude more than the largest existing public dataset. Second, we introduce a new resolution-free data-driven method for 3D topologies using neural fields, called NITO-3D. A single NITO-3D model trains and predicts for a variety of resolutions and aspect ratios. By also eliminating the need for computationally intensive physical field conditioning, NITO-3D offers a faster, more flexible alternative for 3D topology optimization. On average, NITO-3D generates topologies roughly 2000 times faster and with only 0.3% higher compliance than state-of-the-art iterative solvers. With 10 steps of iterative fine-tuning, NITO-3D is on average 15 times faster and generates topologies that are under 0.1% more compliant than SIMP’s. We open-source all data and code associated with this work at https://github.com/Lyleregenwetter/NITO-3D/.

In Transactions on Machine Learning Research
Regression models often fail to generalize effectively in regions characterized by highly imbalanced label distributions. Previous methods for deep imbalanced regression rely on gradient-based weight updates, which tend to overfit in underrepresented regions. This paper proposes a paradigm shift towards in-context learning as an effective alternative to conventional in-weight learning methods, particularly for addressing imbalanced regression. In-context learning refers to the ability of a model to condition itself, given a prompt sequence composed of in-context samples (input-label pairs) alongside a new query input to generate predictions, without requiring any parameter updates. In this paper, we study the impact of the prompt sequence on the model performance from both theoretical and empirical perspectives. We emphasize the importance of localized context in reducing bias within regions of high imbalance. Empirical evaluations across a variety of real-world datasets demonstrate that in-context learning substantially outperforms existing in-weight learning methods in scenarios with high levels of imbalance.
In IDETC 2024
Our study introduces a Generative AI method that employs a cooling-guided diffusion model to optimize the layout of battery cells, a crucial step for enhancing the cooling performance and efficiency of battery thermal management systems. Traditional design processes, which rely heavily on iterative optimization and extensive guesswork, are notoriously slow and inefficient, often leading to suboptimal solutions. In contrast, our innovative method uses a parametric denoising diffusion probabilistic model (DDPM) with classifier and cooling guidance to generate optimized cell layouts with enhanced cooling paths, significantly lowering the maximum temperature of the cells. By incorporating position-based classifier guidance, we ensure the feasibility of generated layouts. Meanwhile, cooling guidance directly optimizes cooling-efficiency, making our approach uniquely effective. When compared to two advanced models, the Tabular Denoising Diffusion Probabilistic Model (TabDDPM) and the Conditional Tabular GAN (CTGAN), our cooling-guided diffusion model notably outperforms both. It is five times more effective than TabDDPM and sixty-six times better than CTGAN across key metrics such as feasibility, diversity, and cooling efficiency. This research marks a significant leap forward in the field, aiming to optimize battery cell layouts for superior cooling efficiency, thus setting the stage for the development of more effective and dependable battery thermal management systems.
In IDETC 2024
This research introduces DesignQA, a novel benchmark aimed at evaluating the proficiency of multimodal large language models (MLLMs) in comprehending and applying engineering requirements in technical documentation. Developed with a focus on real-world engineering challenges, DesignQA uniquely combines multimodal data-including textual design requirements, CAD images, and engineering drawings-derived from the Formula SAE student competition. Different from many existing MLLM benchmarks, DesignQA contains document-grounded visual questions where the input image and input document come from different sources. The benchmark features automatic evaluation metrics and is divided into segments-Rule Comprehension, Rule Compliance, and Rule Extraction-based on tasks that engineers perform when designing according to requirements. We evaluate state-of-the-art models like GPT4 and LLaVA against the benchmark, and our study uncovers the existing gaps in MLLMs' abilities to interpret complex engineering documentation. Key findings suggest that while MLLMs demonstrate potential in navigating technical documents, substantial limitations exist, particularly in accurately extracting and applying detailed requirements to engineering designs. This benchmark sets a foundation for future advancements in AI-supported engineering design processes. DesignQA is publicly available at: https://github.com/anniedoris/design_qa/.

In IDETC 2024
This study introduces a generative imputation model leveraging graph attention networks and tabular diffusion models for completing missing parametric data in engineering designs. This model functions as an AI design co-pilot, providing multiple design options for incomplete designs, which we demonstrate using the bicycle design CAD dataset. Through comparative evaluations, we demonstrate that our model significantly outperforms existing classical methods, such as MissForest, hotDeck, PPCA, and tabular generative method TabCSDI in both the accuracy and diversity of imputation options. Generative modeling also enables a broader exploration of design possibilities, thereby enhancing design decision-making by allowing engineers to explore a variety of design completions. The graph model combines GNNs with the structural information contained in assembly graphs, enabling the model to understand and predict the complex interdependencies between different design parameters. The graph model helps accurately capture and impute complex parametric interdependencies from an assembly graph, which is key for design problems. By learning from an existing dataset of designs, the imputation capability allows the model to act as an intelligent assistant that autocompletes CAD designs based on user-defined partial parametric design, effectively bridging the gap between ideation and realization. The proposed work provides a pathway to not only facilitate informed design decisions but also promote creative exploration in design.
In IDETC 2024 (Awarded "Papers of Distinction")
This study introduces DrivAerNet, a large-scale high- fidelity CFD dataset of 3D industry-standard car shapes, and RegDGCNN, a dynamic graph convolutional neural network model, both aimed at aerodynamic car design through machine learning. DrivAerNet, with its 4000 detailed 3D car meshes using 0.5 million surface mesh faces and comprehensive aerodynamic performance data comprising of full 3D pressure, velocity fields, and wall-shear stresses, addresses the critical need for extensive datasets to train deep learning models in engineering applica- tions. It is 60% larger than the previously available largest public dataset of cars, and is the only open-source dataset that also models wheels and underbody. RegDGCNN leverages this large- scale dataset to provide high-precision drag estimates directly from 3D meshes, bypassing traditional limitations such as the need for 2D image rendering or Signed Distance Fields (SDF). By enabling fast drag estimation in seconds, RegDGCNN facili- tates rapid aerodynamic assessments, offering a substantial leap towards integrating data-driven methods in automotive design. Together, DrivAerNet and RegDGCNN promise to accelerate the car design process and contribute to the development of more efficient vehicles. To lay the groundwork for future innovations in the field, the dataset and code used in our study are publicly accessible at https://github.com/Mohamedelrefaie/DrivAerNet1.

In IDETC 2024
Text-to-image generative models have increasingly been used to assist designers during concept generation in various creative domains, such as graphic design, user interface design, and fashion design. However, their applications in engineering design remain limited due to the models' challenges in generating images of feasible designs concepts. To address this issue, this paper introduces a method that improves the design feasibility by prompting the generation with feasible CAD images. In this work, the usefulness of this method is investigated through a case study with a bike design task using an off-the-shelf text-to-image model, Stable Diffusion 2.1. A diverse set of bike designs are produced in seven different generation settings with varying CAD image prompting weights, and these designs are evaluated on their perceived feasibility and novelty. Results demonstrate that the CAD image prompting successfully helps text-to-image models like Stable Diffusion 2.1 create visibly more feasible design images. While a general tradeoff is observed between feasibility and novelty, when the prompting weight is kept low around 0.35, the design feasibility is significantly improved while its novelty remains on par with those generated by text prompts alone. The insights from this case study offer some guidelines for selecting the appropriate CAD image prompting weight for different stages of the engineering design process. When utilized effectively, our CAD image prompting method opens doors to a wider range of applications of text-to-image models in engineering design.

In Design Science
Text-to-image models are enabling efficient design space exploration, rapidly generating images from text prompts. However, many generative AI tools are imperfect for product design applications as they are not built for the goals and requirements of product design. The unclear link between text input and image output further complicates their application. This work empirically investigates design space exploration strategies that can successfully yield product images that are feasible, novel, and aesthetic, which are three common goals in product design. Specifically, user actions within the global and local editing modes, including their time spent, prompt length, mono vs. multi-criteria prompts, and goal orientation of prompts, are analyzed. Key findings reveal the pivotal role of mono vs. multi-criteria and goal orientation of prompts in achieving specific design goals over time and prompt length. The study recommends prioritizing the use of multi-criteria prompts for feasibility and novelty during global editing, while favoring mono-criteria prompts for aesthetics during local editing. Overall, this paper underscores the nuanced relationship between the AI-driven text-to-image models and their effectiveness in product design, urging designers to carefully structure prompts during different editing modes to better meet the unique demands of product design.

In International Marine Design Conference 2024
Ship design is a complex design process that may take a team of naval architects many years to complete. Improving the ship design process can lead to significant cost savings, while still delivering high-quality designs to customers. A new technology for ship hull design is diffusion models, a type of generative artificial intelligence. Prior work with diffusion models for ship hull design created high-quality ship hulls with reduced drag and larger displaced volumes. However, the work could not generate hulls that meet specific design constraints. This paper proposes a conditional diffusion model that generates hull designs given specific constraints, such as the desired principal dimensions of the hull. In addition, this diffusion model leverages the gradients from a total resistance regression model to create low-resistance designs. Five design test cases compared the diffusion model to a design optimization algorithm to create hull designs with low resistance. In all five test cases, the diffusion model was shown to create diverse designs with a total resistance less than the optimized hull, having resistance reductions over 25%. The diffusion model also generated these designs without retraining. This work can significantly reduce the design cycle time of ships by creating high-quality hulls that meet user requirements with a data-driven approach.
In DESIGN 2024
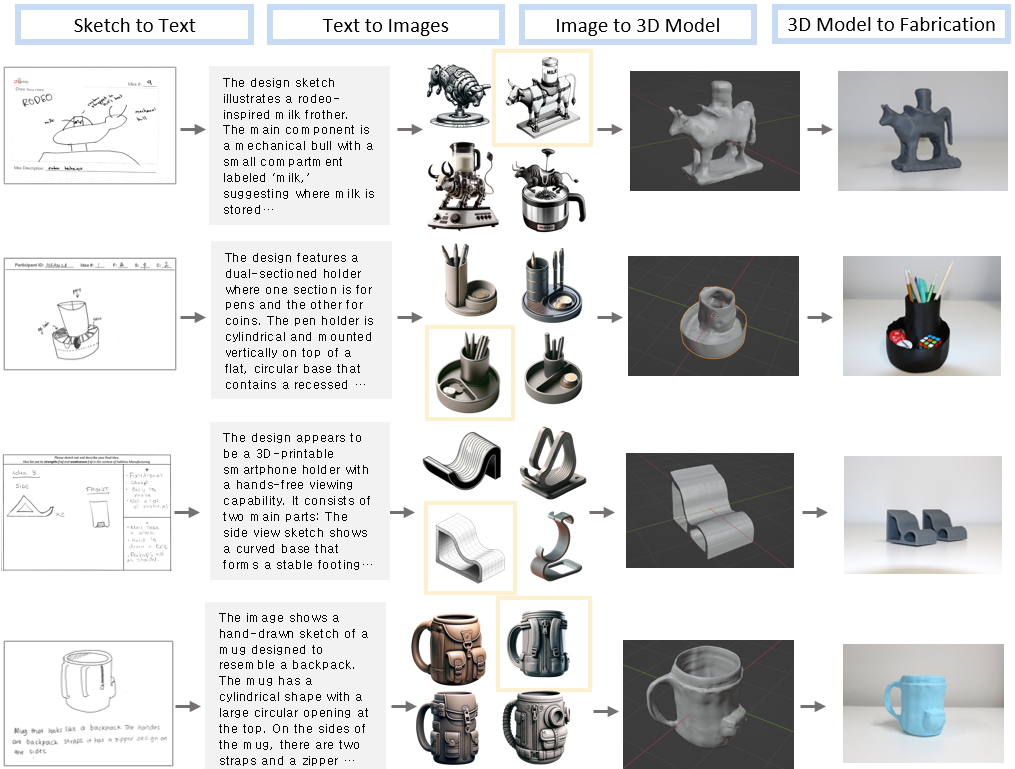
Sketch2Prototype is an AI-based framework that transforms a hand-drawn sketch into a diverse set of 2D images and 3D prototypes through sketch-to-text, text-to-image, and image-to-3D stages. This framework, shown across various sketches, rapidly generates text, image, and 3D modalities for enhanced early-stage design exploration. We show that using text as an intermediate modality outperforms direct sketch-to-3D baselines for generating diverse and manufacturable 3D models. We find limitations in current image-to-3D techniques, while noting the value of the text modality for user-feedback.

In An MIT Exploration of Generative AI
In the mid-2010s, as computing and other digital technologies matured (), researchers began to speculate about a new era of innovation—with artificial intelligence (AI) as the standard-bearer of a “Fourth Industrial Revolution” (). The release of generative AI (Gen-AI) technologies (e.g., ChatGPT) in late 2022 reignited the discussion, prompting us to wonder: what are the barriers, risks, and potential rewards to using gen-AI for design and manufacturing? As Gen-AI has entered the mainstream, geopolitics and business practices have shifted. Covid-19 disrupted global supply chains, tensions with import partners have risen, and military conflicts introduce new uncertainties. As companies consider propositions like ‘reshoring’ or ‘nearshoring/friendshoring’ production (), we recognize other hindrances: suboptimal resource allocation, labor market volatility and trends toward an older and geographically mismatched workforce, and highly concentrated tech markets that foster anticompetitive business practices. As the United States expands domestic production capacity (e.g., semiconductors and electric vehicles), Gen-AI could help us overcome those challenges. To investigate the current and potential usefulness of Gen-AI in design and manufacturing, we interviewed industry experts—including engineers, manufacturers, tech executives, and entrepreneurs. They have identified many opportunities for the deployment of Gen-AI: (1) reducing the incidence of costly late-stage design changes when scaling production; (2) providing information to designers and engineers, including identifying suitable design spaces and material formulations and incorporating consumer preferences; (3) improving test data interpretation to enable rapid validation and qualification; (4) democratizing workers’ access and usage of data to enable real-time insights and process adjustment; and (5) empowering less-skilled workers to be more productive and do more-expert work. Current Gen-AI solutions (e.g., ChatGPT, Claude) cannot accomplish these goals due to several key deficiencies, including the inability to provide robust, reliable, and replicable output; lack of relevant domain knowledge; unawareness of industry-standards requirements for product quality; failure to integrate seamlessly with existing workflow; and inability to simultaneously interpret data from different sources and formats. We propose a development framework for the next generation of Gen-AI tools for design and manufacturing (“NextGen-AI”): (1) provide better information about engineering tools, repositories, search methods, and other resources to augment the creative process of design; (2) integrate adherence to first principles when solving engineering problems; (3) leverage employees’ experiential knowledge to improve training and performance; (4) empower workers to perform new and more-expert productive tasks rather than pursue static automation of workers’ current functions; (5) create a collaborative and secure data ecosystem to train foundation models; and (6) ensure that new tools are safe and effective. These goals are extensive and will require broad-based buy-in from business leaders, operators, researchers, engineers, and policymakers. We recommend the following priorities to enable useful AI for design and manufacturing: (1) improve systems integration to ethically collect real-time data, (2) regulate data governance to ensure equal opportunity in development and ownership, (3) expand the collection of worker-safety data to assess industry-wide AI usage, (4) include engineers and operators in the development and uptake of new tools, and (5) focus on skills-complementary deployments to maximize productivity upside.
In Journal of Mechanical Design 2024
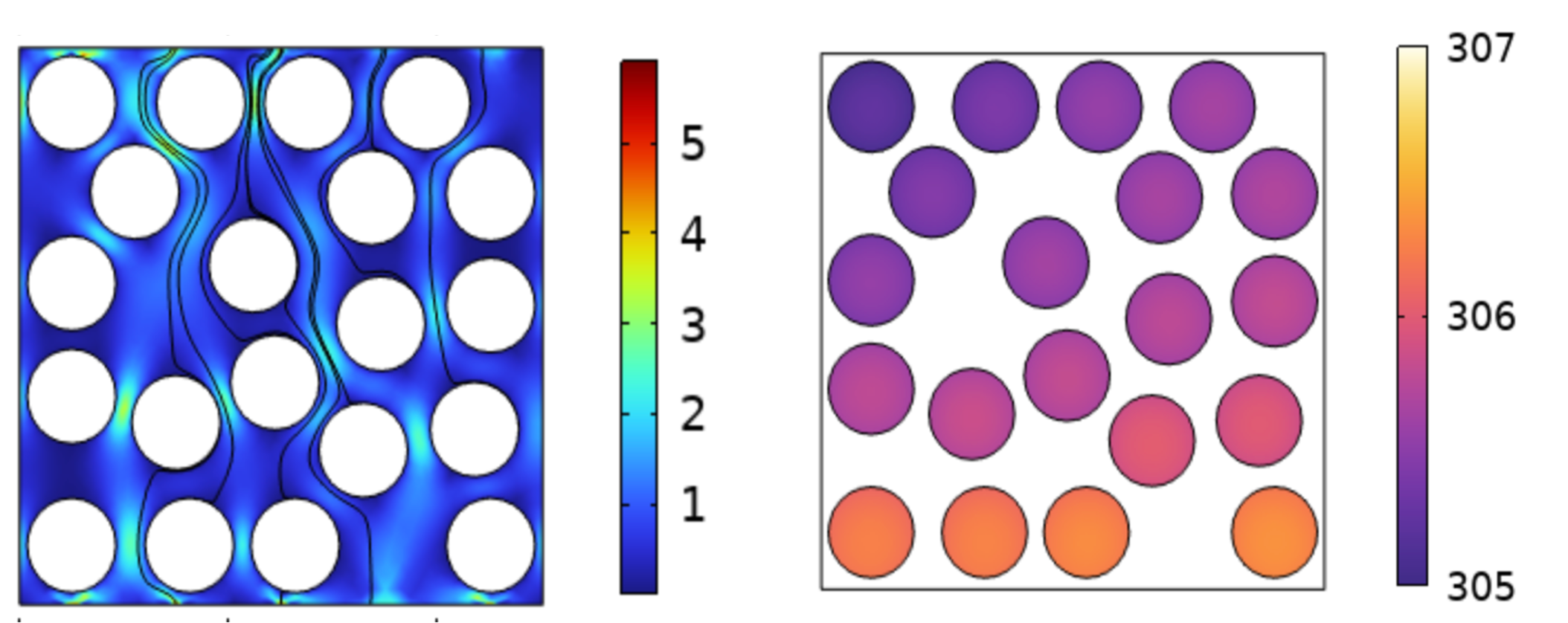
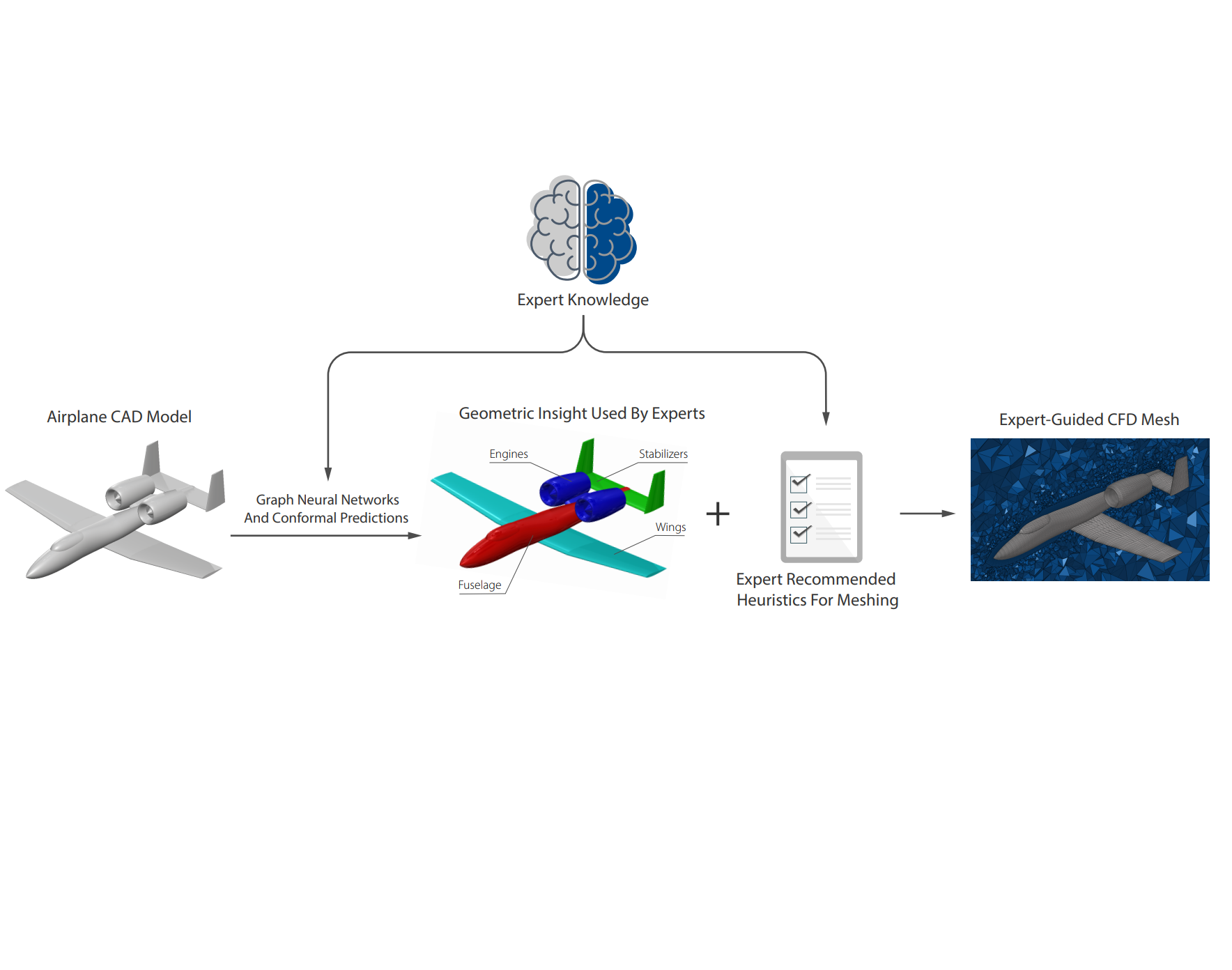
In many design automation applications, accurate segmentation and classification of 3D surfaces and extraction of geometric insight from 3D models can be pivotal. This paper primarily introduces a machine learning-based scheme that leverages Graph Neural Networks (GNN) for handling 3D geometries, specifically for surface classification. Our model demonstrates superior performance against two state-of-the-art models, PointNet++ and PointMLP, in terms of surface classification accuracy, beating both models. Central to our contribution is the novel incorporation of conformal predictions, a method that offers robust uncertainty quantification and handling with marginal statistical guarantees. Unlike traditional approaches, conformal predictions enable our model to ensure precision, especially in challenging scenarios where mistakes can be highly costly. This robustness proves invaluable in design applications, and as a case in point, we showcase its utility in automating the Computational Fluid Dynamics (CFD) meshing process for aircraft models based on expert guidance. Our results reveal that our automatically generated mesh, guided by the proposed rules by experts enabled through the segmentation model, is not only efficient but matches the quality of expert-generated meshes, leading to accurate simulations.

In AAAI AI4Design Workshop, 2024
Generative Artificial Intelligence (AI) has shown tremendous prospects in all aspects of technology, including design. However, due to its heavy demand on resources, it is usually trained on large computing infrastructure and often made available as a cloud-based service. In this position paper, we consider the potential, challenges, and promising approaches for generative AI for design on the edge, i.e., in resource-constrained settings where memory, compute, energy (battery) and network connectivity may be limited. Adapting generative AI for such settings involves overcoming significant hurdles, primarily on how to streamline complex models to function efficiently in low-resource environments. This necessitates innovative approaches in model compression, efficient algorithmic design, and perhaps even leveraging edge computing. The objective is to harness the power of generative AI in creating bespoke solutions for design problems, such as medical interventions, farm equipment maintenance, and educational material design, tailored to the unique constraints and needs of remote areas. These efforts could not only democratize access to advanced technology but also foster sustainable development, ensuring that the benefits of AI-driven design are universally accessible and environmentally considerate.
In Journal of Mechanical Design 2024
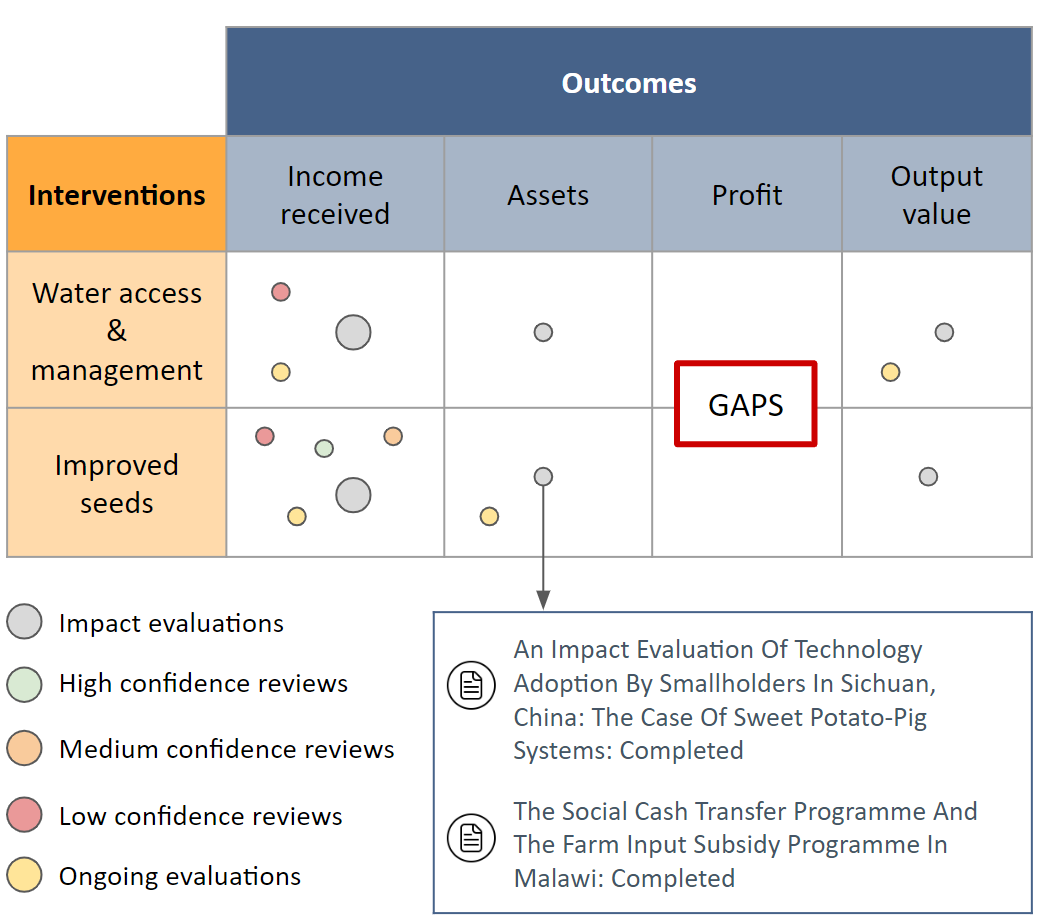
When designing evidence-based policies and programs, decision-makers must distill key information from a vast and rapidly growing literature base. Identifying relevant literature from raw search results is time and resource intensive, and is often done by manual screening. In this study, we develop an AI agent based on a bidirectional encoder representations from transformers (BERT) model and incorporate it into a human team designing an evidence synthesis product for global development. We explore the effectiveness of the human-AI hybrid team in accelerating the evidence synthesis process. We further enhance the human-AI hybrid team through active learning (AL). Specifically, we explore different sampling strategies: random, least confidence (LC), and highest priority (HP) sampling, to study their influence on the collaborative screening process. Results show that incorporating the BERT-based AI agent can reduce the human screening effort by 68.5% compared to the case of no AI assistance, and by 16.8% compared to using the industry standard model for identifying 80% of all relevant documents. When we apply the HP sampling strategy, the human screening effort can be reduced even more: by 78% for identifying 80% of all relevant documents compared to no AI assistance. We apply the AL-enhanced human-AI hybrid teaming workflow in the design process of three evidence gap maps which are now published for USAID’s use. These findings demonstrate how AI can accelerate the development of evidence synthesis products and promote timely evidence-based decision making in global development.
In Journal of Mechanical Design 2024
In engineering design, navigating complex decision-making landscapes demands a thorough exploration of the design, performance, and constraint spaces, often impeded by resource-intensive simulations. Data-driven methods can mitigate this challenge by harnessing historical data to delineate feasible domains, accelerate optimization, or evaluate designs. However, the implementation of these methods usually demands machine-learning expertise and multiple trials to choose the right method and hyperparameters. This makes them less accessible for numerous engineering situations. Additionally, there is an inherent trade-off between training speed and accuracy, with faster methods sometimes compromising precision. In our paper, we demonstrate that a recently released general-purpose transformer-based classification model, TabPFN, is both fast and accurate. Notably, it requires no dataset-specific training to assess new tabular data. TabPFN is a Prior-Data Fitted Network, which undergoes a one-time offline training across a broad spectrum of synthetic datasets and performs in-context learning. We evaluated TabPFN's efficacy across eight engineering design classification problems, contrasting it with seven other algorithms, including a state-of-the-art AutoML method. For these classification challenges, TabPFN consistently outperforms in speed and accuracy. It is also the most data-efficient and provides the added advantage of being differentiable and giving uncertainty estimates. Our findings advocate for the potential of pre-trained models that learn from synthetic data and require no domain-specific tuning to make data-driven engineering design accessible to a broader community and open ways to efficient general-purpose models valid across applications. Furthermore, we share a benchmark problem set for evaluating new classification algorithms in engineering design and make our code publicly available.
In Artificial Intelligence Review
Engineering Design is undergoing a transformative shift with the advent of AI, marking a new era in how we approach product, system, and service planning. Large language models have demonstrated impressive capabilities in enabling this shift. Yet, with text as their only input modality, they cannot leverage the large body of visual artifacts that engineers have used for centuries and are accustomed to. This gap is addressed with the release of multimodal vision language models, such as GPT-4V, enabling AI to impact many more types of tasks. In light of these advancements, this paper presents a comprehensive evaluation of GPT-4V, a vision language model, across a wide spectrum of engineering design tasks, categorized into four main areas: Conceptual Design, System-Level and Detailed Design, Manufacturing and Inspection, and Engineering Education Tasks. Our study assesses GPT-4V's capabilities in design tasks such as sketch similarity analysis, concept selection using Pugh Charts, material selection, engineering drawing analysis, CAD generation, topology optimization, design for additive and subtractive manufacturing, spatial reasoning challenges, and textbook problems. Through this structured evaluation, we not only explore GPT-4V's proficiency in handling complex design and manufacturing challenges but also identify its limitations in complex engineering design applications. Our research establishes a foundation for future assessments of vision language models, emphasizing their immense potential for innovating and enhancing the engineering design and manufacturing landscape. It also contributes a set of benchmark testing datasets, with more than 1000 queries, for ongoing advancements and applications in this field.
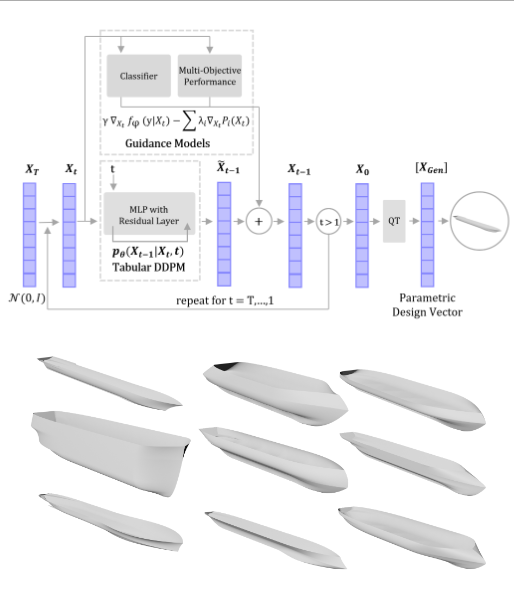
In Journal of Marine Science and Engineering 2023
Ship design is a years-long process that requires balancing complex design trade-offs to create a ship that is efficient and effective. Finding new ways to improve the ship design process can lead to significant cost savings in the time and effort required to design a ship and cost savings in the procurement and operation of a ship. One promising technology is generative artificial intelligence, which has been shown to reduce design cycle time and create novel, high-performing designs. In literature review, generative artificial intelligence has been shown to generate ship hulls; however, ship design is particularly difficult as the hull of a ship requires the consideration of many objectives. This paper presents a study on the generation of parametric ship hull designs using a parametric diffusion model that considers multiple objectives and constraints for the hulls. This denoising diffusion probabilistic model (DDPM) generates the tabular parametric design vectors of a ship hull, which is then constructed into a point cloud and mesh for performance evaluation. In addition to a tabular DDPM, this paper details adding guidance to improve the quality of generated parametric ship hull designs. By leveraging a classifier to guide sample generation, the DDPM produced feasible parametric ship hulls that maintain the coverage of the initial training dataset of ship hulls with a 99.5% rate, a 149x improvement over random sampling of the design vector parameters across the design space. Parametric ship hulls produced with performance guidance saw an average of 91.4% reduction in wave drag coefficients and an average of a 47.9x relative increase in the total displaced volume of the hulls compared to the mean performance of the hulls in the training dataset. The use of a DDPM to generate parametric ship hulls can reduce design time by generating high-performing hull designs for future analysis. These generated hulls have low drag and high volume, which can reduce the cost of operating a ship and increase its potential to generate revenue."
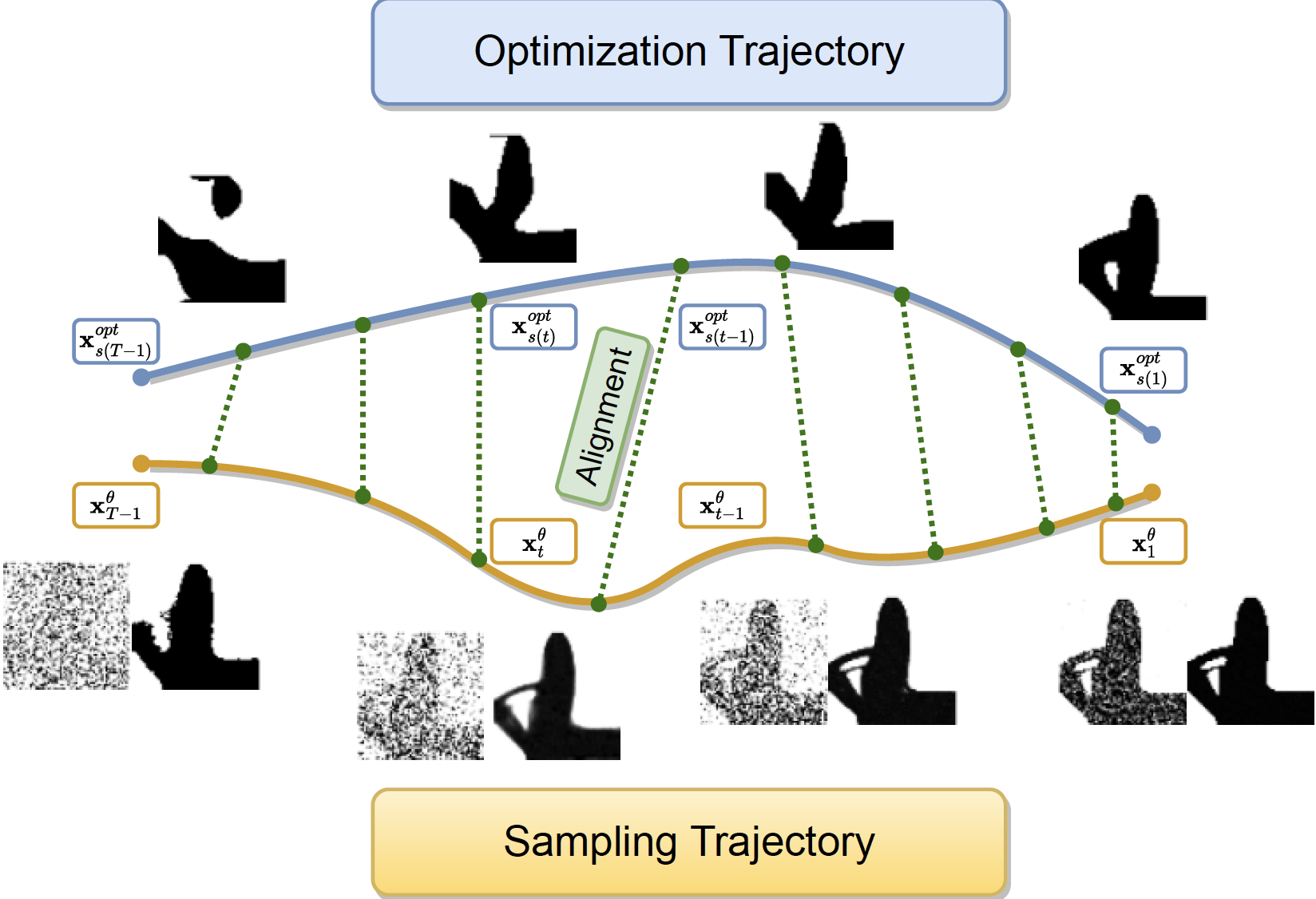
In NeurIPS 2023
Generative models have had a profound impact on vision and language, paving the way for a new era of multimodal generative applications. While these successes have inspired researchers to explore using generative models in science and engineering to accelerate the design process and reduce the reliance on iterative optimization, challenges remain. Specifically, engineering optimization methods based on physics still outperform generative models when dealing with constrained environments where data is scarce and precision is paramount. To address these challenges, we introduce Diffusion Optimization Models (DOM) and Trajectory Alignment (TA), a learning framework that demonstrates the efficacy of aligning the sampling trajectory of diffusion models with the optimization trajectory derived from traditional physics-based methods. This alignment ensures that the sampling process remains firmly grounded in the underlying physical principles. Our method allows for generating feasible and high-performance designs in as few as two steps without the need for expensive preprocessing, external surrogate models, or additional labeled data. DOM also integrates an efficient conditioning approximation to speed up inference and a few steps of direct optimization to guide the process explicitly toward regions with superior manufacturability and performance. We apply our framework to structural topology optimization, a fundamental problem in mechanical design, evaluating its performance on in- and out-of-distribution configurations. Our results demonstrate that Trajectory Alignment outperforms state-of-the-art deep generative models on in-distribution configurations and halves the inference computational cost. When coupled with a few steps of optimization, it also improves manufacturability for out-of-distribution conditions. DOM shows the effectiveness of combining learning and optimization trajectories. By significantly improving engineering performance and inference efficiency, it enables us to generate high-quality designs in just a few steps and guide them toward regions of high performance and manufacturability, paving the way for the widespread application of generative models in large-scale data-driven design.
In IDETC 2023
We introduce Multi-Objective Counterfactuals for Design (MCD), a novel method for counterfactual optimization in design problems. Counterfactuals are hypothetical situations that can lead to a different decision or choice. In this paper, the authors frame the counterfactual search problem as a design recommendation tool that can help identify modifications to a design, leading to better functional performance. MCD improves upon existing counterfactual search methods by supporting multi-objective queries, which are crucial in design problems, and by decoupling the counterfactual search and sampling processes, thus enhancing efficiency and facilitating objective tradeoff visualization. The paper demonstrates MCD's core functionality using a two-dimensional test case, followed by three case studies of bicycle design that showcase MCD's effectiveness in real-world design problems. In the first case study, MCD excels at recommending modifications to query designs that can significantly enhance functional performance, such as weight savings and improvements to the structural safety factor. The second case study demonstrates that MCD can work with a pre-trained language model to suggest design changes based on a subjective text prompt effectively. Lastly, the authors task MCD with increasing a query design's similarity to a target image and text prompt while simultaneously reducing weight and improving structural performance, demonstrating MCD's performance on a complex multimodal query. Overall, MCD has the potential to provide valuable recommendations for practitioners and design automation researchers looking for answers to their "What if" questions by exploring hypothetical design modifications and their impact on multiple design objectives.
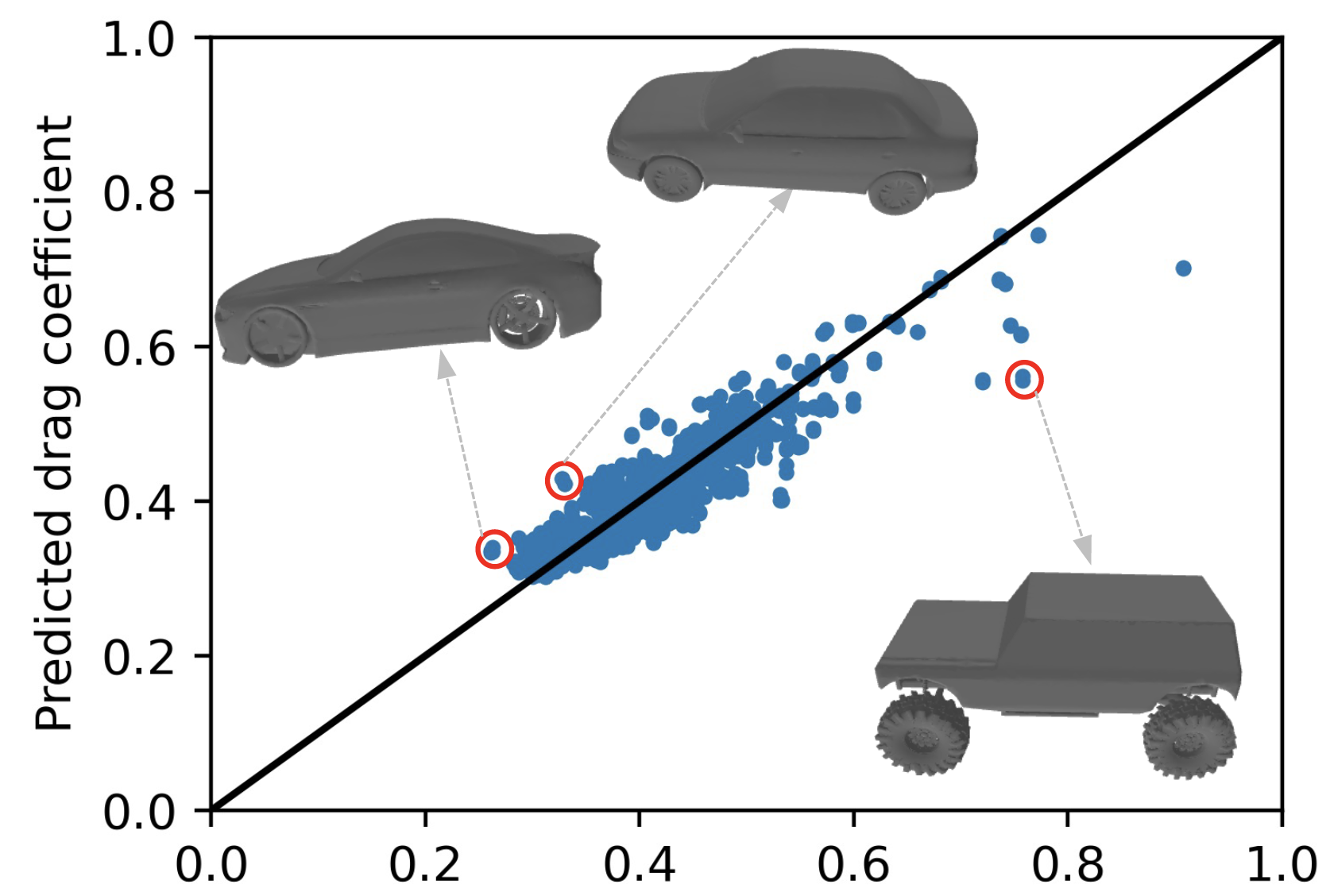
In IDETC 2023 (Awarded "Papers of Distinction")
Generative AI models have made significant progress in automating the creation of 3D shapes, which has the potential to transform car design. In engineering design and optimization, evaluating engineering metrics is crucial. To make generative models performance-aware and enable them to create high-performing designs, surrogate modeling of these metrics is necessary. However, the currently used representations of three-dimensional (3D) shapes either require extensive computational resources to learn or suffer from significant information loss, which impairs their effectiveness in surrogate modeling. To address this issue, we propose a new two-dimensional (2D) representation of 3D shapes. We develop a surrogate drag model based on this representation to verify its effectiveness in predicting 3D car drag. We construct a diverse dataset of 9,070 high-quality 3D car meshes labeled by drag coefficients computed from computational fluid dynamics (CFD) simulations to train our model. Our experiments demonstrate that our model can accurately and efficiently evaluate drag coefficients with an R^2 value above 0.84 for various car categories. Moreover, the proposed representation method can be generalized to many other product categories beyond cars. Our model is implemented using deep neural networks, making it compatible with recent AI image generation tools (such as Stable Diffusion) and a significant step towards the automatic generation of drag-optimized car designs. We have made the dataset and code publicly available at https://decode.mit.edu/projects/dragprediction/.

In IDETC 2023
Accurate vehicle rating prediction can facilitate designing and configuring good vehicles. This prediction allows vehicle designers and manufacturers to optimize and improve their designs in a timely manner, enhance their product performance, and effectively attract consumers. However, most of the existing data-driven methods rely on data from a single mode, e.g., text, image, or parametric data, which results in a limited and incomplete exploration of the available information. These methods lack comprehensive analyses and exploration of data from multiple modes, which probably leads to inaccurate conclusions and hinders progress in this field. To overcome this limitation, we propose a multi-modal learning model for more comprehensive and accurate vehicle rating predictions. Specifically, the model simultaneously learns features from the parametric specifications, text descriptions, and images of vehicles to predict five vehicle rating scores, including the total score, critics score, performance score, safety score, and interior score. We compare the multi-modal learning model to the corresponding unimodal models and find that the multi-modal model's explanatory power is 4% - 12% higher than that of the unimodal models. On this basis, we conduct sensitivity analyses using SHAP to interpret our model and provide design and optimization directions to designers and manufacturers. Our study underscores the importance of the data-driven multi-modal learning approach for vehicle design, evaluation, and optimization. We have made the code publicly available at https://decode.mit.edu/projects/vehicleratings/.
In IDETC 2023
Computational Fluid Dynamics (CFD) is widely used in different engineering fields, but accurate simulations are dependent upon proper meshing of the simulation domain. While highly refined meshes may ensure precision, they come with high computational costs. Similarly, adaptive remeshing techniques require multiple simulations and come at a great computational cost. This means that the meshing process is reliant upon expert knowledge and years of experience. Automating mesh generation can save significant time and effort and lead to a faster and more efficient design process. This paper presents a machine learning-based scheme that utilizes Graph Neural Networks (GNN) and expert guidance to automatically generate CFD meshes for aircraft models. In this work, we introduce a new 3D segmentation algorithm that outperforms two state-of-the-art models, PointNet++ and PointMLP, for surface classification. We also present a novel approach to project predictions from 3D mesh segmentation models to CAD surfaces using the conformal predictions method, which provides marginal statistical guarantees and robust uncertainty quantification and handling. We demonstrate that the addition of conformal predictions effectively enables the model to avoid under-refinement, hence failure, in CFD meshing even for weak and less accurate models. Finally, we demonstrate the efficacy of our approach through a real-world case study that demonstrates that our automatically generated mesh is comparable in quality to expert-generated meshes, and enables the solver to converge and produce accurate results. The code and data for this project is made publicly available at https://github.com/ahnobari/AutoSurf.

In IDETC 2023
Exploiting the recent advancements in artificial intelligence, showcased by ChatGPT and DALL-E, in real-world applications necessitates vast, domain-specific, and publicly accessible datasets. Unfortunately, the scarcity of such datasets poses a significant challenge for researchers aiming to apply these breakthroughs in engineering design. Synthetic datasets emerge as a viable alternative. However, practitioners are often uncertain about generating high-quality datasets that accurately represent real-world data and are suitable for the intended downstream applications. This study aims to fill this knowledge gap by proposing comprehensive guidelines for generating, annotating, and validating synthetic datasets. The trade-offs and methods associated with each of these aspects are elaborated upon. Further, the practical implications of these guidelines are illustrated through the creation of a turbo-compressors dataset. The study underscores the importance of thoughtful sampling methods to ensure the appropriate size, diversity, utility, and realism of a dataset. It also highlights that design diversity does not equate to performance diversity or realism. By employing test sets that represent uniform, real, or task-specific samples, the influence of sample size and sampling strategy is scrutinized. Overall, this paper offers valuable insights for researchers intending to create and publish synthetic datasets for engineering design, thereby paving the way for more effective applications of AI advancements in the field. The code and data for the dataset and methods are made publicly accessible at https://github.com/cyrilpic/radcomp.

In IDETC 2023
Machine learning has recently made significant strides in reducing design cycle time for complex products. Ship design, which currently involves years-long cycles and small batch production, could greatly benefit from these advancements. By developing a machine learning tool for ship design that learns from the design of many different types of ships, trade-offs in ship design could be identified and optimized. However, the lack of publicly available ship design datasets currently limits the potential for leveraging machine learning in generalized ship design. To address this gap, this paper presents a large dataset of 30,000 ship hulls, each with design and functional performance information, including parameterization, mesh, point-cloud, and image representations, as well as 32 hydrodynamic drag measures under different operating conditions. The dataset is structured to allow human input and is also designed for computational methods. Additionally, the paper introduces a set of 12 ship hulls from publicly available CAD repositories to showcase the proposed parameterizations ability to accurately reconstruct existing hulls. A surrogate model was developed to predict the 32 wave drag coefficients, which was then implemented in a genetic algorithm case study to reduce the total drag of a hull by 60 percent while maintaining the shape of the hulls cross section and the length of the parallel midbody. Our work provides a comprehensive dataset and application examples for other researchers to use in advancing data-driven ship design.
In IDETC 2023 (Awarded "Papers of Distinction")
When designing evidence-based policies and programs, decision-makers must distill key information from a vast and rapidly growing literature base. Identifying relevant literature from raw search results is time and resource intensive, and is often done by manual screening. In this study, we develop an AI agent based on a bidirectional encoder representations from transformers (BERT) model and incorporate it into a human team designing an evidence synthesis product for global development. We explore the effectiveness of the human-AI hybrid team in accelerating the evidence synthesis process. To further improve team efficiency, we enhance the human-AI hybrid team through active learning (AL). Specifically, we explore different sampling strategies, including random sampling, least confidence (LC) sampling, and highest priority (HP) sampling, to study their influence on the collaborative screening process. Results show that incorporating the BERT-based AI agent into the human team can reduce the human screening effort by 68.5% compared to the case of no AI assistance and by 16.8% compared to the case of using a support vector machine (SVM)-based AI agent for identifying 80% of all relevant documents. When we apply the HP sampling strategy for AL, the human screening effort can be reduced even more: by 78.3% for identifying 80% of all relevant documents compared to no AI assistance. We apply the AL-enhanced human-AI hybrid teaming workflow in the design process of three evidence gap maps (EGMs) for USAID and find it to be highly effective. These findings demonstrate how AI can accelerate the development of evidence synthesis products and promote timely evidence-based decision making in global development in a human-AI hybrid teaming context.
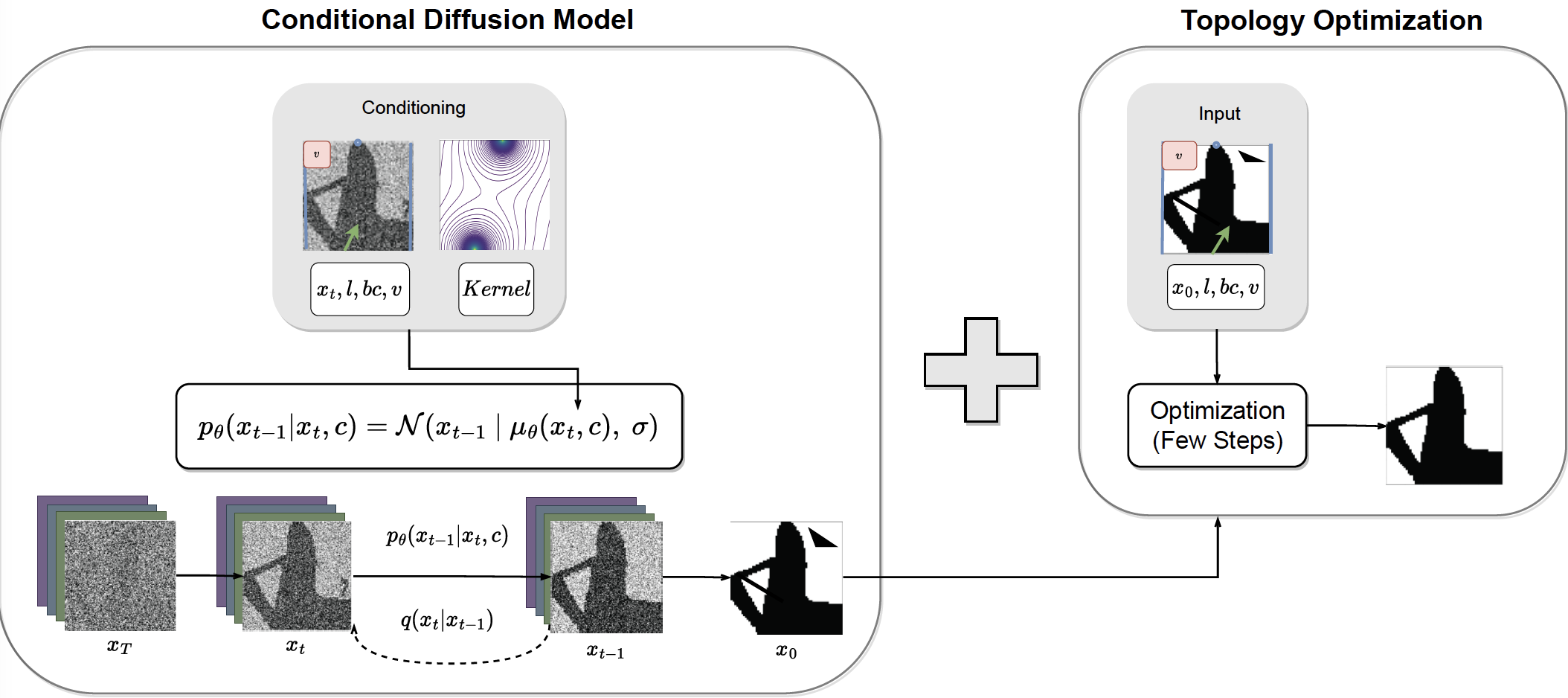
In IDETC 2023
Topology Optimization seeks to find the best design that satisfies a set of constraints while maximizing system performance. Traditional iterative optimization methods like SIMP can be computationally expensive and get stuck in local minima, limiting their applicability to complex or large-scale problems. Learning-based approaches have been developed to accelerate the topology optimization process, but these methods can generate designs with floating material and low performance when challenged with out-of-distribution constraint configurations. Recently, deep generative models, such as Generative Adversarial Networks and Diffusion Models, conditioned on constraints and physics fields have shown promise, but they require extensive pre-processing and surrogate models for improving performance. To address these issues, we propose a Generative Optimization method that integrates classic optimization like SIMP as a refining mechanism for the topology generated by a deep generative model. We also remove the need for conditioning on physical fields using a computationally inexpensive approximation inspired by classic ODE solutions and reduce the number of steps needed to generate a feasible and performant topology. Our method allows us to efficiently generate good topologies and explicitly guide them to regions with high manufacturability and high performance, without the need for external auxiliary models or additional labeled data. We believe that our method can lead to significant advancements in the design and optimization of structures in engineering applications, and can be applied to a broader spectrum of performance-aware engineering design problems.
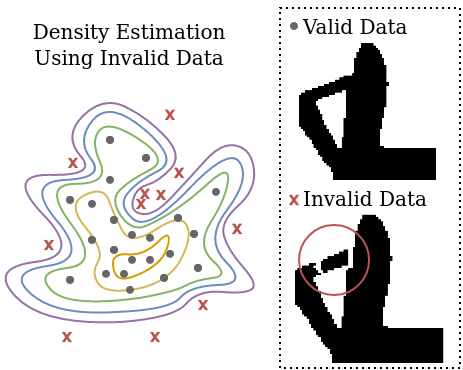
In Neurips Workshop on Diffusion Models, 2023
Generative models have demonstrated impressive results in vision, language, and speech. However, even with massive datasets, they struggle with precision, generating physically invalid or factually incorrect data. To improve precision while preserving diversity and fidelity, we propose a novel training mechanism that leverages datasets of constraint-violating data points, which we consider invalid. Our approach minimizes the divergence between the generative distribution and the valid prior while maximizing the divergence with the invalid distribution. We demonstrate how generative models like Diffusion Models and GANs that we augment to train with invalid data improve their standard counterparts which solely train on valid data points. We also explore connections between density ratio and guidance in diffusion models. Our proposed mechanism offers a promising solution for improving precision in generative models while preserving diversity and fidelity, particularly in domains where constraint satisfaction is critical and data is limited, such as engineering design, robotics, and medicine.
In Neurips Workshop on Diffusion Models, 2023
Generative models have had a profound impact on vision and language, paving the way for a new era of multimodal generative applications. Yet, challenges persist in constrained environments, such as engineering and science, where data is limited and precision is crucial. We introduce Diffusion Optimization Models (DOM) and Trajectory Alignment (TA), a regularization technique aligning diffusion model sampling with physics-based optimization. By significantly improving performance and inference efficiency, DOM enables us to generate high-quality designs in just a few steps and guide them toward regions of high performance and manufacturability, paving the way for the widespread application of generative models in large-scale data-driven design.
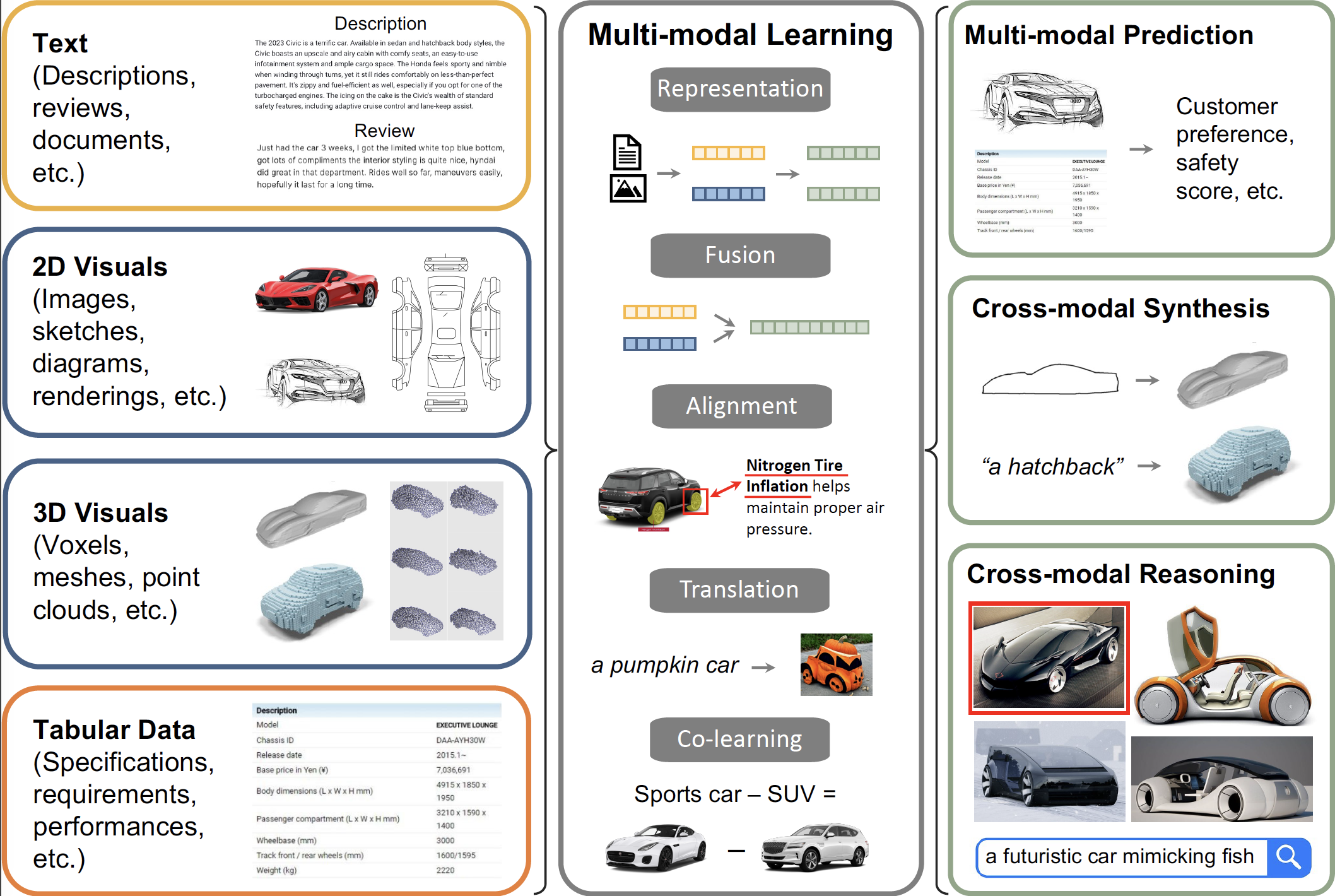
In Journal of Computer and Information Science in Engineering 2023
Multi-modal machine learning (MMML), which involves integrating multiple modalities of data and their corresponding processing methods, has demonstrated promising results in various practical applications, such as text-to-image translation. This review paper summarizes the recent progress and challenges in using MMML for engineering design tasks. First, we introduce the different data modalities commonly used as design representations and involved in MMML, including text, 2D pixel data (e.g., images and sketches), and 3D shape data (e.g., voxels, point clouds, and meshes). We then provide an overview of the various approaches and techniques used for representing, fusing, aligning, synthesizing, and co-learning multi-modal data as five fundamental concepts of MMML. Next, we review the state-of-the-art capabilities of MMML that potentially apply to engineering design tasks, including design knowledge retrieval, design evaluation, and design synthesis. We also highlight the potential benefits and limitations of using MMML in these contexts. Finally, we discuss the challenges and future directions in using MMML for engineering design, such as the need for large labeled multi-modal design datasets, robust and scalable algorithms, integrating domain knowledge, and handling data heterogeneity and noise. Overall, this review paper provides a comprehensive overview of the current state and prospects of MMML for engineering design applications.
In Computer Aided Design 2023
Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper.
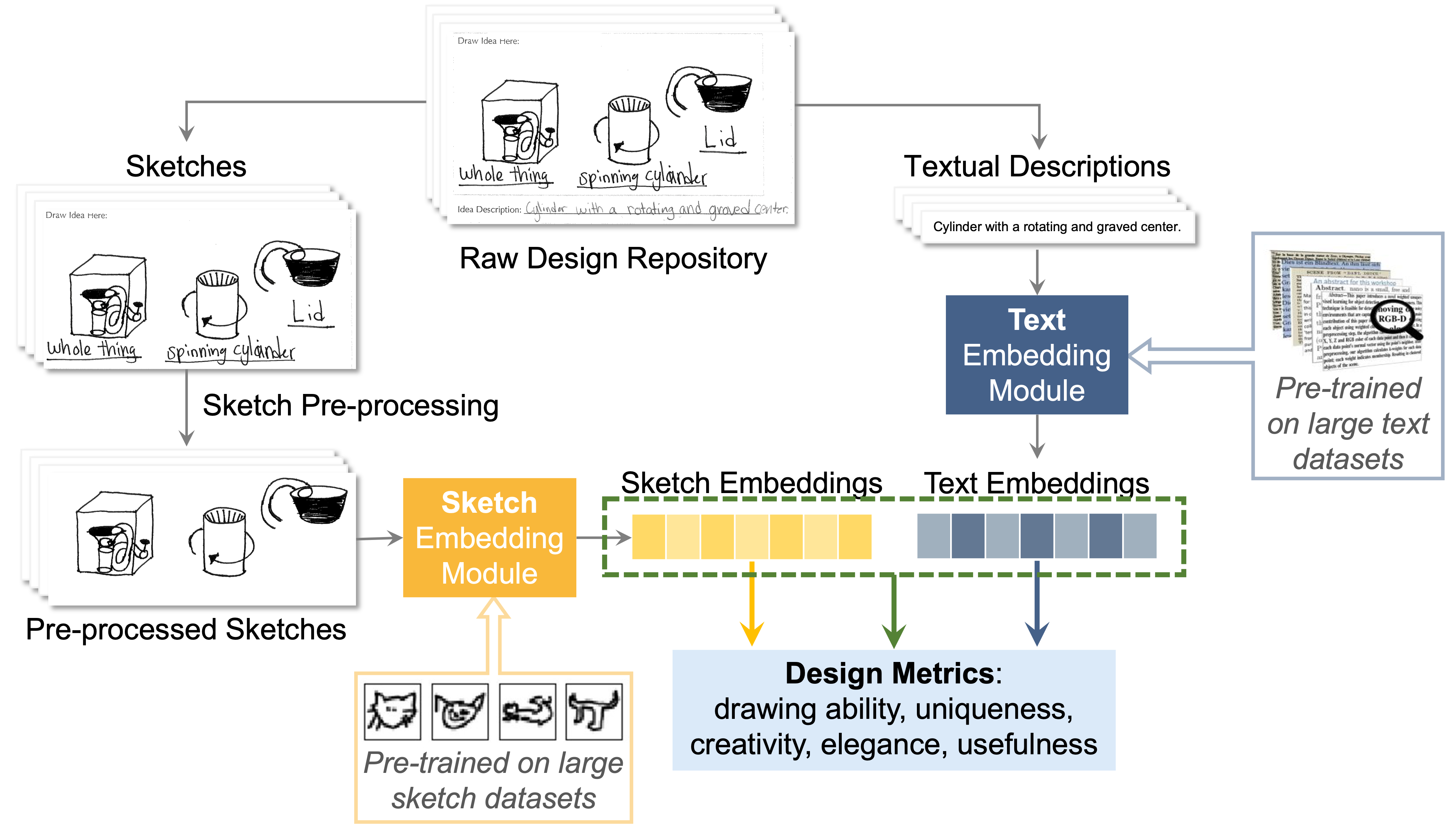
In Journal of Mechanical Design 2023
Conceptual design evaluation is an indispensable component of innovation in the early stage of engineering design. Properly assessing the effectiveness of conceptual design requires a rigorous evaluation of the outputs. Traditional methods to evaluate conceptual designs are slow, expensive, and difficult to scale because they rely on human expert input. An alternative approach is to use computational methods to evaluate design concepts. However, most existing methods have limited utility because they are constrained to unimodal design representations (e.g., texts or sketches). To overcome these limitations, we propose an attention-enhanced multimodal learning (AEMML)-based machine learning (ML) model to predict five design metrics- drawing quality, uniqueness, elegance, usefulness, and creativity. The proposed model utilizes knowledge from large external datasets through transfer learning (TL), simultaneously processes text and sketch data from early-phase concepts, and effectively fuses the multimodal information through a mutual cross-attention mechanism. To study the efficacy of multimodal learning (MML) and attention-based information fusion, we compare (1) a baseline MML model and the unimodal models and (2) the attention-enhanced models with baseline models in terms of their explanatory power for the variability of the design metrics. The results show that MML improves the model explanatory power by 0.05-0.12 and the mutual cross-attention mechanism further increases the explanatory power of the approach by 0.05-0.09, leading to the highest explanatory power of 0.44 for drawing quality, 0.60 for uniqueness, 0.45 for elegance, 0.43 for usefulness, and 0.32 for creativity. Our findings highlight the benefit of using multimodal representations for design metric assessment.

In AAAI 2023
Structural topology optimization, which aims to find the optimal physical structure that maximizes mechanical performance, is vital in engineering design applications in aerospace, mechanical, and civil engineering. Generative adversarial networks (GANs) have recently emerged as a popular alternative to traditional iterative topology optimization methods. However, these models are often difficult to train, have limited generalizability, and due to their goal of mimicking optimal structures, neglect manufacturability and performance objectives like mechanical compliance. We propose TopoDiff - a conditional diffusion-model-based architecture to perform performance-aware and manufacturability-aware topology optimization that overcomes these issues. Our model introduces a surrogate model-based guidance strategy that actively favors structures with low compliance and good manufacturability. Our method significantly outperforms a state-of-art conditional GAN by reducing the average error on physical performance by a factor of eight and by producing eleven times fewer infeasible samples. By introducing diffusion models to topology optimization, we show that conditional diffusion models have the ability to outperform GANs in engineering design synthesis applications too. Our work also suggests a general framework for engineering optimization problems using diffusion models and external performance with constraint-aware guidance. We publicly share the data, code, and trained models.

In Computer Aided Design 2023
This paper demonstrates how Automated Machine Learning (AutoML) methods can be used as effective surrogate models in engineering design problems. To do so, we consider the challenging problem of structurally-performant bicycle frame design and demonstrate across-the-board dominance by AutoML in regression and classification surrogate modeling tasks. We also introduce FRAMED — a parametric dataset of 4500 bicycle frames based on bicycles designed by practitioners and enthusiasts worldwide. Accompanying these frame designs, we provide ten structural performance values such as weight, displacements under load, and safety factors computed using finite element simulations for all the bicycle frame designs. We formulate two challenging test problems- a performance-prediction regression problem and a feasibility-prediction classification problem. We then systematically search for optimal surrogate models using Bayesian hyperparameter tuning and neural architecture search. Finally, we show how a state-of-the-art AutoML method can be effective for both regression and classification problems. We demonstrate that the proposed AutoML models outperform the strongest gradient boosting and neural network surrogates identified through Bayesian optimization by an improved F1 score of 24% for classification and reduced mean absolute error by 12.5% for regression. Our work introduces a dataset for bicycle design practitioners, provides two benchmark problems for surrogate modeling researchers, and demonstrates the advantages of AutoML in machine learning tasks.

In IDETC 2022
In this paper, we introduce LINKS, a dataset of 100 million one degree of freedom planar linkage mechanisms and 1.1 billion coupler curves, which is more than 1000 times larger than any existing database of planar mechanisms and is not limited to specific kinds of mechanisms such as four-bars, six-bars, etc. which are typically what most databases include. LINKS is made up of various components including 100 million mechanisms, the simulation data for each mechanism, normalized paths generated by each mechanism, a curated set of paths, the code used to generate the data and simulate mechanisms, and a live web demo for interactive design of linkage mechanisms. The curated paths are provided as a measure for removing biases in the paths generated by mechanisms that enable a more even design space representation. In this paper, we discuss the details of how we can generate such a large dataset and how we can overcome major issues with such scales. To be able to generate such a large dataset we introduce a new operator to generate 1-DOF mechanism topologies, furthermore, we take many steps to speed up slow simulations of mechanisms by vectorizing our simulations and parallelizing our simulator on a large number of threads, which leads to a simulation 800 times faster than the simple simulation algorithm. This is necessary given on average, 1 out of 500 candidates that are generated are valid~(and all must be simulated to determine their validity), which means billions of simulations must be performed for the generation of this dataset. Then we demonstrate the depth of our dataset through a bi-directional chamfer distance-based shape retrieval study where we show how our dataset can be used directly to find mechanisms that can trace paths very close to desired target paths.
In ICML Workshop on Computational Design, 2022
Deep Generative Machine Learning Models (DGMs) have been growing in popularity across the design community thanks to their ability to learn and mimic complex data distributions. DGMs are conventionally trained to minimize statistical divergence between the distribution over generated data and distribution over the dataset on which they are trained. While sufficient for the task of generating “realistic” fake data, this objective is typically insufficient for design synthesis tasks. Instead, design problems typically call for adherence to design requirements, such as performance targets and constraints. Advancing DGMs in engineering design requires new training objectives which promote engineering design objectives. In this paper, we present the first Deep Generative Model that simultaneously optimizes for performance, feasibility, diversity, and target achievement. We benchmark performance of the proposed method against several Deep Generative Models over eight evaluation metrics that focus on feasibility, diversity, and satisfaction of design performance targets. Methods are tested on a challenging multi-objective bicycle frame design problem with skewed, multimodal data of different datatypes. The proposed framework was found to outperform all Deep Generative Models in six of eight metrics.
In IDETC 2022
Deep Generative Machine Learning Models have been growing in popularity across the design community thanks to their ability to learn and mimic complex data distributions. While early works are promising, further advancement will depend on addressing several critical considerations such as design quality, feasibility, novelty, and targeted inverse design. We propose the Design Target Achievement Index (DTAI), a differentiable, tunable metric that scores a design’s ability to achieve designer-specified minimum performance targets. We demonstrate that DTAI can drastically improve the performance of generated designs when directly used as a training loss in Deep Generative Models. We apply the DTAI loss to a Performance- Augmented Diverse GAN (PaDGAN) and demonstrate superior generative performance compared to a set of baseline Deep Generative Models including a Multi-Objective PaDGAN and specialized tabular generation algorithms like the Conditional Tabular GAN (CTGAN).We further enhance PaDGAN with an auxiliary feasibility classifier to encourage feasible designs. To evaluate methods, we propose a comprehensive set of evaluation metrics for generative methods that focus on feasibility, diversity, and satisfaction of design performance targets. Methods are tested on a challenging benchmarking problem- the FRAMED bicycle frame design dataset featuring mixed-datatype parametric data, heavily skewed and multimodal distributions, and ten competing performance objectives.
In IDETC 2022
Measuring design creativity is an indispensable component of innovation in engineering design. Properly assessing the creativity of a design requires a rigorous evaluation of the outputs. Traditional methods to evaluate designs are slow, expensive, and difficult to scale because they rely on human expert input. An alternative approach is to use computational methods to evaluate designs. However, most existing methods have limited utility because they are constrained to unimodal design representations (e.g., texts or sketches) and small datasets. To overcome these limitations, we propose a multimodal transfer learning-based machine learning model to predict five design metrics- drawing quality, uniqueness, elegance, usefulness, and creativity. The proposed model utilizes knowledge from large external datasets through transfer learning and simultaneously processes text and sketch data from early-phase concepts through multi-modal learning. Through six unimodal models using only texts or sketches, we show that transfer learning improves the predictive validity of text learning and sketch learning by 2%–18% and 9%–24%, respectively, for design metric evaluation. By comparing our multimodal model with the best unimodal models, we demonstrate that joining unimodal text and sketch learning models further increases the predictive validity of the approach by 4%–10%. The proposed models are generalizable to many application contexts beyond design concepts. Our findings highlight the importance of analyzing designs from multiple perspectives for design assessment. Finally, we discuss the challenges and opportunities in developing AI models for design metric evaluation.
In IDETC 2022
The placement of objects on a ship is critical to many facets of the performance of a ship. Most notably, the mass distribution properties of objects in a ship affect the ship’s stability, trim, and structural loading. Information gathered from object placement optimization can allow naval architects to further optimize the design of the whole ship by potentially reducing the structural weight of the vessel, and adjusting the shape of the hull or the general arrangements based on available space in the ship. This paper presents a novel, many-objective bin packing problem for object placement across multiple decks on a ship. This problem is also highly constrained to avoid object intersection and protrusion. The problem was optimized with the NSGA-II algorithm, utilizing a heuristic population initialization and by separating the objectives into a bilevel optimization scheme. The bilevel scheme decouples certain objectives and design variables from the rest of the problem and sequences the evaluation for the objectives in a two-stage process. The hypervolume of the final population measured the performance of the optimization test. The results indicate that sequencing the objectives with a bilevel scheme produces an 80.3% larger hypervolume than an all-in-one optimization for the same problem. The findings from this study provide a systematic way by combining concepts from many-objective optimization, bin packing heuristics, and bilevel optimization to sequence the optimization of many-objective, object placement problems.
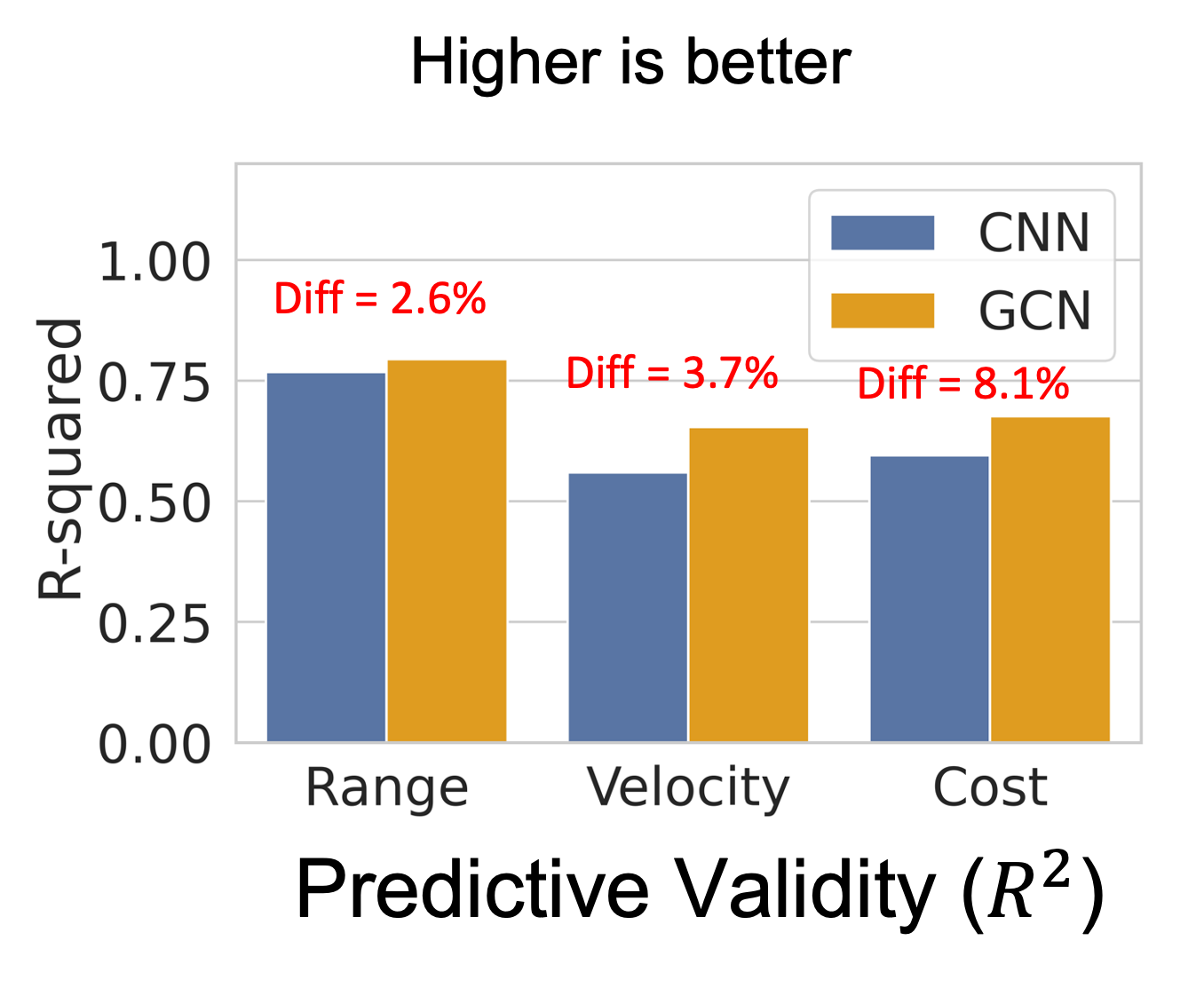
In Design 2022
Deep learning (DL) from various representations have succeeded in many fields. However, we know little about the machine learnability of distinct design representations when using DL to predict design performance. This paper proposes a graph representation for designs and compares it to the common image representation. We employ graph neural networks (GNNs) and convolutional neural networks (CNNs) respectively to learn them to predict drone performance. GCNs outperform CNNs by 2.6-8.1% in predictive validity. We argue that graph learning is a powerful and generalizable method for such tasks.
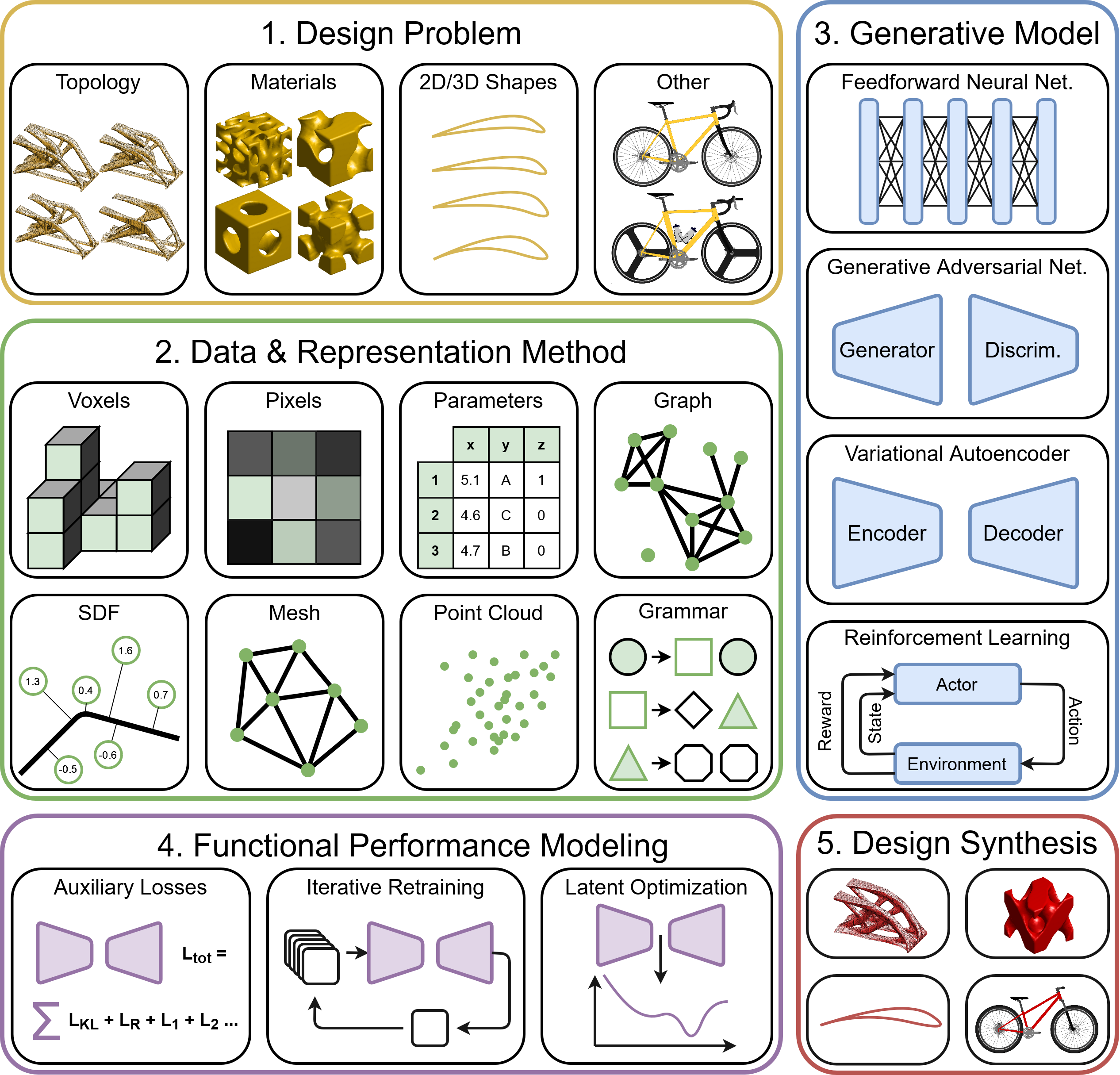
In Journal of Mechanical Design 2022
Automated design synthesis has the potential to revolutionize the modern engineering design process and improve access to highly optimized and customized products across countless industries. Successfully adapting generative machine learning to design engineering may enable such automated design synthesis and is a research subject of great importance. We present a review and analysis of deep generative machine learning models in engineering design. Deep generative models (DGMs) typically leverage deep networks to learn from an input dataset and synthesize new designs. Recently, DGMs such as feedforward neural networks (NNs), generative adversarial networks (GANs), variational autoencoders (VAEs), and certain deep reinforcement learning (DRL) frameworks have shown promising results in design applications like structural optimization, materials design, and shape synthesis. The prevalence of DGMs in engineering design has skyrocketed since 2016. Anticipating the continued growth, we conduct a review of recent advances to benefit researchers interested in DGMs for design. We structure our review as an exposition of the algorithms, datasets, representation methods, and applications commonly used in the current literature. In particular, we discuss key works that have introduced new techniques and methods in DGMs, successfully applied DGMs to a design-related domain, or directly supported the development of DGMs through datasets or auxiliary methods. We further identify key challenges and limitations currently seen in DGMs across design fields, such as design creativity, handling constraints and objectives, and modeling both form and functional performance simultaneously. In our discussion, we identify possible solution pathways as key areas on which to target the future work.

In Journal of Mechanical Design 2022
In this paper, we present “BIKED,” a dataset composed of 4500 individually designed bicycle models sourced from hundreds of designers. We expect BIKED to enable a variety of data-driven design applications for bicycles and support the development of data-driven design methods. The dataset is comprised of a variety of design information including assembly images, component images, numerical design parameters, and class labels. In this paper, we first discuss the processing of the dataset, and then highlight some prominent research questions that BIKED can help address. Of these questions, we further explore the following in detail- (1) How can we explore, understand, and visualize the current design space of bicycles and utilize this information? We apply unsupervised embedding methods to study the design space and identify key takeaways from this analysis. (2) When designing bikes using algorithms, under what conditions can machines understand the design of a given bike? We train a multitude of classifiers to understand designs, then examine the behavior of these classifiers through confusion matrices and permutation-based interpretability analysis. 3) Can machines learn to synthesize new bicycle designs by studying existing ones? We test Variational Autoencoders on random generation, interpolation, and extrapolation tasks after training on BIKED data. The dataset and code are available online.
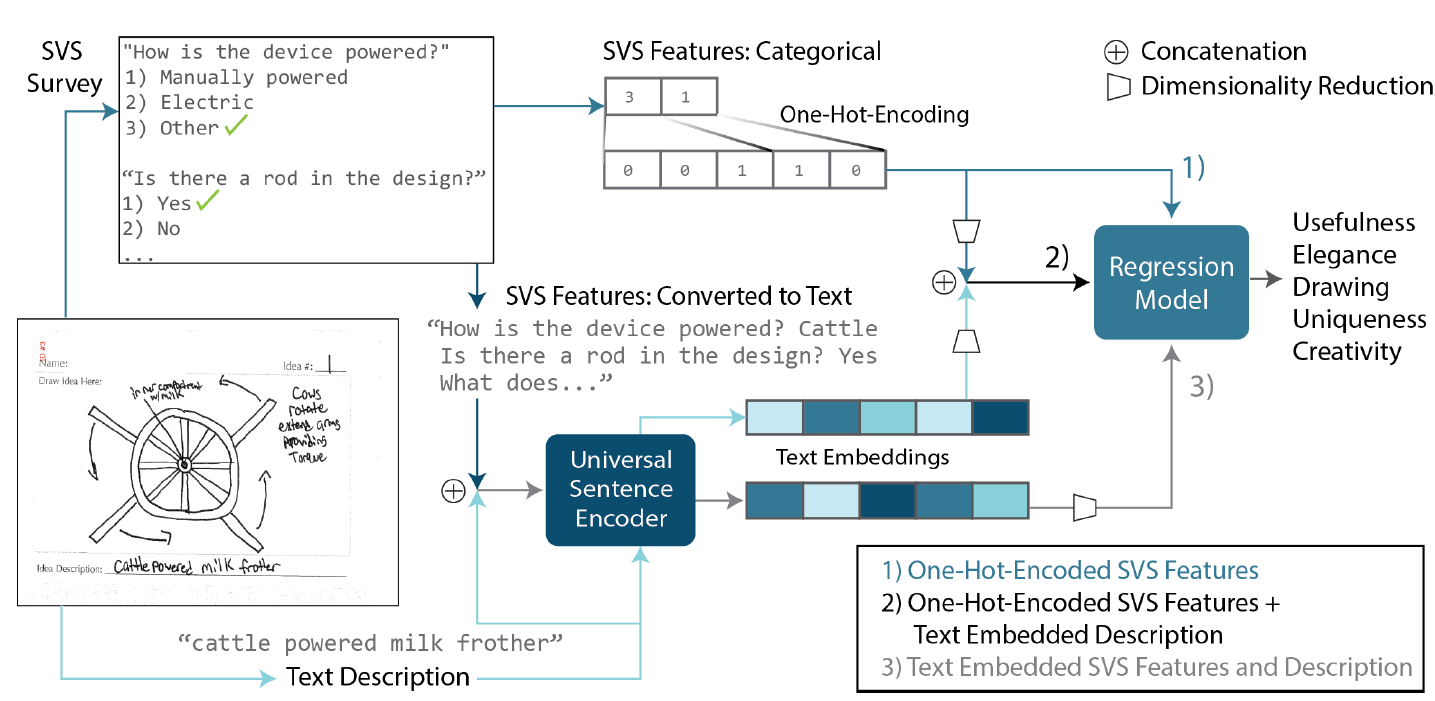
In Journal of Mechanical Design 2022
A picture is worth a thousand words, and in design metric estimation, a word may be worth a thousand features. Pictures are awarded this worth because they can encode a plethora of information. When evaluating designs, we aim to capture a range of information as well, including usefulness, uniqueness, and novelty of a design. The subjective nature of these concepts makes their evaluation difficult. Still, many attempts have been made and metrics developed to do so, because design evaluation is integral to the creation of novel solutions. The most common metrics used are the consensual assessment technique (CAT) and the Shah, Vargas-Hernandez, and Smith (SVS) method. While CAT is accurate and often regarded as the “gold standard,” it relies on using expert ratings, making CAT expensive and time-consuming. Comparatively, SVS is less resource-demanding, but often criticized as lacking sensitivity and accuracy. We utilize the complementary strengths of both methods through machine learning. This study investigates the possibility of using machine learning to predict expert creativity assessments from more accessible nonexpert survey results. The SVS method results in a text-rich dataset about a design. We utilize these textual design representations and the deep semantic relationships that words and sentences encode to predict more desirable design metrics, including CAT metrics. We demonstrate the ability of machine learning models to predict design metrics from the design itself and SVS survey information. We show that incorporating natural language processing (NLP) improves prediction results across design metrics, and that clear distinctions in the predictability of certain metrics exist. Our code and additional information about our work are available on the MIT DeCoDE Lab website.1
In Journal of Mechanical Design 2022
Typical engineering design tasks require the effort to modify designs iteratively until they meet certain constraints, i.e., performance or attribute requirements. Past work has proposed ways to solve the inverse design problem, where desired designs are directly generated from specified requirements, thus avoiding the trial and error process. Among those approaches, the conditional deep generative model shows great potential since (1) it works for complex high-dimensional designs and (2) it can generate multiple alternative designs given any range condition. In this work, we propose a conditional deep generative model, range-constrained generative adversarial network, to achieve automatic design synthesis subject to range constraints. The proposed model addresses the sparse conditioning issue in data-driven inverse design problems by introducing a label-aware self-augmentation approach. We also propose a new uniformity loss to ensure the generated designs evenly cover the given requirement range. Through a real-world example of constrained 3D shape generation, we show that the label-aware self-augmentation leads to an average improvement of 14% on the constraint satisfaction for generated 3D shapes, and the uniformity loss leads to a 125% average increase on the uniformity of generated shapes’ attributes. This work laid the foundation for data-driven inverse design problems where we consider range constraints and there are sparse regions in the condition space.
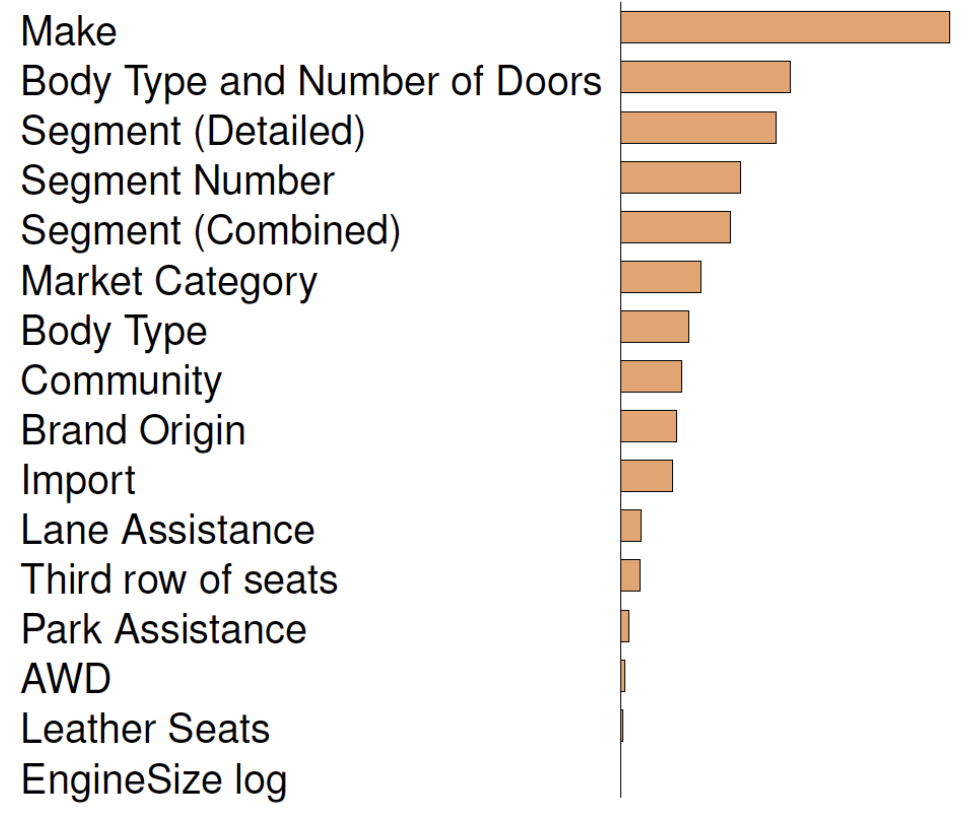
In ASME Open Journal of Engineering 2022
Understanding relationships between different products in a market system and predicting how changes in design impact their market position can be instrumental for companies to create better products. We propose a graph neural network-based method for modeling relationships between products, where nodes in a network represent products and edges represent their relationships. Our modeling enables a systematic way to predict the relationship links between unseen products for future years. When applied to a Chinese car market case study, our method based on an inductive graph neural network approach, GraphSAGE, yields double the link prediction performance compared to an existing network modeling method—exponential random graph model-based method for predicting the car co-consideration relationships. Our work also overcomes scalability and multiple data type-related limitations of the traditional network modeling methods by modeling a larger number of attributes, mixed categorical and numerical attributes, and unseen products. While a vanilla GraphSAGE requires a partial network to make predictions, we augment it with an “adjacency prediction model” to circumvent the limitation of needing neighborhood information. Finally, we demonstrate how insights obtained from a permutation-based interpretability analysis can help a manufacturer understand how design attributes impact the predictions of product relationships. Overall, this work provides a systematic data-driven method to predict the relationships between products in a complex network such as the car market.
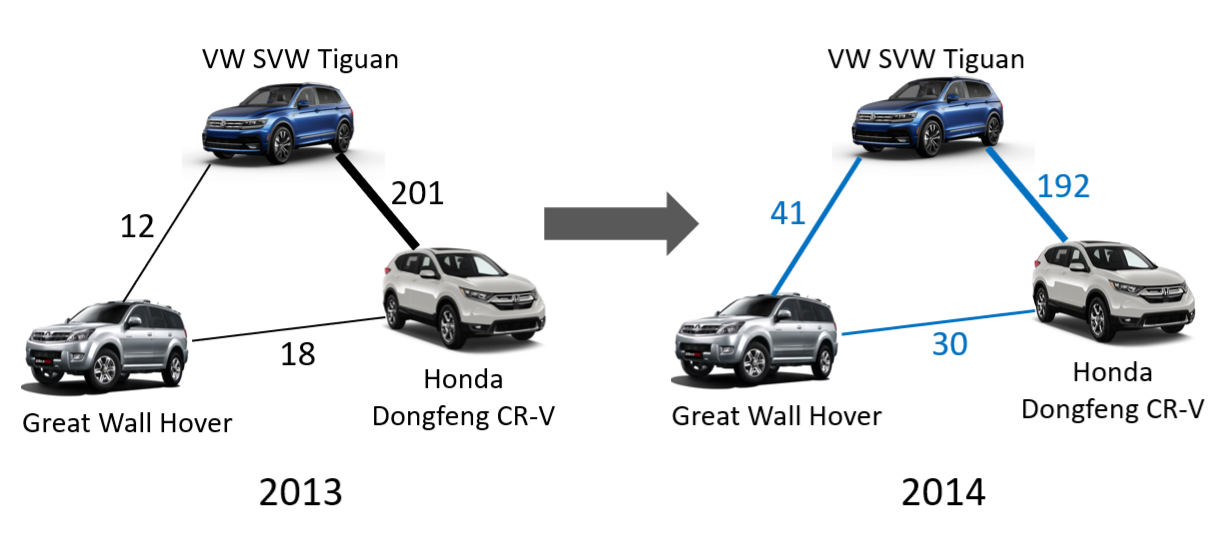
In Complexity 2022
Statistical network models have been used to study the competition among different products and how product attributes influence customer decisions. However, in existing research using network-based approaches, product competition has been viewed as binary (i.e., whether a relationship exists or not), while in reality, the competition strength may vary among products. In this paper, we model the strength of the product competition by employing a statistical network model, with an emphasis on how product attributes affect which products are considered together and which products are ultimately purchased by customers. We first demonstrate how customers’ considerations and choices can be aggregated as weighted networks. Then, we propose a weighted network modeling approach by extending the valued exponential random graph model to investigate the effects of product features and network structures on product competition relations. The approach that consists of model construction, interpretation, and validation is presented in a step-by-step procedure. Our findings suggest that the weighted network model outperforms commonly used binary network baselines in predicting product competition as well as market share. Also, traditionally when using binary network models to study product competitions and depending on the cutoff values chosen to binarize a network, the resulting estimated customer preferences can be inconsistent. Such inconsistency in interpreting customer preferences is a downside of binary network models but can be well addressed by the proposed weighted network model. Lastly, this paper is the first attempt to study customers’ purchase preferences (i.e., aggregated choice decisions) and car competition (i.e., customers’ co-consideration decisions) together using weighted directed networks.
In Collective Intelligence 2022
As the volume and complexity of distributed online work increases, the collaboration among people who have never worked together in the past is becoming increasingly necessary. Recent research has proposed algorithms to maximize the performance of such teams by grouping workers according to a set of predefined decision criteria. This approach micro-manages workers, who have no say in the team formation process. Depriving users of control over who they will work with stifles creativity, causes psychological discomfort and results in less-than-optimal collaboration results. In this work, we propose an alternative model, called Self-Organizing Teams (SOTs), which relies on the crowd of online workers itself to organize into effective teams. Supported but not guided by an algorithm, SOTs are a new human-centered computational structure, which enables participants to control, correct and guide the output of their collaboration as a collective. Experimental results, comparing SOTs to two benchmarks that do not offer user agency over the collaboration, reveal that participants in the SOTs condition produce results of higher quality and report higher teamwork satisfaction. We also find that, similarly to machine learning-based self-organization, human SOTs exhibit emergent collective properties, including the presence of an objective function and the tendency to form more distinct clusters of compatible teammates.
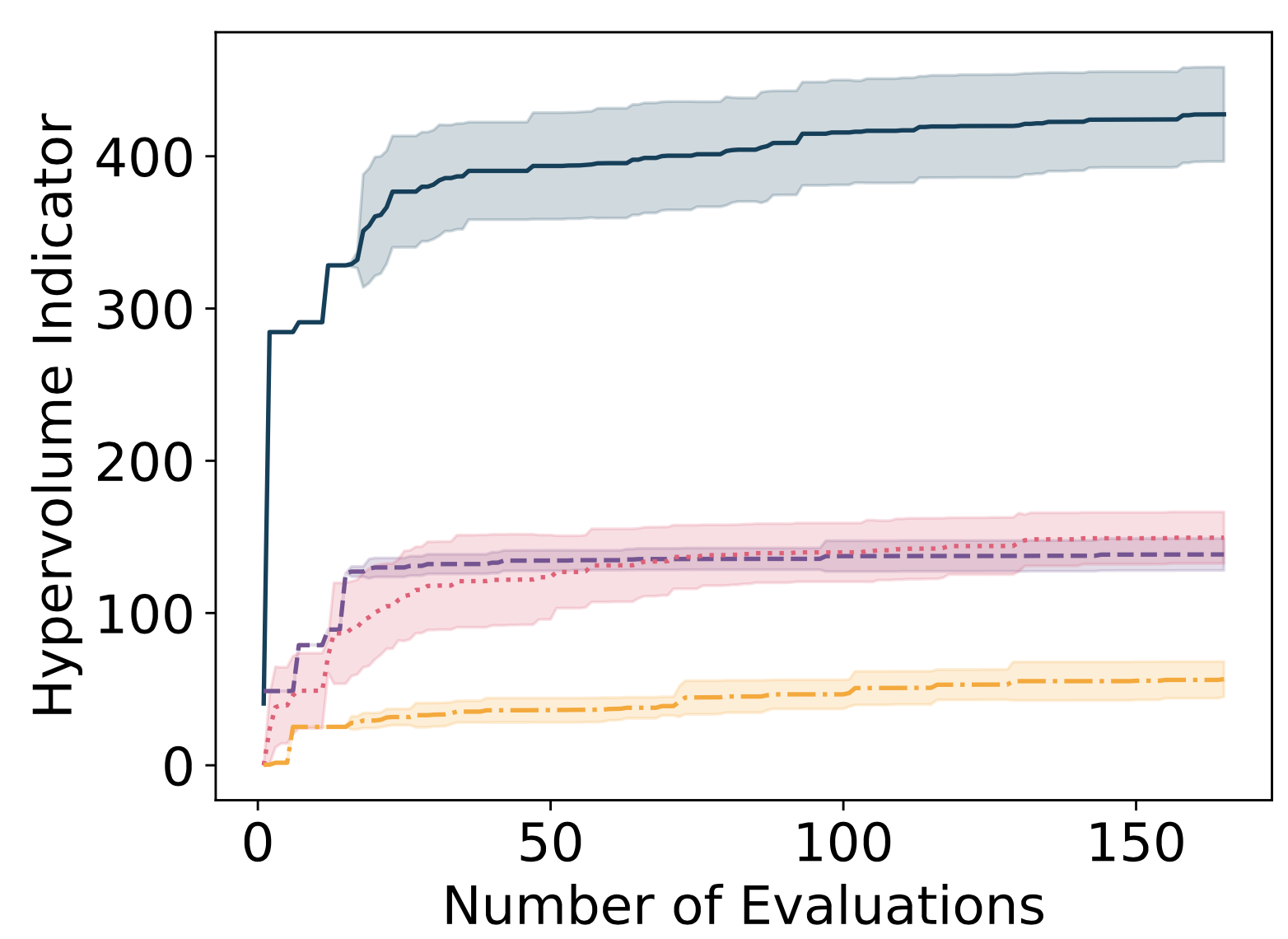
In Applied Soft Computing 2021
Multi-objective optimization is key to solving many Engineering Design problems, where design parameters are optimized for several performance indicators. However, optimization results are highly dependent on how the designs are parameterized. Researchers have shown that deep generative models can learn compact design representations, providing a new way of parameterizing designs to achieve faster convergence and improved optimization performance. Despite their success in capturing complex distributions, existing generative models face three challenges when used for design problems- (1) generated designs have limited design space coverage, (2) the generator ignores design performance, and 3) the new parameterization is unable to represent designs beyond training data. To address these challenges, we propose MO-PaDGAN, which adds a Determinantal Point Processes based loss function to the generative adversarial network to simultaneously model diversity and (multi-variate) performance. MO-PaDGAN can thus improve the performances and coverage of generated designs, and even generate designs with performances exceeding those from training data. When using MO-PaDGAN as a new parameterization in multi-objective optimization, we can discover much better Pareto fronts even though the training data do not cover those Pareto fronts. In a real-world multi-objective airfoil design example, we demonstrate that MO-PaDGAN achieves, on average, an over 180% improvement in the hypervolume indicator when compared to the vanilla GAN or other state-of-the-art parameterization methods.
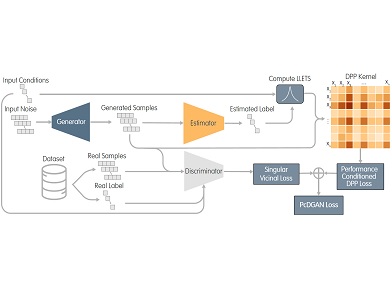
In ACM KDD 2021
Engineering design tasks often require synthesizing new designs that meet desired performance requirements. The conventional design process, which requires iterative optimization and performance evaluation, is slow and dependent on initial designs. Past work has used conditional generative adversarial networks (cGANs) to enable direct design synthesis for given target performances. However, most existing cGANs are restricted to categorical conditions. Recent work on Continuous conditional GAN (CcGAN) tries to address this problem, but still faces two challenges- 1) it performs poorly on non-uniform performance distributions, and 2) the generated designs may not cover the entire design space. We propose a new model, named Performance Conditioned Diverse Generative Adversarial Network (PcDGAN), which introduces a singular vicinal loss combined with a Determinantal Point Processes (DPP) based loss function to enhance diversity. PcDGAN uses a new self-reinforcing score called the Lambert Log Exponential Transition Score (LLETS) for improved conditioning. Experiments on synthetic problems and a real-world airfoil design problem demonstrate that PcDGAN outperforms state-of-the-art GAN models and improves the conditioning likelihood by 69% in an airfoil generation task and up to 78% in synthetic conditional generation tasks and achieves greater design space coverage. The proposed method enables efficient design synthesis and design space exploration with applications ranging from CAD model generation to metamaterial selection.
In IDETC 2021
In this paper, we present “BIKED,” a dataset comprised of 4500 individually designed bicycle models sourced from hundreds of designers. We expect BIKED to enable a variety of data-driven design applications for bicycles and support the development of data-driven design methods. The dataset is comprised of a variety of design information including assembly images, component images, numerical design parameters, and class labels. In this paper, we first discuss the processing of the dataset, then highlight some prominent research questions that BIKED can help address. Of these questions, we further explore the following in detail- 1) Are there prominent gaps in the current bicycle market and design space? We explore the design space using unsupervised dimensionality reduction methods. 2) How does one identify the class of a bicycle and what factors play a key role in defining it? We address the bicycle classification task by training a multitude of classifiers using different forms of design data and identifying parameters of particular significance through permutation-based interpretability analysis. 3) How does one synthesize new bicycles using different representation methods? We consider numerous machine learning methods to generate new bicycle models as well as interpolate between and extrapolate from existing models using Variational Autoencoders. The dataset is available along with referenced code.

In IDETC 2021
Modern machine learning techniques, such as deep neural networks, are transforming many disciplines ranging from image recognition to language understanding, by uncovering patterns in big data and making accurate predictions. They have also shown promising results for synthesizing new designs, which is crucial for creating products and enabling innovation. Generative models, including generative adversarial networks (GANs), have proven to be effective for design synthesis with applications ranging from product design to metamaterial design. These automated computational design methods can support human designers, who typically create designs by a time-consuming process of iteratively exploring ideas using experience and heuristics. However, there are still challenges remaining in automatically synthesizing ‘creative’ designs. GAN models, however, are not capable of generating unique designs, a key to innovation and a major gap in AI-based design automation applications. This paper proposes an automated method, named CreativeGAN, for generating novel designs. It does so by identifying components that make a design unique and modifying a GAN model such that it becomes more likely to generate designs with identified unique components. The method combines state-of-art novelty detection, segmentation, novelty localization, rewriting, and generative models for creative design synthesis. Using a dataset of bicycle designs, we demonstrate that the method can create new bicycle designs with unique frames and handles, and generalize rare novelties to a broad set of designs. Our automated method requires no human intervention and demonstrates a way to rethink creative design synthesis and exploration.

In IDETC 2021
Typical engineering design tasks require the effort to modify designs iteratively until they meet certain constraints, i.e., performance or attribute requirements. Past work has proposed ways to solve the inverse design problem, where desired designs are directly generated from specified requirements, thus avoid the trial and error process. Among those approaches, the conditional deep generative model shows great potential since 1) it works for complex high-dimensional designs and 2) it can generate multiple alternative designs given any condition. In this work, we propose a conditional deep generative model, Range-GAN, to achieve automatic design synthesis subject to range constraints. The proposed model addresses the sparse conditioning issue in data-driven inverse design problems by introducing a label-aware self-augmentation approach. We also propose a new uniformity loss to ensure generated designs evenly cover the given requirement range. Through a real-world example of constrained 3D shape generation, we show that the label-aware self-augmentation leads to an average improvement of 14% on the constraint satisfaction for generated 3D shapes, and the uniformity loss leads to a 125% average increase on the uniformity of generated shapes’ attributes. This work laid the foundation for data-driven inverse design problems where we consider range constraints and there are sparse regions in the condition space.
In IDETC 2021
A picture is worth a thousand words, and in design metric estimation, a word may be worth a thousand features. Pictures are awarded this worth because of their ability to encode a plethora of information. When evaluating designs, we aim to capture a range of information as well, information including usefulness, uniqueness, and novelty of a design. The subjective nature of these concepts makes their evaluation difficult. Despite this, many attempts have been made and metrics developed to do so, because design evaluation is integral to innovation and the creation of novel solutions. The most common metrics used are the consensual assessment technique (CAT) and the Shah, Vargas-Hernandez, and Smith (SVS) method. While CAT is accurate and often regarded as the “gold standard,” it heavily relies on using expert ratings as a basis for judgement, making CAT expensive and time consuming. Comparatively, SVS is less resource-demanding, but it is often criticized as lacking sensitivity and accuracy. We aim to take advantage of the distinct strengths of both methods through machine learning. More specifically, this study seeks to investigate the possibility of using machine learning to facilitate automated creativity assessment. The SVS method results in a text-rich dataset about a design. In this paper we utilize these textual design representations and the deep semantic relationships that words and sentences encode, to predict more desirable design metrics, including CAT metrics. We demonstrate the ability of machine learning models to predict design metrics from the design itself and SVS Survey information. We demonstrate that incorporating natural language processing (NLP) improves prediction results across all of our design metrics, and that clear distinctions in the predictability of certain metrics exist.
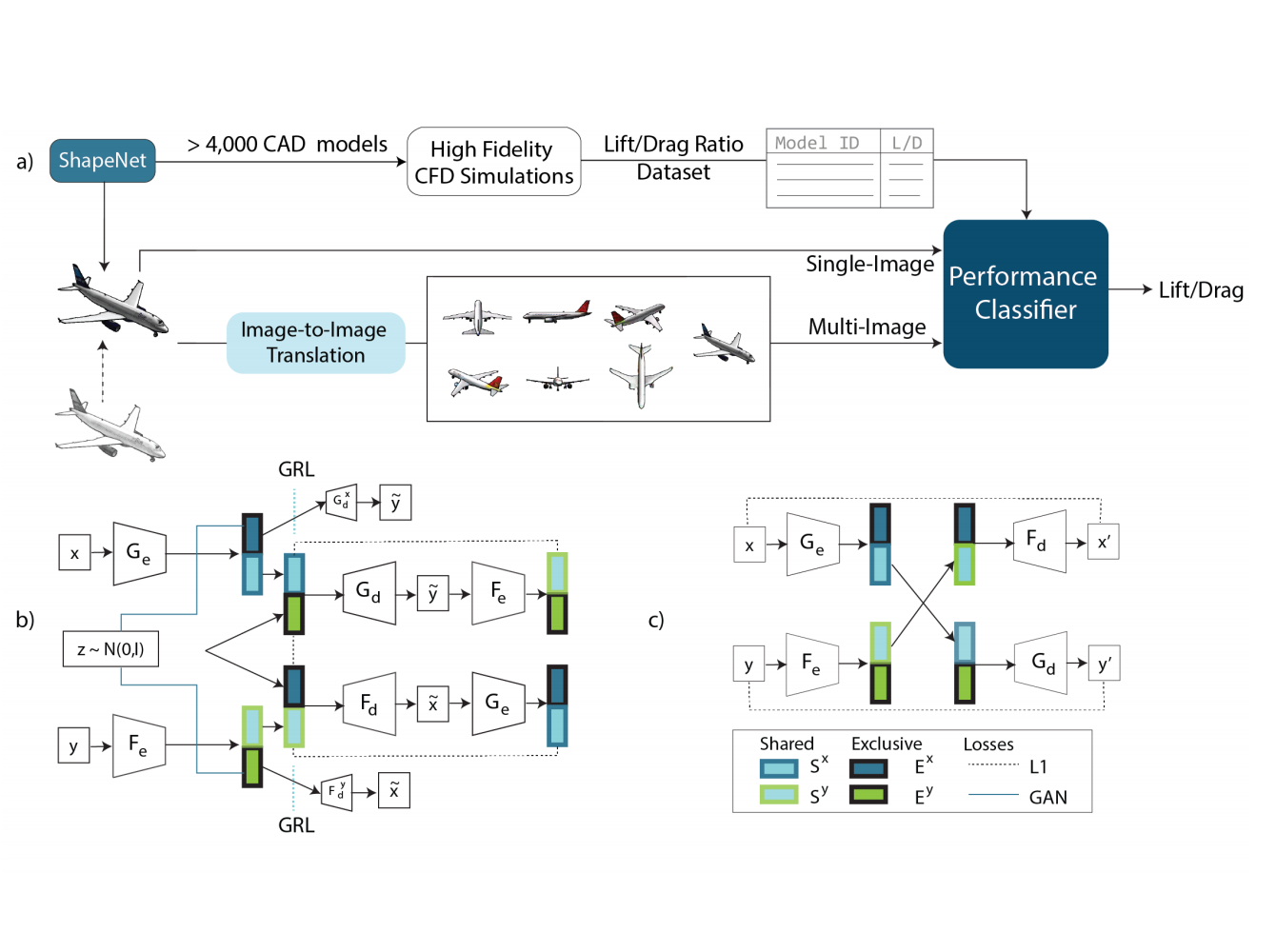
In IDETC 2021
Estimating the form and functional performance of a design in the early stages can be crucial for a designer for effective ideation Humans have an innate ability to guess the size, shape, and type of a design from a single view. The brain fills in the unknowns in a fraction of a second. However, humans may struggle with estimating the performance of designs in the early stages of the design process without making prototypes or doing back-of-the-envelope calculations. In contrast, machines need information about the full 3D model of a design to understand its structure. Machines can estimate the performance using pre-defined rules, expensive numerical simulations, or machine learning models. In this paper, we show how information about the form and functional performance of a design can be estimated from a single image using machine learning methods. Specifically, we leverage the image-to-image translation method to predict multiple projections of an image-based design. We then train deep neural network models on the predicted projections to provide estimates of design performance. We demonstrate the effectiveness of our method by predicting the aerodynamic performance from images of aircraft models. To estimate ground truth aero-dynamic performance, we run CFD simulations for 4045 3D aircraft models from the ShapeNet dataset and use their lift-to-drag ratio as the performance metric. Our results show that single images do carry information for both form and functional performance. From a single image, we are able to produce six additional images of a design in different orientations, with an average Structural Similarity Index score of 0.872. We also find image-translation methods provide a promising direction in estimating the performance of design. Using multiple images of a design (gathered through image-translation) to predict design performance yields a recall value of 47%, which is 14% higher than a base guess, and 3% higher than using a single image. Our work identifies the potential and provides a framework for using a single image to predict the form and functional performance of a design during the early-stage design process. Our code and additional information about our work are available.
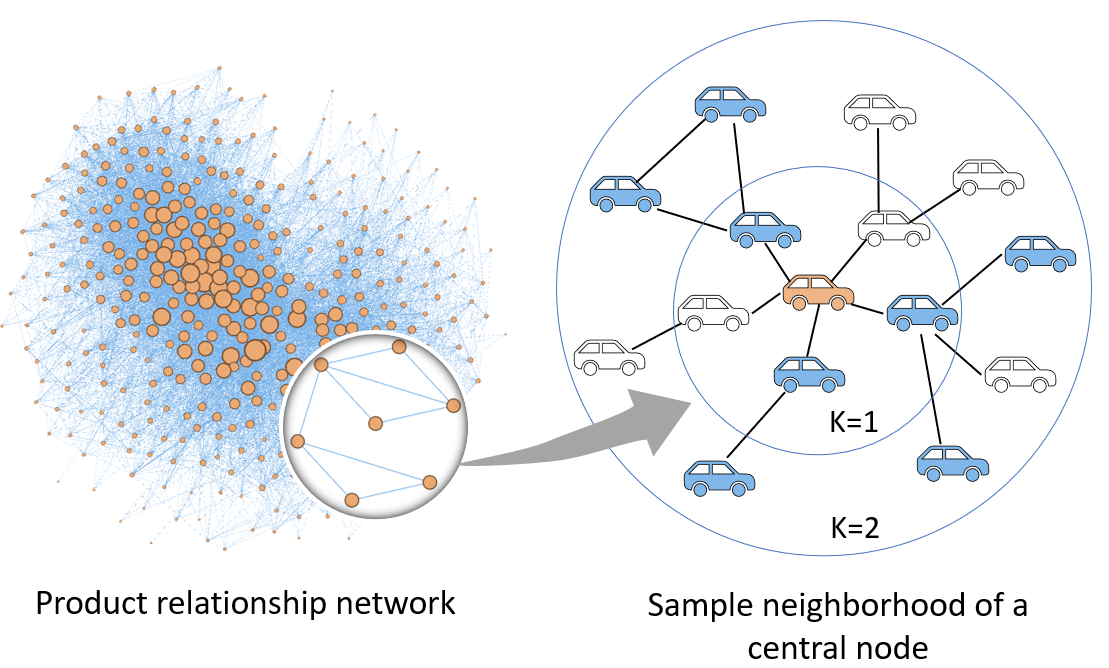
In IDETC 2021
Graph representation learning has revolutionized many artificial intelligence and machine learning tasks in recent years, ranging from combinatorial optimization, drug discovery, recommendation systems, image classification, social network analysis to natural language understanding. This paper shows their efficacy in modeling relationships between products and making predictions for unseen product networks. By representing products as nodes and their relationships as edges of a graph, we show how an inductive graph neural network approach, named GraphSAGE, can efficiently learn continuous representations for nodes and edges. These representations also capture product feature information such as price, brand, and engineering attributes. They are combined with a classification model for predicting the existence of a relationship between any two products. Using a case study of the Chinese car market, we find that our method yields double the F-1 score compared to an Exponential Random Graph Model-based method for predicting the co-consideration relationship between cars. While a vanilla Graph-SAGE requires a partial network to make predictions, we augment it with an ‘adjacency prediction model’ to circumvent this limitation. This enables us to predict product relationships when no neighborhood information is known. Finally, we demonstrate how a permutation-based interpretability analysis can provide insights on how design attributes impact the predictions of relationships between products. Overall, this work provides a systematic method to predict the relationships between products in a complex engineering system.
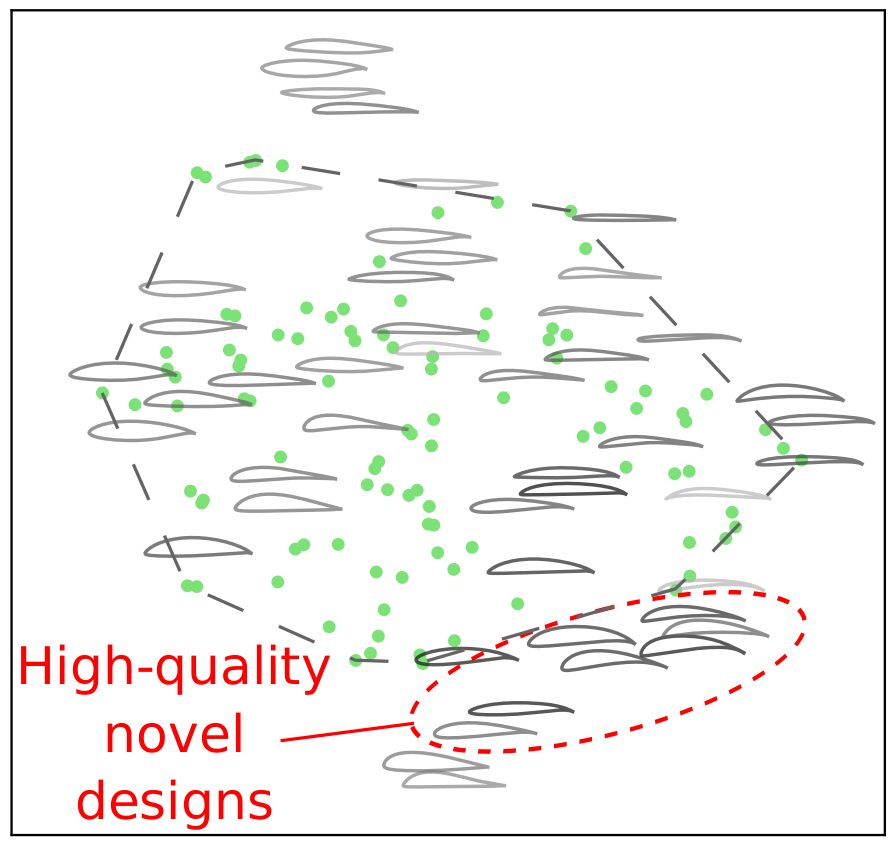
In Journal of Mechanical Design 2021
Deep generative models are proven to be a useful tool for automatic design synthesis and design space exploration. When applied in engineering design, existing generative models face three challenges- 1) generated designs lack diversity and do not cover all areas of the design space, 2) it is difficult to explicitly improve the overall performance or quality of generated designs, and 3) existing models generate do not generate novel designs, outside the domain of the training data. In this paper, we simultaneously address these challenges by proposing a new Determinantal Point Processes based loss function for probabilistic modeling of diversity and quality. With this new loss function, we develop a variant of the Generative Adversarial Network, named “Performance Augmented Diverse Generative Adversarial Network” or PaDGAN, which can generate novel high-quality designs with good coverage of the design space. Using three synthetic examples and one real-world airfoil design example, we demonstrate that PaDGAN can generate diverse and high-quality designs. In comparison to a vanilla Generative Adversarial Network, on average, it generates samples with 28% higher mean quality score with larger diversity and without the mode collapse issue. Unlike typical generative models that usually generate new designs by interpolating within the boundary of training data, we show that PaDGAN expands the design space boundary outside the training data towards high-quality regions. The proposed method is broadly applicable to many tasks including design space exploration, design optimization, and creative solution recommendation.
In ICML NDSML Workshop 2020
Bipartite b-matching, where agents on one side of a market are matched to one or more agents or items on the other, is widely used in many application areas such as healthcare, advertising, and general resource allocation. Traditionally, the primary goal of such models is to maximize a linear function of the constituent matches subject to some constraints. Recent work has studied a new goal of balancing whole-match diversity and economic efficiency, where the objective was to maximize coverage over some groups. Basic versions of this problem are solvable in polynomial time. In this work, we provide a generalized version of the problem, where the goal is to simultaneously maximize diversity along several features (e.g., country of citizenship, gender, skills) and show that it is NP-hard. We develop the first combinatorial algorithm that constructs provably-optimal diverse b-matchings in pseudo-polynomial time. We show that our method guarantees optimal solutions and is faster than state-of-the-art methods for a reviewer assignment application. We conclude with a discussion on key challenges in diverse matching domain.
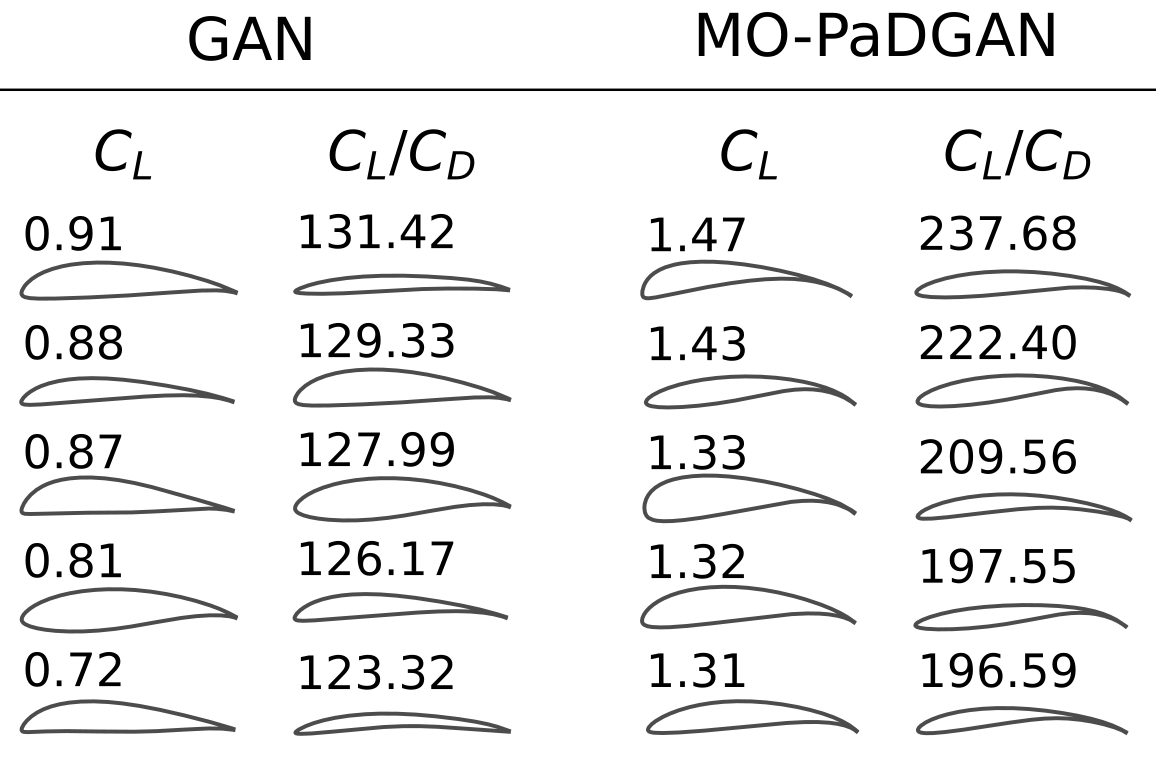
In ICML NDSML Workshop 2020
Deep generative models have proven useful for automatic design synthesis and design space exploration. However, they face three challenges when applied to engineering design- 1) generated designs lack diversity, 2) it is difficult to explicitly improve all the performance measures of generated designs, and 3) existing models generally do not generate high-performance novel designs, outside the domain of the training data. To address these challenges, we propose MO-PaDGAN, which contains a new Determinantal Point Processes based loss function for probabilistic modeling of diversity and performances. Through a real-world airfoil design example, we demonstrate that MO-PaDGAN expands the existing boundary of the design space towards high-performance regions and generates new designs with high diversity and performances exceeding training data.
In Journal of Mechanical Design 2020
Design variety metrics measure how much a design space is explored. This article proposes that a generalized class of entropy metrics based on Sharma–Mittal entropy offers advantages over existing methods to measure design variety. We show that an exemplar metric from Sharma–Mittal entropy, namely, the Herfindahl–Hirschman index for design (HHID) has the following desirable advantages over existing metrics (a) more accuracy- it better aligns with human ratings compared to existing and commonly used tree-based metrics for two new datasets; (b) higher sensitivity- it has higher sensitivity compared to existing methods when distinguishing between the variety of sets; (c) allows efficient optimization- it is a submodular function, which enables one to optimize design variety using a polynomial time greedy algorithm; and (d) generalizes to multiple metrics- many existing metrics can be derived by changing the parameters of this metric, which allows a researcher to fit the metric to better represent variety for new domains. This article also contributes a procedure for comparing metrics used to measure variety via constructing ground truth datasets from pairwise comparisons. Overall, our results shed light on some qualities that good design variety metrics should possess and the nontrivial challenges associated with collecting the data needed to measure those qualities.

In Computer Methods in Applied Mechanics and Engineering 2020
Metamaterials are emerging as a new paradigmatic material system to render unprecedented and tailorable properties for a wide variety of engineering applications. However, the inverse design of metamaterial and its multiscale system is challenging due to high-dimensional topological design space, multiple local optima, and high computational cost. To address these hurdles, we propose a novel data-driven metamaterial design framework based on deep generative modeling. A variational autoencoder (VAE) and a regressor for property prediction are simultaneously trained on a large metamaterial database to map complex microstructures into a low-dimensional, continuous, and organized latent space. We show in this study that the latent space of VAE provides a distance metric to measure shape similarity, enable interpolation between microstructures and encode meaningful patterns of variation in geometries and properties. Based on these insights, systematic data-driven methods are proposed for the design of microstructure, graded family, and multiscale system. For microstructure design, the tuning of mechanical properties and complex manipulations of microstructures are easily achieved by simple vector operations in the latent space. The vector operation is further extended to generate metamaterial families with a controlled gradation of mechanical properties by searching on a constructed graph model. For multiscale metamaterial systems design, a diverse set of microstructures can be rapidly generated using VAE for target properties at different locations and then assembled by an efficient graph-based optimization method to ensure compatibility between adjacent microstructures. We demonstrate our framework by designing both functionally graded and heterogeneous metamaterial systems that achieve desired distortion behaviors.

In Journal of Mechanical Design 2020
Data-driven design of mechanical metamaterials is an increasingly popular method to combat costly physical simulations and immense, often intractable, geometrical design spaces. Using a precomputed dataset of unit cells, a multiscale structure can be quickly filled via combinatorial search algorithms, and machine learning models can be trained to accelerate the process. However, the dependence on data induces a unique challenge- an imbalanced dataset containing more of certain shapes or physical properties can be detrimental to the efficacy of data-driven approaches. In answer, we posit that a smaller yet diverse set of unit cells leads to scalable search and unbiased learning. To select such subsets, we propose METASET, a methodology that (1) uses similarity metrics and positive semi-definite kernels to jointly measure the closeness of unit cells in both shape and property spaces and (2) incorporates Determinantal Point Processes for efficient subset selection. Moreover, METASET allows the trade-off between shape and property diversity so that subsets can be tuned for various applications. Through the design of 2D metamaterials with target displacement profiles, we demonstrate that smaller, diverse subsets can indeed improve the search process as well as structural performance. By eliminating inherent overlaps in a dataset of 3D unit cells created with symmetry rules, we also illustrate that our flexible method can distill unique subsets regardless of the metric employed. Our diverse subsets are provided publicly for use by any designer.
In IJCAI 2020
Bipartite b-matching, where agents on one side of a market are matched to one or more agents or items on the other, is a classical model that is used in myriad application areas such as healthcare, advertising, education, and general resource allocation. Traditionally, the primary goal of such models is to maximize a linear function of the constituent matches (e.g., linear social welfare maximization) subject to some constraints. Recent work has studied a new goal of balancing whole-match diversity and economic efficiency, where the objective is instead a monotone submodular function over the matching. Basic versions of this problem are solvable in polynomial time. In this work, we prove that the problem of simultaneously maximizing diversity along several features (e.g., country of citizenship, gender, skills) is NP-hard. To address this problem, we develop the first combinatorial algorithm that constructs provably-optimal diverse b-matchings in pseudo-polynomial time. We also provide a Mixed-Integer Quadratic formulation for the same problem and show that our method guarantees optimal solutions and takes less computation time for a reviewer assignment application.
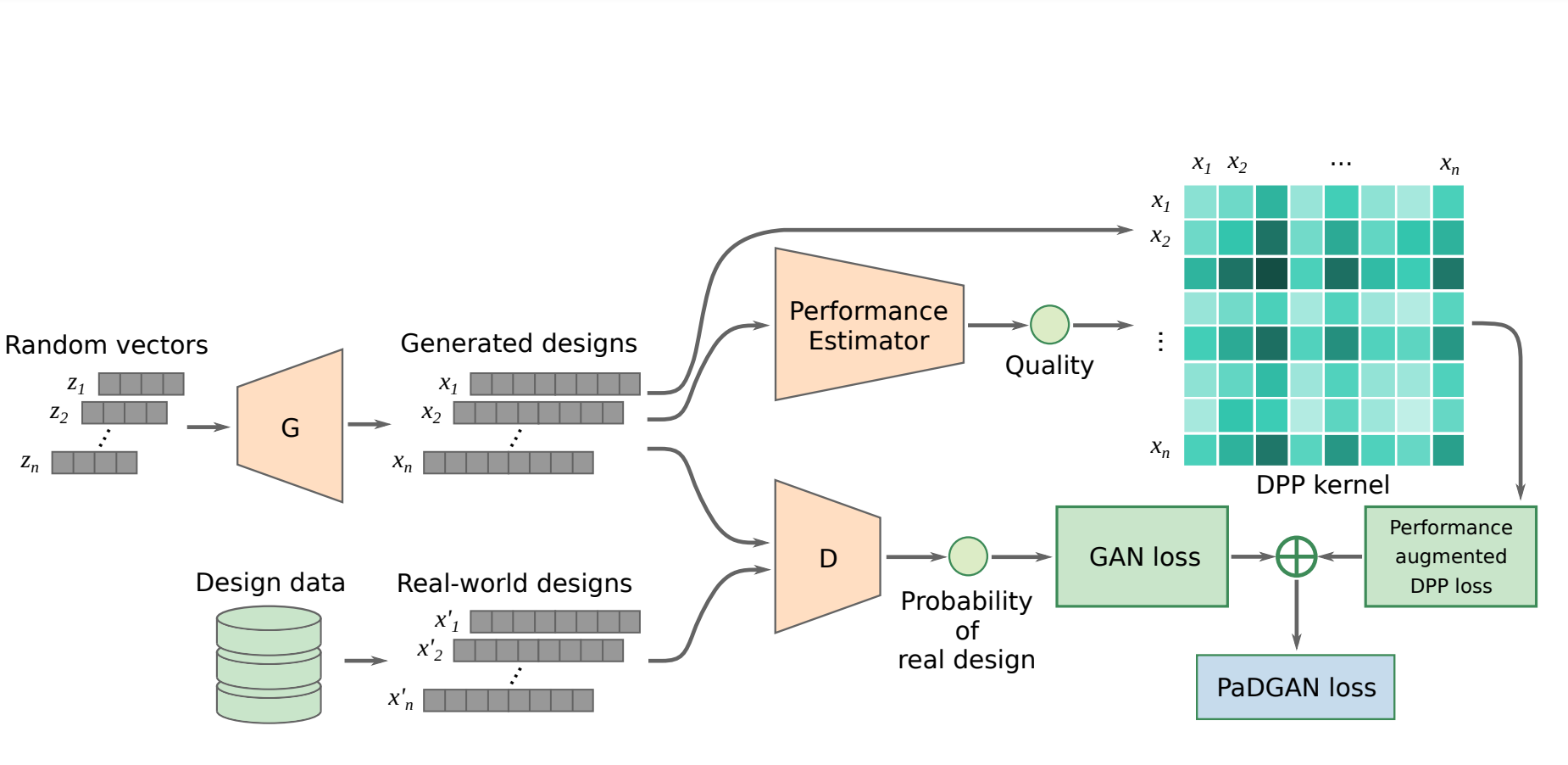
In IDETC 2020
Deep generative models are proven to be a useful tool for automatic design synthesis and design space exploration. When applied in engineering design, existing generative models face three challenges- 1) generated designs lack diversity and do not cover all areas of the design space, 2) it is difficult to explicitly improve the overall performance or quality of generated designs, and 3) existing models generate do not generate novel designs, outside the domain of the training data. In this paper, we simultaneously address these challenges by proposing a new Determinantal Point Processes based loss function for probabilistic modeling of diversity and quality. With this new loss function, we develop a variant of the Generative Adversarial Network, named “Performance Augmented Diverse Generative Adversarial Network” or PaDGAN, which can generate novel high-quality designs with good coverage of the design space. Using three synthetic examples and one real-world airfoil design example, we demonstrate that PaDGAN can generate diverse and high-quality designs. In comparison to a vanilla Generative Adversarial Network, on average, it generates samples with 28% higher mean quality score with larger diversity and without the mode collapse issue. Unlike typical generative models that usually generate new designs by interpolating within the boundary of training data, we show that PaDGAN expands the design space boundary outside the training data towards high-quality regions. The proposed method is broadly applicable to many tasks including design space exploration, design optimization, and creative solution recommendation.
In IDETC 2020
Statistical network models allow us to study the co-evolution between the products and the social aspects of a market system, by modeling these components and their interactions as graphs. In this paper, we study competition between different car models using network theory, with a focus on how product attributes (like fuel economy and price) affect which cars are considered together and which cars are finally bought by customers. Unlike past work, where most systems have been studied with the assumption that relationships between competitors are binary (i.e., whether a relationship exists or not), we allow relationships to take strengths (i.e., how strong a relationship is). Specifically, we use valued Exponential Random Graph Models and show that our approach provides a significant improvement over the baselines in predicting product co-considerations as well as in the validation of market share. This is also the first attempt to study aggregated purchase preference and car competition using valued directed networks.

In IDETC 2020 (Awarded "Papers of Distinction")
Data-driven design of mechanical metamaterials is an increasingly popular method to combat costly physical simulations and immense, often intractable, geometrical design spaces. Using a precomputed dataset of unit cells, a multiscale structure can be quickly filled via combinatorial search algorithms, and machine learning models can be trained to accelerate the process. However, the dependence on data induces a unique challenge- An imbalanced dataset containing more of certain shapes or physical properties than others can be detrimental to the efficacy of the approaches and any models built on those sets. In answer, we posit that a smaller yet diverse set of unit cells leads to scalable search and unbiased learning. To select such subsets, we propose METASET, a methodology that 1) uses similarity metrics and positive semi-definite kernels to jointly measure the closeness of unit cells in both shape and property space, and 2) incorporates Determinantal Point Processes for efficient subset selection. Moreover, METASET allows the trade-off between shape and property diversity so that subsets can be tuned for various applications. Through the design of 2D metamaterials with target displacement profiles, we demonstrate that smaller, diverse subsets can indeed improve the search process as well as structural performance. We also apply METASET to eliminate inherent overlaps in a dataset of 3D unit cells created with symmetry rules, distilling it down to the most unique families. Our diverse subsets are provided publicly for use by any designer.

In IDETC 2020
Design researchers have long sought to understand the mechanisms that support creative idea development. However, one of the key challenges faced by the design community is how to effectively measure the nebulous construct of creativity. The social science and engineering communities have adopted two vastly different approaches to solving this problem, both of which have been deployed throughout engineering design research. The goal of this paper was to compare and contrast these two approaches using design ratings of nearly 1000 engineering design ideas paired with a qualitative study with expert raters. The results of this study identify that while these two methods provide similar ratings of idea quality, there was a statistically significant negative relationship between these methods for ratings of idea novelty. Qualitative analysis of recordings from expert raters’ think aloud concept mapping points to potential sources of disagreement. In addition, the results show that while quasi-expert and expert raters provided similar ratings of design novelty, there was not significant agreement between these groups for ratings of design quality. The results of this study provide guidance for the deployment of idea ratings in engineering design research and evidence for the development and potential modification of engineering design creativity metrics.
In Journal of Mechanical Design 2020
Collaborative work often benefits from having teams or organizations with heterogeneous members. In this paper, we present a method to form such diverse teams from people arriving sequentially over time. We define a monotone submodular objective function that combines the diversity and quality of a team and proposes an algorithm to maximize the objective while satisfying multiple constraints. This allows us to balance both how diverse the team is and how well it can perform the task at hand. Using crowd experiments, we show that, in practice, the algorithm leads to large gains in team diversity. Using simulations, we show how to quantify the additional cost of forming diverse teams and how to address the problem of simultaneously maximizing diversity for several attributes (e.g., country of origin and gender). Our method has applications in collaborative work ranging from team formation, the assignment of workers to teams in crowdsourcing, and reviewer allocation to journal papers arriving sequentially. Our code is publicly accessible for further research.
Ph.D. thesis
The primary objective of this dissertation is to investigate research methods to answer the question- ``How (and why) does one measure, learn and optimize novelty and diversity of a set of items?" The computational models we develop to answer this question also provide foundational mathematical techniques to throw light on the following three questions- 1. How does one reliably measure the creativity of ideas? 2. How does one form teams to evaluate design ideas? 3. How does one filter good ideas out of hundreds of submissions? Solutions to these questions are key to enable the effective processing of a large collection of design ideas generated in a design contest. In the first part of the dissertation, we discuss key qualities needed in design metrics and propose new diversity and novelty metrics for judging design products. We show that the proposed metrics have higher accuracy and sensitivity compared to existing alternatives in literature. To measure the novelty of a design item, we propose learning from human subjective responses to derive low dimensional triplet embeddings. To measure diversity, we propose an entropy-based diversity metric, which is more accurate and sensitive than benchmarks. In the second part of the dissertation, we introduce the bipartite b-matching problem and argue the need for incorporating diversity in the objective function for matching problems. We propose new submodular and supermodular objective functions to measure diversity and develop multiple matching algorithms for diverse team formation in offline and online cases. Finally, in the third part, we demonstrate filtering and ranking of ideas using diversity metrics based on Determinantal Point Processes as well as submodular functions. In real-world crowd experiments, we demonstrate that such ranking enables increased efficiency in filtering high-quality ideas compared to traditionally used methods.
In C&C 2019
Exposing people to concepts created by others can inspire novel combinations of concepts, or conversely, lead people to simply emulate others. But how does the type of exposure affect creative outcomes in online collaboration where dyads interact for short tasks? In this paper, we study the creative outcomes of dyads working together online on a slogan writing task under different types of interactions- providing both the partner's idea and their explanation for that idea, enabling synchronous chat, and only exposing a person to their partner's idea without any explanation. We measure the creative outcome and define text-similarity-based metrics (e.g., mimicry, convergence, and fixation) to disentangle the interactions. The results show that having partners explain their ideas leads to largest improvement in creative outcome. In contrast, participants who chatted were more likely to reach convergence on their final slogans. Our work sheds lights on how different online interactions may create trade-offs in creative collaborations.
In IDETC 2019
In this paper, we propose a new design variety metric based on the Herfindahl index. We also propose a practical procedure for comparing variety metrics via the construction of ground truth datasets from pairwise comparisons by experts. Using two new datasets, we show that this new variety measure aligns with human ratings more than some existing and commonly used tree-based metrics. This metric also has three main advantages over existing metrics- a) It is a super-modular function, which enables us to optimize design variety using a polynomial time greedy algorithm. b) The parametric nature of this metric allows us to fit the metric to better represent variety for new domains. c) It has higher sensitivity in distinguishing between variety of sets of randomly selected designs than existing methods. Overall, our results shed light on some qualities that good design variety metrics should possess and the non-trivial challenges associated with collecting the data needed to measure those qualities.
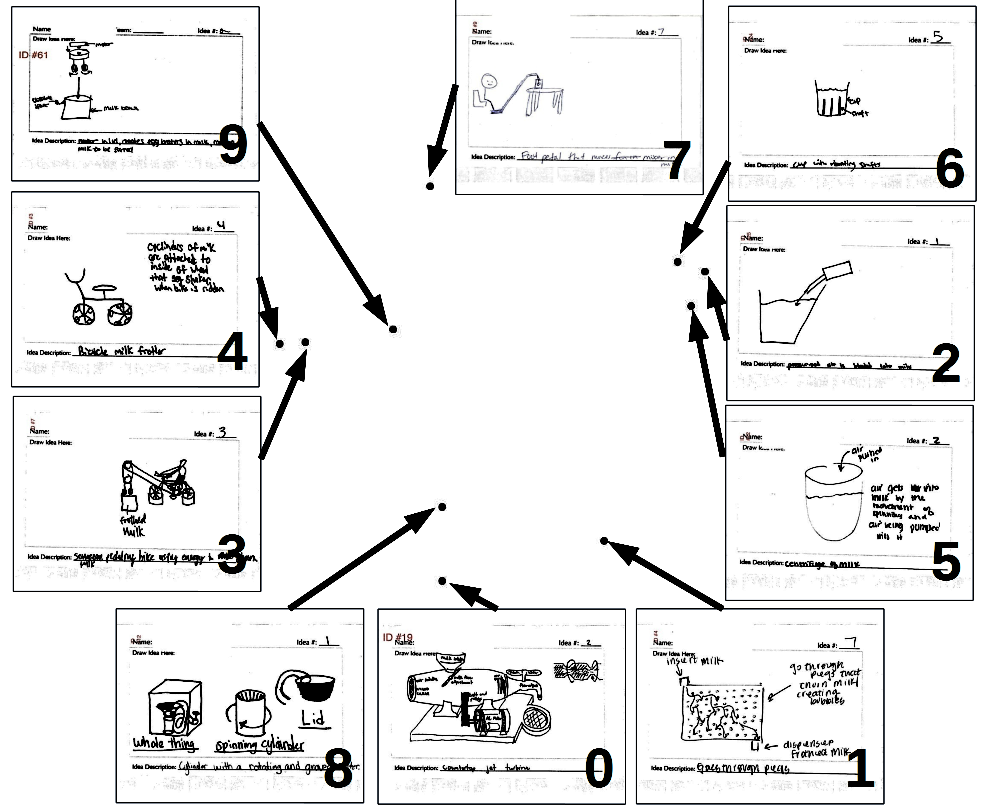
In Journal of Mechanical Design 2019
Assessing similarity between design ideas is an inherent part of many design evaluations to measure novelty. In such evaluation tasks, humans excel at making mental connections among diverse knowledge sets to score ideas on their uniqueness. However, their decisions about novelty are often subjective and difficult to explain. In this paper, we demonstrate a way to uncover human judgment of design idea similarity using two-dimensional (2D) idea maps. We derive these maps by asking participants for simple similarity comparisons of the form “Is idea A more similar to idea B or to idea C?” We show that these maps give insight into the relationships between ideas and help understand the design domain. We also propose that novel ideas can be identified by finding outliers on these idea maps. To demonstrate our method, we conduct experimental evaluations on two datasets—colored polygons (known answer) and milk frother sketches (unknown answer). We show that idea maps shed light on factors considered by participants in judging idea similarity and the maps are robust to noisy ratings. We also compare physical maps made by participants on a white-board to their computationally generated idea maps to compare how people think about spatial arrangement of design items. This method provides a new direction of research into deriving ground truth novelty metrics by combining human judgments and computational methods.
In Design Science 2018
Bisociative knowledge discovery is an approach that combines elements from two or more ‘incompatible’ domains to generate creative solutions and insight. Inspired by Koestler’s notion of bisociation, in this paper we propose a computational framework for the discovery of new connections between domains to promote creative discovery and inspiration in design. Specifically, we propose using topic models on a large collection of unstructured text ideas from multiple domains to discover creative sources of inspiration. We use these topics to generate a Bisociative Information Network – a graph that captures conceptual similarity between ideas – that helps designers find creative links within that network. Using a dataset of thousands of ideas from OpenIDEO, an online collaborative community, our results show usefulness of representing conceptual bridges through collections of words (topics) in finding cross-domain inspiration. We show that the discovered links between domains, whether presented on their own or via ideas they inspired, are perceived to be more novel and can also be used as creative stimuli for new idea generation.
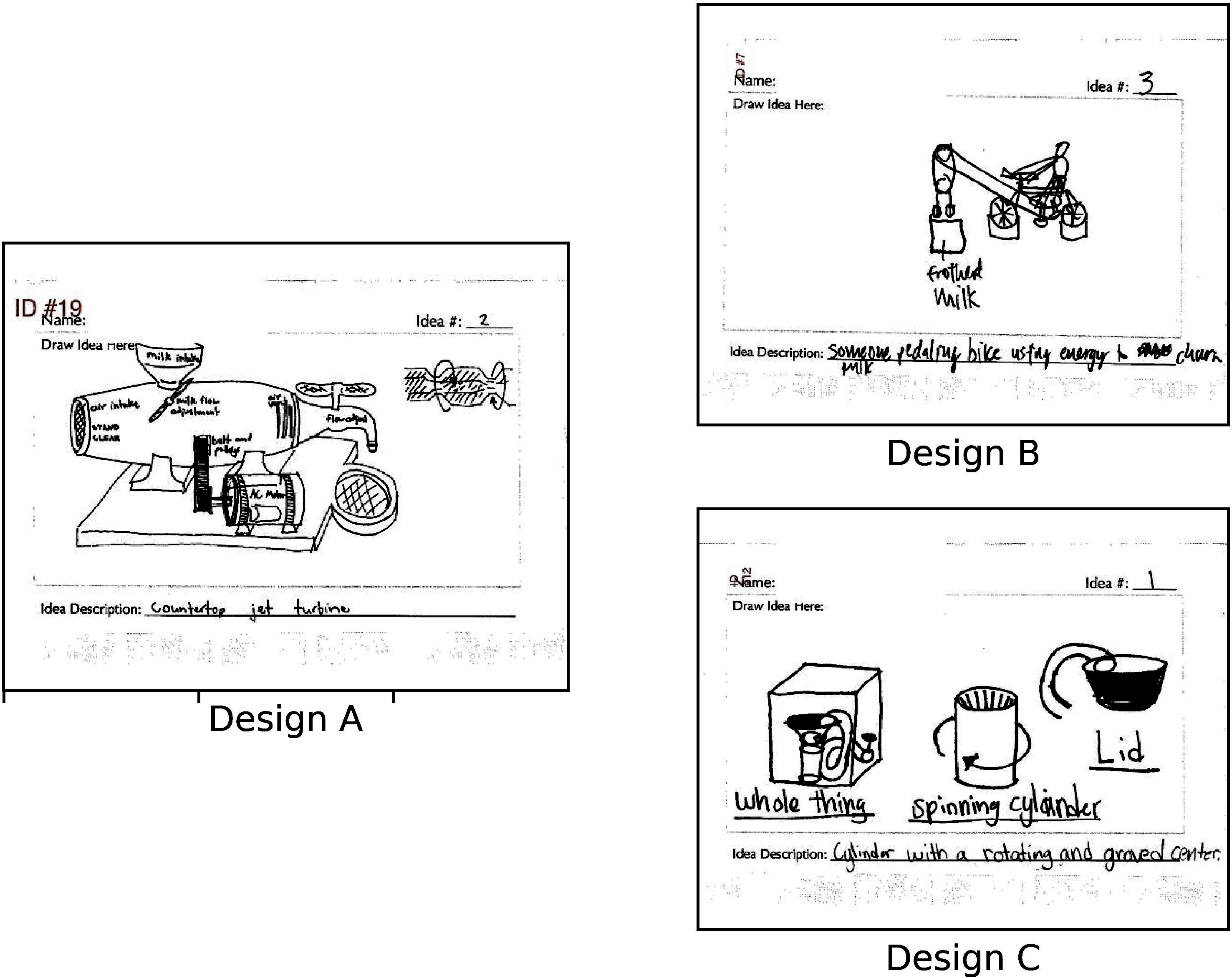
In IDETC 2018
Assessing similarity between design ideas is an inherent part of many design evaluations to measure novelty. In such evaluation tasks, humans excel at making mental connections among diverse knowledge sets and scoring ideas on their uniqueness. However, their decisions on novelty are often subjective and difficult to explain. In this paper, we demonstrate a way to uncover human judgment of design idea similarity using two dimensional idea maps. We derive these maps by asking humans for simple similarity comparisons of the form “Is idea A more similar to idea B or to idea C?” We show that these maps give insight into the relationships between ideas and help understand the domain. We also propose that the novelty of ideas can be estimated by measuring how far items are on these maps. We demonstrate our methodology through the experimental evaluations on two datasets of colored polygons (known answer) and milk frothers (unknown answer) sketches. We show that these maps shed light on factors considered by raters in judging idea similarity. We also show how maps change when less data is available or false/noisy ratings are provided. This method provides a new direction of research into deriving ground truth novelty metrics by combining human judgments and computational methods.
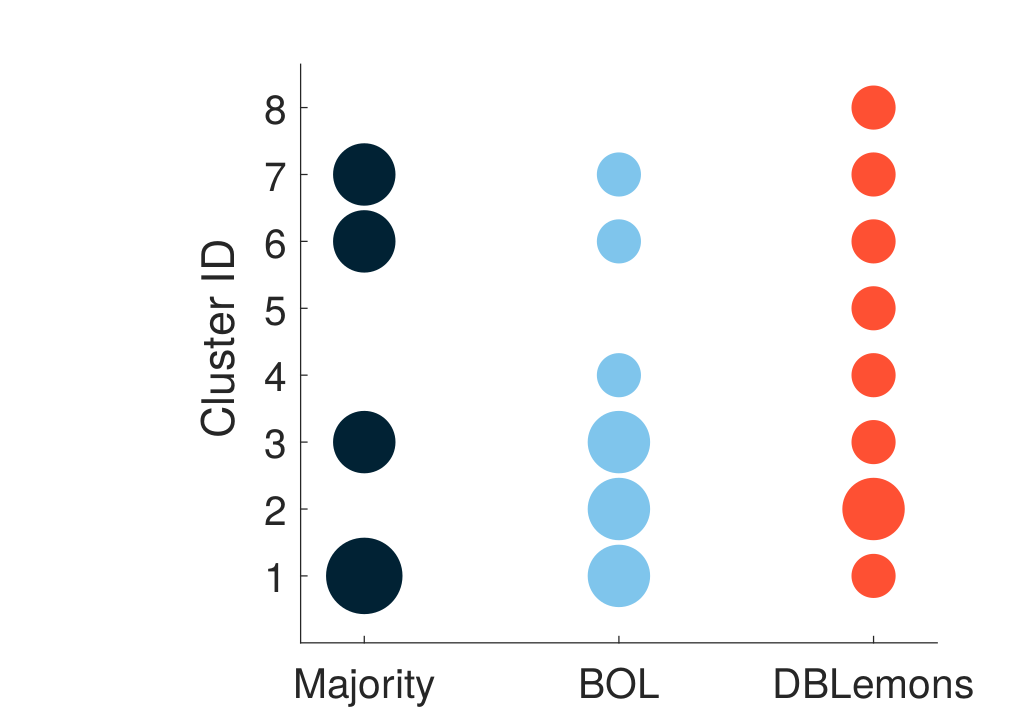
In CSCW 2018
Following successful crowd ideation contests, organizations in search of the "next big thing" are left with hundreds of ideas. Expert-based idea filtering is lengthy and costly; therefore, crowd-based strategies are often employed. Unfortunately, these strategies typically (1) do not separate the mediocre from the excellent, and (2) direct all the attention to certain idea concepts, while others starve. We introduce DBLemons - a crowd-based idea filtering strategy that addresses these issues by (1) asking voters to identify the worst rather than the best ideas using a "bag of lemons'' voting approach, and (2) by exposing voters to a wider idea spectrum, thanks to a dynamic diversity-based ranking system balancing idea quality and coverage. We compare DBLemons against two state-of-the-art idea filtering strategies in a real-world setting. Results show that DBLemons is more accurate, less time-consuming, and reduces the idea space in half while still retaining 94% of the top ideas.
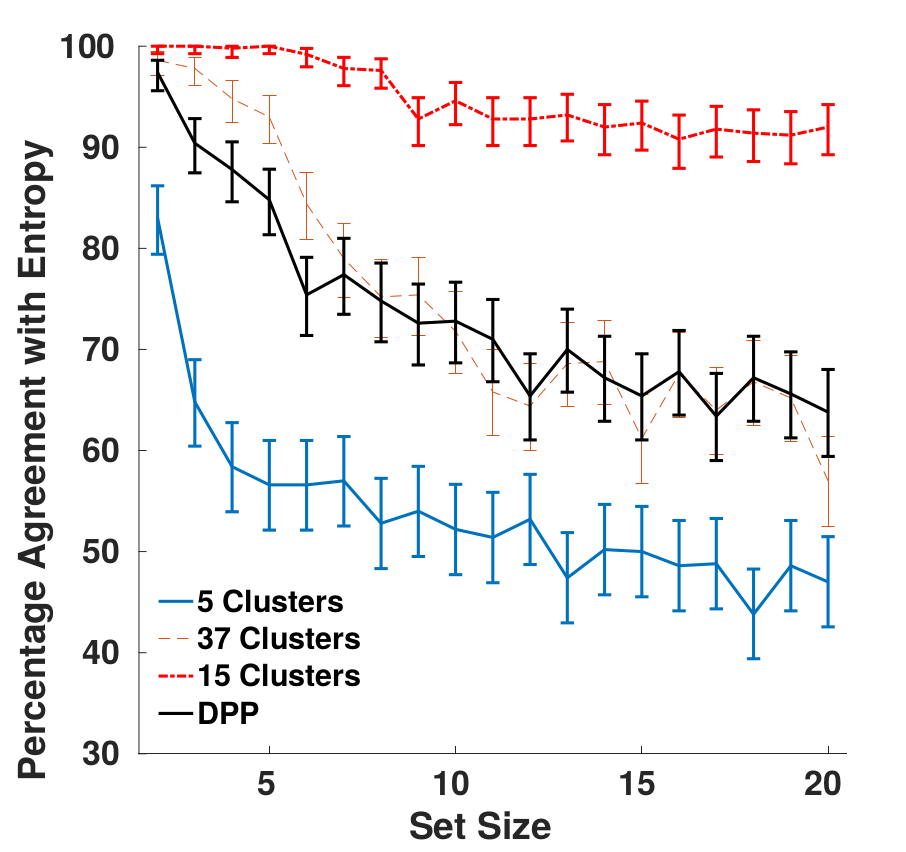
In Journal of Mechanical Design 2018
When selecting ideas or trying to find inspiration, designers often must sift through hundreds or thousands of ideas. This paper provides an algorithm to rank design ideas such that the ranked list simultaneously maximizes the quality and diversity of recommended designs. To do so, we first define and compare two diversity measures using determinantal point processes (DPP) and additive submodular functions. We show that DPPs are more suitable for items expressed as text and that a greedy algorithm diversifies rankings with both theoretical guarantees and empirical performance on what is otherwise an NP-Hard problem. To produce such rankings, this paper contributes a novel way to extend quality and diversity metrics from sets to permutations of ranked lists. These rank metrics open up the use of multi-objective optimization to describe trade-offs between diversity and quality in ranked lists. We use such trade-off fronts to help designers select rankings using indifference curves. However, we also show that rankings on trade-off front share a number of top-ranked items; this means reviewing items (for a given depth like the top ten) from across the entire diversity-to-quality front incurs only a marginal increase in the number of designs considered. While the proposed techniques are general purpose enough to be used across domains, we demonstrate concrete performance on selecting items in an online design community (OpenIDEO), where our approach reduces the time required to review diverse, high-quality ideas from around 25 h to 90 min. This makes evaluation of crowd-generated ideas tractable for a single designer. Our code is publicly accessible for further research.
In IJCAI 2017
Bipartite matching, where agents on one side of a market are matched to agents or items on the other, is a classical problem in computer science and economics, with widespread application in healthcare, education, advertising, and general resource allocation. A practitioner's goal is typically to maximize a matching market's economic efficiency, possibly subject to some fairness requirements that promote equal access to resources. A natural balancing act exists between fairness and efficiency in matching markets, and has been the subject of much research. In this paper, we study a complementary goal-- balancing diversity and efficiency--in a generalization of bipartite matching where agents on one side of the market can be matched to sets of agents on the other. Adapting a classical definition of the diversity of a set, we propose a quadratic programming-based approach to solving a super-modular minimization problem that balances diversity and total weight of the solution. We also provide a scalable greedy algorithm with theoretical performance bounds. We then define the price of diversity , a measure of the efficiency loss due to enforcing diversity, and give a worst-case theoretical bound. Finally, we demonstrate the efficacy of our methods on three real-world datasets, and show that the price of diversity is not bad in practice. Our code is publicly accessible for further research.
In CSCW 2017
This paper describes how to find or filter high-quality ideas submitted by members collaborating together in online communities. Typical means of organizing community submissions, such as aggregating community or crowd votes, suffer from the cold-start problem, the rich-get-richer problem, and the sparsity problem. To circumvent those, our approach learns a ranking model that combines 1) community feedback, 2) idea uniqueness, and 3) text features?e.g., readability, coherence, semantics, etc. This model can then rank order submissions by expected quality, supporting community members in finding content that can inspire them and improve collaboration among members. As illustrative example, we demonstrate the model on OpenIDEO--a collaborative community where high-quality submissions are rewarded by winning design challenges. We find that the proposed ranking model finds winning ideas more effectively than existing ranking techniques (comment sorting), as measured using both Discounted Cumulative Gain and human perceptions of idea quality. We also identify the elements of winning ideas that were highly predictive of subsequent success- 1) engagement with community feedback, 2) submission length, and 3) a submission's uniqueness. Ultimately, our approach enables community members and managers to more effectively manage creative stimuli created by large collaborative communities.
In IDETC 2016
This paper describes how to select diverse, high quality, representative ideas when the number of ideas grow beyond what a person can easily organize. When designers have a large number of ideas, it becomes prohibitively difficult for them to explore the scope of those ideas and find inspiration. We propose a computational method to recommend a diverse set of representative and high quality design ideas and demonstrate the results for design challenges on OpenIDEO — a web-based online design community. Diversity of these ideas is defined using topic modeling to identify latent concepts within the text while the quality is measured from user feedback. Multi-objective optimization then trades off quality and diversity of ideas. The results show that our approach attains a diverse set of high quality ideas and that the proposed method is applicable to multiple domains.
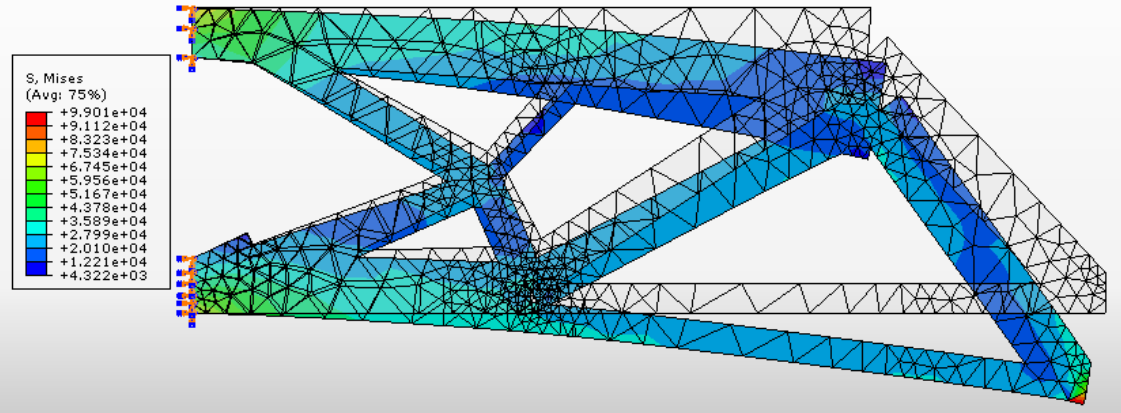
In Applied Soft Computing 2016
This paper presents a constructive solid geometry based representation scheme for structural topology optimization. The proposed scheme encodes the topology using position of few joints and width of segments connecting them. Union of overlapping rectangular primitives is calculated using constructive solid geometry technique to obtain the topology. A valid topology in the design domain is ensured by representing the topology as a connected simple graph of nodes. A graph repair operator is applied to ensure a physically meaningful connected structure. The algorithm is integrated with single and multi-objective genetic algorithm and its performance is compared with those of other methods like SIMP. The multi-objective analysis provides the trade-off front between compliance and material availability, unveiling common design principles among optimized solutions. The proposed method is generic and can be easily extended to any two or three-dimensional topology optimization problem by using different shape primitives.

In CORE 2016
Irregular track geometry can incite undesirable vehicle dynamic response modes that increase track loading, reduce component life, and increase the risk of vehicle derailment. Geometric irregularities in track can typically be identified by monitoring wagon-track dynamic activity. Instrumented ore car (IOC) continuous monitoring systems measure a range of response metrics including spring nest deflection, which under nominal service loads and speeds, are a key indicator of geometry induced wagon-track dynamic activity. This study demonstrates the benefits of predictive maintenance approaches facilitated by the trending of continuously measured performance data, as developed for Rio Tinto’s heavy haul iron ore railway network in Australia’s Pilbara region. Predictive maintenance approaches facilitate the improvement of maintenance planning operations resulting in better track surface and line condition, reduced risk to infrastructure and rolling-stock as well a reduction in the need for reactive temporary speed restrictions (TSRs) and unscheduled maintenance activities.

In IHHA 2015
Settlement of railway track caused by the cyclic loading and vibration of network traffic, leads to degradation of geometry which therefore needs to be systematically maintained. Tamping is an effective maintenance procedure which repacks ballast particles in order to restore the correct geometrical position of track. The goal of this study has been the development of a tool to evaluate the effectiveness of track tamping. Continuously measured performance data from instrumented ore cars (IOCs) is used for the analysis. The wagon-track dynamic interaction is studied by investigating the dynamic behaviour of the IOC's suspension system. The wagon suspension response data is then utilized to identify locations where tamping has been effective or ineffective. A maintenance planning system is used to conduct predictive modelling and forecast wagon dynamic responses to identify priority tamping locations. Using linear regression, the rate of track degradation over time and locations where tamping is required can be identified. The results of this work facilitate the development and improvement of maintenance planning operations. Particular tamping strategies or equipment that has had an adverse impact on track can also be identified. It therefore becomes feasible to develop a preventative tamping program that reduces surface and lining requirements and consequently the need for the introduction of temporary speed restrictions.
In Applied Soft Computing 2013
Selection of players for a sports team within a finite budget is a complex task which can be viewed as a constrained multi-objective optimization and a multiple criteria decision making problem. The task is specially challenging for the game of cricket where a team requires players who are efficient in multiple roles. In the formation of a good and successful cricket team, batting strength and bowling strength of a team are major factors affecting its performance and an optimum trade-off needs to be reached. We propose a novel gene representation scheme and a multi-objective approach using the NSGA-II algorithm to optimize the overall batting and bowling strength of a team with 11 players as variables. Fielding performance and a number of other cricketing criteria are also used in the optimization and decision-making process. Using the information from the trade-off front obtained, a multi-criteria decision making approach is then proposed for the final selection of team. Case studies using a set of players auctioned in Indian Premier League (IPL) 4th edition are illustrated and players’ current statistical data is used to define performance indicators. The proposed computational techniques are ready to be extended according to individualistic preferences of different franchises and league managers in order to form a preferred team within the budget constraints. It is also shown how such an analysis can help in dynamic auction environments, like selecting a team under player-by-player auction. The methodology is generic and can be easily extended to other sports like American football, baseball and other league games.
In Soft Computing 2013
A multi-objective vehicle path planning method has been proposed to optimize path length, path safety, and path smoothness using the elitist non-dominated sorting genetic algorithm—a well-known soft computing approach. Four different path representation schemes that begin their coding from the start point and move one grid at a time towards the destination point are proposed. Minimization of traveled distance and maximization of path safety are considered as objectives of this study while path smoothness is considered as a secondary objective. This study makes an extensive analysis of a number of issues related to the optimization of path planning task-handling of constraints associated with the problem, identifying an efficient path representation scheme, handling single versus multiple objectives, and evaluating the proposed algorithm on large-sized grids and having a dense set of obstacles. The study also compares the performance of the proposed algorithm with an existing GA-based approach. The evaluation of the proposed procedure against extreme conditions having a dense (as high as 91 %) placement of obstacles indicates its robustness and efficiency in solving complex path planning problems. The paper demonstrates the flexibility of evolutionary computing approaches in dealing with large-scale and multi-objective optimization problems.
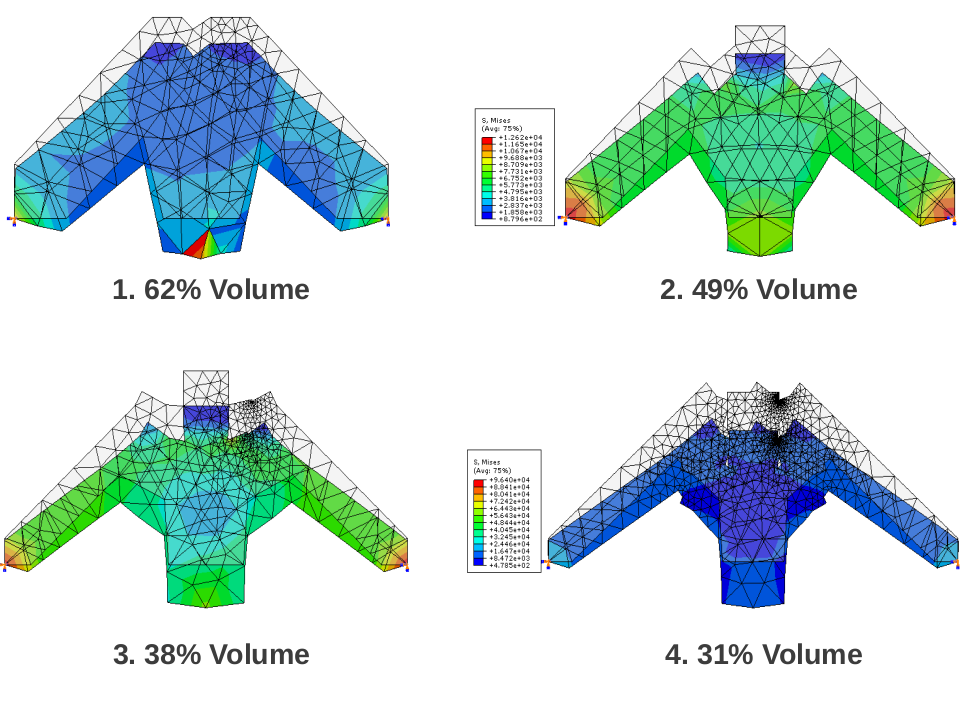
M. Tech. thesis
In BIC-TA 2012
Over the past two decades, structural optimization has been performed extensively by researchers across the world. Most recent investigations have focused on increasing the efficiency and robustness of gradient based optimization techniques and extending them to multidisciplinary objective functions. The existing global optimization techniques suffer with requirement of enormous computational effort due to large number of variables used in grid discretization of problem domain. The paper proposes a novel methodology named as Constructive Geometry Topology Optimization Method (CG-TOM) for topology optimization problems. It utilizes a set of nodes and overlapping primitives to obtain the geometry. A novel graph based repair operator is used to ensure consistent design and real parameter genetic algorithm is used for optimization. Results for standard benchmark problems for compliance minimization have been found to give better results than existing methods in literature. The method is generic and can be extended to any two or three dimensional topology optimization problem using different primitives.
In SocProS 2011
Suspension systems with terrain preview have wide applicability for off-road and military vehicles moving on rough surfaces. Preview control of active suspension systems gives it great flexibility in controlling system behavior. The focus of the study is evolutionary multi-objective optimization of preview controlled active suspension system with several objectives for controller design. The suspension model with base system data and passive response has been explained along with the structure of the preview controller. Multiple conflicting objectives to achieve ride comfort, good handling and road grip are identified and a modified NSGA-II algorithm is used to obtain the trade-off solutions. Thereafter a decision making approach is suggested to select optimum gains for the controller. The obtained optimal solutions are compared with the reference vehicle and other multi-objective optimization strategies. The proposed strategy improves on the reference vehicle objectives along with showing the benefits of multi-criteria approach.
In SEMCCO 2011
Selection of players for a high performance cricket team within a finite budget is a complex task which can be viewed as a constrained multi-objective optimization problem. In cricket team formation, batting strength and bowling strength of a team are the major factors affecting its performance and an optimum trade-off needs to be reached in formation of a good team. We propose a multi-objective approach using NSGA-II algorithm to optimize overall batting and bowling strength of a team and find team members in it. Using the information from trade-off front, a decision making approach is also proposed for final selection of team. Case study using a set of players auctioned in Indian Premier League, 4th edition has been taken and player’s current T-20 statistical data is used as performance parameter. This technique can be used by franchise owners and league managers to form a good team within budget constraints given by the organizers. The methodology is generic and can be easily extended to other sports like soccer, baseball etc.
In ROBIO 2011
Off-line point to point navigation to calculate feasible paths and optimize them for different objectives is computationally difficult. Path planning problem is truly a multi-objective problem, as reaching the goal point in short time is desirable for an autonomous vehicle while ability to generate safe paths in crucial for vehicle viability. Path representation methodologies using piecewise polynomial and B-splines have been used to ensure smooth paths. Multi-objective path planning studies using NSGA-II algorithm to optimize path length and safety measures computed using one of the three metrics (i) an artificial potential field, (ii) extent of obstacle hindrance and (iii) a measure of visibility are implemented. Multiple tradeoff solutions are obtained on complex scenarios. The results indicate the usefulness of treating path planning as a multi-objective problem.
In Computer Methods in Applied Mechanics and Engineering 2026
A major obstacle to establishing reliable structure-property (SP) linkages in materials engineering is the scarcity of diverse 3D microstructure datasets. Limited dataset availability and insufficient control over the analysis and design space restrict the variety of achievable microstructure morphologies, hindering progress in solving the inverse (property-to-structure) design problem. To address these challenges, we introduce MicroLad, a latent diffusion framework specifically designed for reconstructing 3D microstructures from 2D data. Trained on 2D images and employing multi-plane denoising diffusion sampling in the latent space, the framework reliably generates stable and coherent 3D volumes that remain statistically consistent with the original data. While this reconstruction capability enables dimensionality expansion (2D-to-3D) for generating statistically equivalent 3D samples from 2D data, effective exploration of microstructure design requires methods to guide the generation process toward specific objectives. To achieve this, MicroLad integrates score distillation sampling (SDS), which combines a differentiable score loss with microstructural descriptor-matching and property-alignment terms. This approach updates encoded 2D slices of the 3D volume in the latent space, enabling robust inverse-controlled 2D-to-3D microstructure generation. Consequently, the method facilitates exploration of an expanded 3D microstructure analysis and design space in terms of both microstructural descriptors and material properties.
In Physics of Fluids 37(12), 2025
The computational cost of traditional Computational Fluid Dynamics (CFD)-based Aerodynamic Shape Optimization severely restricts design space exploration. This paper introduces TripOptimizer, a fully differentiable deep learning framework for rapid aerodynamic analysis and shape optimization directly from vehicle point cloud data. TripOptimizer integrates a Variational Autoencoder with a triplane-based implicit neural representation for high-fidelity three-dimensional geometry reconstruction and a drag coefficient prediction head. Trained on DrivAerNet++, a large-scale dataset of 8000 unique vehicle geometries with corresponding drag coefficients computed via Reynolds-Averaged Navier-Stokes simulations, the model learns a latent representation that encodes aerodynamically salient geometric features. The framework's primary contribution is a novel optimization strategy that modifies a subset of the encoder parameters to steer an initial geometry toward a target drag value, and we demonstrate its efficacy in case studies where optimized designs achieved drag coefficient reductions up to 11.8%. These results were subsequently validated using independent, high-fidelity Computational Fluid Dynamics simulations with more than 150 x 10^6 cells. A key advantage of the implicit representation is its inherent robustness to geometric imperfections, enabling optimization of non-watertight meshes, a significant challenge for traditional adjoint-based methods. The framework enables a more agile Aerodynamic Shape Optimization workflow, reducing reliance on computationally intensive CFD simulations, especially during early design stages.
In Journal of Mechanical Design 2026
CAD programs, structured as parametric sequences of commands that compile into precise 3D geometries, are fundamental to accurate and efficient engineering design processes. Generating these programs from nonparametric data such as point clouds and meshes remains a crucial yet challenging task, typically requiring extensive manual intervention. Current deep generative models aimed at automating CAD generation are significantly limited by imbalanced and insufficiently large datasets, particularly those lacking representation for complex CAD programs. To address this, we introduce GenCAD-3D, a multimodal generative framework utilizing contrastive learning for aligning latent embeddings between CAD and geometric encoders, combined with latent diffusion models for CAD sequence generation and retrieval. Additionally, we present SynthBal, a synthetic data augmentation strategy specifically designed to balance and expand datasets, notably enhancing representation of complex CAD geometries. Our experiments show that SynthBal significantly boosts reconstruction accuracy, reduces the generation of invalid CAD models, and markedly improves performance on high-complexity geometries, surpassing existing benchmarks. These advancements hold substantial implications for streamlining reverse engineering and enhancing automation in engineering design.
In Journal of Mechanical Design 2026
Guest editorial introducing the JMD special issue on design datasets. It highlights the role of data‑driven methods in engineering design, identifies challenges in creating and sharing multi‑modal, high‑quality datasets, and outlines recommendations and a vision for dataset standards and reuse.
In Journal of Mechanical Design 2025
This article introduces a generative model designed for multimodal control over text-to-image foundation generative artificial intelligence (AI) models such as Stable Diffusion, specifically tailored for engineering design synthesis. Our model proposes parametric, image, and text control modalities to enhance design precision and diversity. First, it handles both partial and complete parametric inputs using a diffusion model that acts as a design autocomplete copilot, coupled with a parametric encoder to process the information. Second, the model utilizes assembly graphs to systematically assemble input component images, which are then processed through a component encoder to capture essential visual data. Third, textual descriptions are integrated via CLIP encoding, ensuring a comprehensive interpretation of design intent. These diverse inputs are synthesized through a multimodal fusion technique, creating a joint embedding that acts as the input to a module inspired by ControlNet. This integration allows the model to apply robust multimodal control to foundation models, facilitating the generation of complex and precise engineering designs. This approach broadens the capabilities of AI-driven design tools and demonstrates significant advancements in precise control based on diverse data modalities for enhanced design generation.
In Journal of Computer and Information Science in Engineering 2025
Engineering problems that apply machine learning often involve computationally intensive methods but rely on limited datasets. As engineering data evolve with new designs and constraints, models must incorporate new knowledge over time. However, high computational costs make retraining models from scratch infeasible. Continual learning (CL) offers a promising solution by enabling models to learn from sequential data while mitigating catastrophic forgetting, where a model forgets previously learned mappings. This work introduces CL to engineering design by benchmarking several CL methods on representative regression tasks. We apply these strategies to five engineering datasets and construct nine new engineering CL benchmarks to evaluate their ability to address forgetting and improve generalization. Preliminary results show that applying existing CL methods to these tasks improves performance over naive fine-tuning. In particular, the replay strategy achieved performance comparable to retraining in several benchmarks while reducing training time by nearly half, demonstrating its potential for real-world engineering workflows.
In Journal of Mechanical Design 2025
This study introduces DrivAerNet, a large-scale high-fidelity CFD dataset of 3D industry-standard car shapes, and RegDGCNN, a dynamic graph convolutional neural network model for regression, both aimed at aerodynamic car design through machine learning. DrivAerNet, with its 4000 detailed 3D car meshes using 0.5 million surface mesh faces and comprehensive aerodynamic performance data comprising of full 3D pressure, velocity fields, and wall-shear stresses, addresses the critical need for extensive datasets to train deep learning models in engineering applications. It is 60% larger than the previously available largest public dataset of cars and is the only open-source dataset that also models wheels and underbody. RegDGCNN leverages this large-scale dataset to provide high-precision drag estimates directly from 3D meshes, bypassing traditional limitations such as the need for 2D image rendering or signed distance fields (SDFs). By enabling fast drag estimation in seconds, RegDGCNN facilitates rapid aerodynamic assessments, offering a substantial leap toward integrating data-driven methods in automotive design. Together, DrivAerNet and RegDGCNN promise to accelerate the car design process and contribute to the development of more efficient cars. To lay the groundwork for future innovations in the field, the dataset and code used in our study are publicly accessible.
Under Review
The field of engineering is shaped by the tools and methods used to solve problems. Optimization is one such class of powerful, robust, and effective engineering tools proven over decades of use. Within just a few years, generative artificial intelligence (GenAI) has risen as another promising tool for general-purpose problem-solving. While optimization shines at finding high-quality and precise solutions that satisfy constraints, GenAI excels at inferring problem requirements, bridging solution domains, handling mixed data modalities, and rapidly generating copious numbers of solutions. These differing attributes also make the two frameworks complementary. Hybrid generative optimization algorithms present a new paradigm for engineering problem-solving and have shown promise across a few engineering applications. We expect significant developments in the near future around generative optimization, leading to changes in how engineers solve problems using computational tools. We offer our perspective on existing methods, areas of promise, and key research questions.
In Applied Energy 2025
Offshore wind energy leverages the high intensity and consistency of oceanic winds, playing a key role in the transition to renewable energy. As energy demands grow, larger turbines are required to optimize power generation and reduce the Levelized Cost of Energy (LCoE), which represents the average cost of electricity over a project’s lifetime. However, upscaling turbines introduces engineering challenges, particularly in the design of supporting structures, especially towers. These towers must support increased loads while maintaining structural integrity, cost-efficiency, and transportability, making them essential to offshore wind projects’ success. This paper presents a comprehensive review of the latest advancements, challenges, and future directions driven by Artificial Intelligence (AI) in the design optimization of Offshore Wind Turbine (OWT) structures, with a focus on towers. It provides an in-depth background on key areas such as design types, load types, analysis methods, design processes, monitoring systems, Digital Twin (DT), software, standards, reference turbines, economic factors, and optimization techniques. Additionally, it includes a state-of-the-art review of optimization studies related to tower design optimization, presenting a detailed examination of turbine, software, loads, optimization method, design variables and constraints, analysis, and findings, motivating future research to refine design approaches for effective turbine upscaling and improved efficiency. Lastly, the paper explores future directions where AI can revolutionize tower design optimization, enabling the development of efficient, scalable, and sustainable structures. By addressing the upscaling challenges and supporting the growth of renewable energy, this work contributes to shaping the future of offshore wind turbine towers and others supporting structures.
In Transactions on Machine Learning Research
Generative models have recently achieved remarkable success and widespread adoption in society, yet they often struggle to generate realistic and accurate outputs. This challenge extends beyond language and vision into fields like engineering design, where safety-critical engineering standards and non-negotiable physical laws tightly constrain what outputs are considered acceptable. In this work, we introduce a novel training method to guide a generative model toward constraint-satisfying outputs using `negative data' -- examples of what to avoid. Our negative-data generative model (NDGM) formulation easily outperforms classic models, generating 1/6 as many constraint-violating samples using 1/8 as much data in certain problems. It also consistently outperforms other baselines, achieving a balance between constraint satisfaction and distributional similarity that is unsurpassed by any other model in 12 of the 14 problems tested. This widespread superiority is rigorously demonstrated across numerous synthetic tests and real engineering problems, such as ship hull synthesis with hydrodynamic constraints and vehicle design with impact safety constraints. Our benchmarks showcase both the best-in-class performance of our new NDGM formulation and the overall dominance of NDGMs versus classic generative models.
In Transactions on Machine Learning Research
The creation of manufacturable and editable 3D shapes through Computer-Aided Design (CAD) remains a highly manual and time-consuming task, hampered by the complex topology of boundary representations of 3D solids and unintuitive design tools. While most work in the 3D shape generation literature focuses on representations like meshes, voxels, or point clouds, practical engineering applications demand the modifiability and manufacturability of CAD models and the ability for multi-modal conditional CAD model generation. This paper introduces GenCAD, a generative model that employs autoregressive transformers with a contrastive learning framework and latent diffusion models to transform image inputs into parametric CAD command sequences, resulting in editable 3D shape representations. Extensive evaluations demonstrate that GenCAD significantly outperforms existing state-of-the-art methods in terms of the unconditional and conditional generations of CAD models. Additionally, the contrastive learning framework of GenCAD facilitates the retrieval of CAD models using image queries from large CAD databases, which is a critical challenge within the CAD community. Our results provide a significant step forward in highlighting the potential of generative models to expedite the entire design-to-production pipeline and seamlessly integrate different design modalities.
In Journal of Mechanical Design 2025
Designers may often ask themselves how to adjust their design concepts to achieve demanding functional goals. To answer such questions, designers must often consider counterfactuals, weighing design alternatives and their projected performance. This paper introduces Multi-objective Counterfactuals for Design (MCD), a computational tool that automates and streamlines the counterfactual search process and recommends targeted design modifications that meet designers' unique requirements. MCD improves upon existing counterfactual search methods by supporting multi-objective requirements, which are crucial in design problems, and by decoupling the counterfactual search and sampling processes, thus enhancing efficiency and facilitating objective trade-off visualization. The paper showcases MCD's capabilities in complex engineering tasks using three demonstrative bicycle design challenges. In the first, MCD effectively identifies design modifications that quantifiably enhance functional performance, strengthening the bike frame and saving weight. In the second, MCD modifies parametric bike models in a cross-modal fashion to resemble subjective text prompts or reference images. In a final multidisciplinary case study, MCD tackles all the quantitative and subjective design requirements introduced in the first two problems, while simultaneously customizing a bike design to an individual rider's biomechanical attributes. By exploring hypothetical design alterations and their impact on multiple design objectives, MCD recommends effective design modifications for practitioners seeking to make targeted enhancements to their designs.
In Journal of Computing and Information Science in Engineering 25(2), 2025
This research introduces DesignQA, a novel benchmark aimed at evaluating the proficiency of multimodal large language models (MLLMs) in comprehending and applying engineering requirements in technical documentation. Developed with a focus on real-world engineering challenges, DesignQA uniquely combines multimodal data-including textual design requirements, CAD images, and engineering drawings-derived from the Formula SAE student competition. Different from many existing MLLM benchmarks, DesignQA contains document-grounded visual questions where the input image and input document come from different sources. The benchmark features automatic evaluation metrics and is divided into segments-Rule Comprehension, Rule Compliance, and Rule Extraction-based on tasks that engineers perform when designing according to requirements. We evaluate state-of-the-art models like GPT4 and LLaVA against the benchmark, and our study uncovers the existing gaps in MLLMs' abilities to interpret complex engineering documentation. Key findings suggest that while MLLMs demonstrate potential in navigating technical documents, substantial limitations exist, particularly in accurately extracting and applying detailed requirements to engineering designs. This benchmark sets a foundation for future advancements in AI-supported engineering design processes. DesignQA is publicly available at: https://github.com/anniedoris/design_qa/.
In Transactions on Machine Learning Research
Topology optimization is a critical task in engineering design, where the goal is to optimally distribute material in a given space for maximum performance. We introduce Neural Implicit Topology Optimization (NITO), a novel approach to accelerate topology optimization problems using deep learning. NITO stands out as one of the first frameworks to offer a resolution-free and domain-agnostic solution in deep learning-based topology optimization. NITO synthesizes structures with up to seven times better structural efficiency compared to SOTA diffusion models and does so in a tenth of the time. In the NITO framework, we introduce a novel method, the Boundary Point Order-Invariant MLP (BPOM), to represent boundary conditions in a sparse and domain-agnostic manner, moving away from expensive simulation-based approaches. Crucially, NITO circumvents the domain and resolution limitations that restrict Convolutional Neural Network (CNN) models to a structured domain of fixed size -- limitations that hinder the widespread adoption of CNNs in engineering applications. This generalizability allows a single NITO model to train and generate solutions in countless domains, eliminating the need for numerous domain-specific CNNs and their extensive datasets. Despite its generalizability, NITO outperforms SOTA models even in specialized tasks, is an order of magnitude smaller, and is practically trainable at high resolutions that would be restrictive for CNNs. This combination of versatility, efficiency, and performance underlines NITO's potential to transform the landscape of engineering design optimization problems through implicit fields.
In Structural and Multidisciplinary Optimization
Bayesian Optimization (BO) is a foundational strategy in the field of engineering design optimization for efficiently handling black-box functions with many constraints and expensive evaluations. This paper introduces a fast and accurate BO framework that leverages Pre-trained Transformers for Bayesian Optimization (PFN4sBO) to address constrained optimization problems in engineering. Unlike traditional BO methods that rely heavily on Gaussian Processes (GPs), our approach utilizes Prior-data Fitted Networks (PFNs), a type of pre-trained transformer, to infer constraints and optimal solutions without requiring any iterative retraining. We demonstrate the effectiveness of PFN-based BO through a comprehensive benchmark consisting of fifteen test problems, encompassing synthetic, structural, and engineering design challenges. Our findings reveal that PFN-based BO significantly outperforms Constrained Expected Improvement and Penalty-based GP methods by an order of magnitude in speed while also outperforming them in accuracy in identifying feasible, optimal solutions. This work showcases the potential of integrating machine learning with optimization techniques in solving complex engineering challenges, heralding a significant leap forward for optimization methodologies, opening up the path to using PFN-based BO to solve other challenging problems, such as enabling user-guided interactive BO, adaptive experiment design, or multi-objective design optimization. Additionally, we establish a benchmark for evaluating BO algorithms in engineering design, offering a robust platform for future research and development in the field. This benchmark framework for evaluating new BO algorithms in engineering design will be published at this https URL.
In Transactions on Machine Learning Research
In this paper, we introduce LInK, a novel framework that integrates contrastive learning of performance and design space with optimization techniques for solving complex inverse problems in engineering design with discrete and continuous variables. We focus on the path synthesis problem for planar linkage mechanisms. By leveraging a multi-modal and transformation-invariant contrastive learning framework, LInK learns a joint representation that captures complex physics and design representations of mechanisms, enabling rapid retrieval from a vast dataset of over 10 million mechanisms. This approach improves precision through the warm start of a hierarchical unconstrained nonlinear optimization algorithm, combining the robustness of traditional optimization with the speed and adaptability of modern deep learning methods. Our results on an existing benchmark demonstrate that LInK outperforms existing methods with 28 times less error compared to a state-of-the-art approach while taking 20 times less time on an existing benchmark. Moreover, we introduce a significantly more challenging benchmark, named LINK-ABC, which involves synthesizing linkages that trace the trajectories of English capital alphabets - an inverse design benchmark task that existing methods struggle with due to large non-linearities and tiny feasible space. Our results demonstrate that LInK not only advances the field of mechanism design but also broadens the applicability of contrastive learning and optimization to other areas of engineering.
In Transactions on Machine Learning Research
Regression models often fail to generalize effectively in regions characterized by highly imbalanced label distributions. Previous methods for deep imbalanced regression rely on gradient-based weight updates, which tend to overfit in underrepresented regions. This paper proposes a paradigm shift towards in-context learning as an effective alternative to conventional in-weight learning methods, particularly for addressing imbalanced regression. In-context learning refers to the ability of a model to condition itself, given a prompt sequence composed of in-context samples (input-label pairs) alongside a new query input to generate predictions, without requiring any parameter updates. In this paper, we study the impact of the prompt sequence on the model performance from both theoretical and empirical perspectives. We emphasize the importance of localized context in reducing bias within regions of high imbalance. Empirical evaluations across a variety of real-world datasets demonstrate that in-context learning substantially outperforms existing in-weight learning methods in scenarios with high levels of imbalance.
In Design Science
Text-to-image models are enabling efficient design space exploration, rapidly generating images from text prompts. However, many generative AI tools are imperfect for product design applications as they are not built for the goals and requirements of product design. The unclear link between text input and image output further complicates their application. This work empirically investigates design space exploration strategies that can successfully yield product images that are feasible, novel, and aesthetic, which are three common goals in product design. Specifically, user actions within the global and local editing modes, including their time spent, prompt length, mono vs. multi-criteria prompts, and goal orientation of prompts, are analyzed. Key findings reveal the pivotal role of mono vs. multi-criteria and goal orientation of prompts in achieving specific design goals over time and prompt length. The study recommends prioritizing the use of multi-criteria prompts for feasibility and novelty during global editing, while favoring mono-criteria prompts for aesthetics during local editing. Overall, this paper underscores the nuanced relationship between the AI-driven text-to-image models and their effectiveness in product design, urging designers to carefully structure prompts during different editing modes to better meet the unique demands of product design.
In An MIT Exploration of Generative AI
In the mid-2010s, as computing and other digital technologies matured (), researchers began to speculate about a new era of innovation—with artificial intelligence (AI) as the standard-bearer of a “Fourth Industrial Revolution” (). The release of generative AI (Gen-AI) technologies (e.g., ChatGPT) in late 2022 reignited the discussion, prompting us to wonder: what are the barriers, risks, and potential rewards to using gen-AI for design and manufacturing? As Gen-AI has entered the mainstream, geopolitics and business practices have shifted. Covid-19 disrupted global supply chains, tensions with import partners have risen, and military conflicts introduce new uncertainties. As companies consider propositions like ‘reshoring’ or ‘nearshoring/friendshoring’ production (), we recognize other hindrances: suboptimal resource allocation, labor market volatility and trends toward an older and geographically mismatched workforce, and highly concentrated tech markets that foster anticompetitive business practices. As the United States expands domestic production capacity (e.g., semiconductors and electric vehicles), Gen-AI could help us overcome those challenges. To investigate the current and potential usefulness of Gen-AI in design and manufacturing, we interviewed industry experts—including engineers, manufacturers, tech executives, and entrepreneurs. They have identified many opportunities for the deployment of Gen-AI: (1) reducing the incidence of costly late-stage design changes when scaling production; (2) providing information to designers and engineers, including identifying suitable design spaces and material formulations and incorporating consumer preferences; (3) improving test data interpretation to enable rapid validation and qualification; (4) democratizing workers’ access and usage of data to enable real-time insights and process adjustment; and (5) empowering less-skilled workers to be more productive and do more-expert work. Current Gen-AI solutions (e.g., ChatGPT, Claude) cannot accomplish these goals due to several key deficiencies, including the inability to provide robust, reliable, and replicable output; lack of relevant domain knowledge; unawareness of industry-standards requirements for product quality; failure to integrate seamlessly with existing workflow; and inability to simultaneously interpret data from different sources and formats. We propose a development framework for the next generation of Gen-AI tools for design and manufacturing (“NextGen-AI”): (1) provide better information about engineering tools, repositories, search methods, and other resources to augment the creative process of design; (2) integrate adherence to first principles when solving engineering problems; (3) leverage employees’ experiential knowledge to improve training and performance; (4) empower workers to perform new and more-expert productive tasks rather than pursue static automation of workers’ current functions; (5) create a collaborative and secure data ecosystem to train foundation models; and (6) ensure that new tools are safe and effective. These goals are extensive and will require broad-based buy-in from business leaders, operators, researchers, engineers, and policymakers. We recommend the following priorities to enable useful AI for design and manufacturing: (1) improve systems integration to ethically collect real-time data, (2) regulate data governance to ensure equal opportunity in development and ownership, (3) expand the collection of worker-safety data to assess industry-wide AI usage, (4) include engineers and operators in the development and uptake of new tools, and (5) focus on skills-complementary deployments to maximize productivity upside.
In Journal of Mechanical Design 2024
In many design automation applications, accurate segmentation and classification of 3D surfaces and extraction of geometric insight from 3D models can be pivotal. This paper primarily introduces a machine learning-based scheme that leverages Graph Neural Networks (GNN) for handling 3D geometries, specifically for surface classification. Our model demonstrates superior performance against two state-of-the-art models, PointNet++ and PointMLP, in terms of surface classification accuracy, beating both models. Central to our contribution is the novel incorporation of conformal predictions, a method that offers robust uncertainty quantification and handling with marginal statistical guarantees. Unlike traditional approaches, conformal predictions enable our model to ensure precision, especially in challenging scenarios where mistakes can be highly costly. This robustness proves invaluable in design applications, and as a case in point, we showcase its utility in automating the Computational Fluid Dynamics (CFD) meshing process for aircraft models based on expert guidance. Our results reveal that our automatically generated mesh, guided by the proposed rules by experts enabled through the segmentation model, is not only efficient but matches the quality of expert-generated meshes, leading to accurate simulations.
In Journal of Mechanical Design 2024
When designing evidence-based policies and programs, decision-makers must distill key information from a vast and rapidly growing literature base. Identifying relevant literature from raw search results is time and resource intensive, and is often done by manual screening. In this study, we develop an AI agent based on a bidirectional encoder representations from transformers (BERT) model and incorporate it into a human team designing an evidence synthesis product for global development. We explore the effectiveness of the human-AI hybrid team in accelerating the evidence synthesis process. We further enhance the human-AI hybrid team through active learning (AL). Specifically, we explore different sampling strategies: random, least confidence (LC), and highest priority (HP) sampling, to study their influence on the collaborative screening process. Results show that incorporating the BERT-based AI agent can reduce the human screening effort by 68.5% compared to the case of no AI assistance, and by 16.8% compared to using the industry standard model for identifying 80% of all relevant documents. When we apply the HP sampling strategy, the human screening effort can be reduced even more: by 78% for identifying 80% of all relevant documents compared to no AI assistance. We apply the AL-enhanced human-AI hybrid teaming workflow in the design process of three evidence gap maps which are now published for USAID’s use. These findings demonstrate how AI can accelerate the development of evidence synthesis products and promote timely evidence-based decision making in global development.
In Journal of Mechanical Design 2024
In engineering design, navigating complex decision-making landscapes demands a thorough exploration of the design, performance, and constraint spaces, often impeded by resource-intensive simulations. Data-driven methods can mitigate this challenge by harnessing historical data to delineate feasible domains, accelerate optimization, or evaluate designs. However, the implementation of these methods usually demands machine-learning expertise and multiple trials to choose the right method and hyperparameters. This makes them less accessible for numerous engineering situations. Additionally, there is an inherent trade-off between training speed and accuracy, with faster methods sometimes compromising precision. In our paper, we demonstrate that a recently released general-purpose transformer-based classification model, TabPFN, is both fast and accurate. Notably, it requires no dataset-specific training to assess new tabular data. TabPFN is a Prior-Data Fitted Network, which undergoes a one-time offline training across a broad spectrum of synthetic datasets and performs in-context learning. We evaluated TabPFN's efficacy across eight engineering design classification problems, contrasting it with seven other algorithms, including a state-of-the-art AutoML method. For these classification challenges, TabPFN consistently outperforms in speed and accuracy. It is also the most data-efficient and provides the added advantage of being differentiable and giving uncertainty estimates. Our findings advocate for the potential of pre-trained models that learn from synthetic data and require no domain-specific tuning to make data-driven engineering design accessible to a broader community and open ways to efficient general-purpose models valid across applications. Furthermore, we share a benchmark problem set for evaluating new classification algorithms in engineering design and make our code publicly available.
In Artificial Intelligence Review
Engineering Design is undergoing a transformative shift with the advent of AI, marking a new era in how we approach product, system, and service planning. Large language models have demonstrated impressive capabilities in enabling this shift. Yet, with text as their only input modality, they cannot leverage the large body of visual artifacts that engineers have used for centuries and are accustomed to. This gap is addressed with the release of multimodal vision language models, such as GPT-4V, enabling AI to impact many more types of tasks. In light of these advancements, this paper presents a comprehensive evaluation of GPT-4V, a vision language model, across a wide spectrum of engineering design tasks, categorized into four main areas: Conceptual Design, System-Level and Detailed Design, Manufacturing and Inspection, and Engineering Education Tasks. Our study assesses GPT-4V's capabilities in design tasks such as sketch similarity analysis, concept selection using Pugh Charts, material selection, engineering drawing analysis, CAD generation, topology optimization, design for additive and subtractive manufacturing, spatial reasoning challenges, and textbook problems. Through this structured evaluation, we not only explore GPT-4V's proficiency in handling complex design and manufacturing challenges but also identify its limitations in complex engineering design applications. Our research establishes a foundation for future assessments of vision language models, emphasizing their immense potential for innovating and enhancing the engineering design and manufacturing landscape. It also contributes a set of benchmark testing datasets, with more than 1000 queries, for ongoing advancements and applications in this field.
In Journal of Marine Science and Engineering 2023
Ship design is a years-long process that requires balancing complex design trade-offs to create a ship that is efficient and effective. Finding new ways to improve the ship design process can lead to significant cost savings in the time and effort required to design a ship and cost savings in the procurement and operation of a ship. One promising technology is generative artificial intelligence, which has been shown to reduce design cycle time and create novel, high-performing designs. In literature review, generative artificial intelligence has been shown to generate ship hulls; however, ship design is particularly difficult as the hull of a ship requires the consideration of many objectives. This paper presents a study on the generation of parametric ship hull designs using a parametric diffusion model that considers multiple objectives and constraints for the hulls. This denoising diffusion probabilistic model (DDPM) generates the tabular parametric design vectors of a ship hull, which is then constructed into a point cloud and mesh for performance evaluation. In addition to a tabular DDPM, this paper details adding guidance to improve the quality of generated parametric ship hull designs. By leveraging a classifier to guide sample generation, the DDPM produced feasible parametric ship hulls that maintain the coverage of the initial training dataset of ship hulls with a 99.5% rate, a 149x improvement over random sampling of the design vector parameters across the design space. Parametric ship hulls produced with performance guidance saw an average of 91.4% reduction in wave drag coefficients and an average of a 47.9x relative increase in the total displaced volume of the hulls compared to the mean performance of the hulls in the training dataset. The use of a DDPM to generate parametric ship hulls can reduce design time by generating high-performing hull designs for future analysis. These generated hulls have low drag and high volume, which can reduce the cost of operating a ship and increase its potential to generate revenue."
In Journal of Computer and Information Science in Engineering 2023
Multi-modal machine learning (MMML), which involves integrating multiple modalities of data and their corresponding processing methods, has demonstrated promising results in various practical applications, such as text-to-image translation. This review paper summarizes the recent progress and challenges in using MMML for engineering design tasks. First, we introduce the different data modalities commonly used as design representations and involved in MMML, including text, 2D pixel data (e.g., images and sketches), and 3D shape data (e.g., voxels, point clouds, and meshes). We then provide an overview of the various approaches and techniques used for representing, fusing, aligning, synthesizing, and co-learning multi-modal data as five fundamental concepts of MMML. Next, we review the state-of-the-art capabilities of MMML that potentially apply to engineering design tasks, including design knowledge retrieval, design evaluation, and design synthesis. We also highlight the potential benefits and limitations of using MMML in these contexts. Finally, we discuss the challenges and future directions in using MMML for engineering design, such as the need for large labeled multi-modal design datasets, robust and scalable algorithms, integrating domain knowledge, and handling data heterogeneity and noise. Overall, this review paper provides a comprehensive overview of the current state and prospects of MMML for engineering design applications.
In Computer Aided Design 2023
Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper.
In Journal of Mechanical Design 2023
Conceptual design evaluation is an indispensable component of innovation in the early stage of engineering design. Properly assessing the effectiveness of conceptual design requires a rigorous evaluation of the outputs. Traditional methods to evaluate conceptual designs are slow, expensive, and difficult to scale because they rely on human expert input. An alternative approach is to use computational methods to evaluate design concepts. However, most existing methods have limited utility because they are constrained to unimodal design representations (e.g., texts or sketches). To overcome these limitations, we propose an attention-enhanced multimodal learning (AEMML)-based machine learning (ML) model to predict five design metrics- drawing quality, uniqueness, elegance, usefulness, and creativity. The proposed model utilizes knowledge from large external datasets through transfer learning (TL), simultaneously processes text and sketch data from early-phase concepts, and effectively fuses the multimodal information through a mutual cross-attention mechanism. To study the efficacy of multimodal learning (MML) and attention-based information fusion, we compare (1) a baseline MML model and the unimodal models and (2) the attention-enhanced models with baseline models in terms of their explanatory power for the variability of the design metrics. The results show that MML improves the model explanatory power by 0.05-0.12 and the mutual cross-attention mechanism further increases the explanatory power of the approach by 0.05-0.09, leading to the highest explanatory power of 0.44 for drawing quality, 0.60 for uniqueness, 0.45 for elegance, 0.43 for usefulness, and 0.32 for creativity. Our findings highlight the benefit of using multimodal representations for design metric assessment.
In Computer Aided Design 2023
This paper demonstrates how Automated Machine Learning (AutoML) methods can be used as effective surrogate models in engineering design problems. To do so, we consider the challenging problem of structurally-performant bicycle frame design and demonstrate across-the-board dominance by AutoML in regression and classification surrogate modeling tasks. We also introduce FRAMED — a parametric dataset of 4500 bicycle frames based on bicycles designed by practitioners and enthusiasts worldwide. Accompanying these frame designs, we provide ten structural performance values such as weight, displacements under load, and safety factors computed using finite element simulations for all the bicycle frame designs. We formulate two challenging test problems- a performance-prediction regression problem and a feasibility-prediction classification problem. We then systematically search for optimal surrogate models using Bayesian hyperparameter tuning and neural architecture search. Finally, we show how a state-of-the-art AutoML method can be effective for both regression and classification problems. We demonstrate that the proposed AutoML models outperform the strongest gradient boosting and neural network surrogates identified through Bayesian optimization by an improved F1 score of 24% for classification and reduced mean absolute error by 12.5% for regression. Our work introduces a dataset for bicycle design practitioners, provides two benchmark problems for surrogate modeling researchers, and demonstrates the advantages of AutoML in machine learning tasks.
In Journal of Mechanical Design 2022
Automated design synthesis has the potential to revolutionize the modern engineering design process and improve access to highly optimized and customized products across countless industries. Successfully adapting generative machine learning to design engineering may enable such automated design synthesis and is a research subject of great importance. We present a review and analysis of deep generative machine learning models in engineering design. Deep generative models (DGMs) typically leverage deep networks to learn from an input dataset and synthesize new designs. Recently, DGMs such as feedforward neural networks (NNs), generative adversarial networks (GANs), variational autoencoders (VAEs), and certain deep reinforcement learning (DRL) frameworks have shown promising results in design applications like structural optimization, materials design, and shape synthesis. The prevalence of DGMs in engineering design has skyrocketed since 2016. Anticipating the continued growth, we conduct a review of recent advances to benefit researchers interested in DGMs for design. We structure our review as an exposition of the algorithms, datasets, representation methods, and applications commonly used in the current literature. In particular, we discuss key works that have introduced new techniques and methods in DGMs, successfully applied DGMs to a design-related domain, or directly supported the development of DGMs through datasets or auxiliary methods. We further identify key challenges and limitations currently seen in DGMs across design fields, such as design creativity, handling constraints and objectives, and modeling both form and functional performance simultaneously. In our discussion, we identify possible solution pathways as key areas on which to target the future work.
In Journal of Mechanical Design 2022
In this paper, we present “BIKED,” a dataset composed of 4500 individually designed bicycle models sourced from hundreds of designers. We expect BIKED to enable a variety of data-driven design applications for bicycles and support the development of data-driven design methods. The dataset is comprised of a variety of design information including assembly images, component images, numerical design parameters, and class labels. In this paper, we first discuss the processing of the dataset, and then highlight some prominent research questions that BIKED can help address. Of these questions, we further explore the following in detail- (1) How can we explore, understand, and visualize the current design space of bicycles and utilize this information? We apply unsupervised embedding methods to study the design space and identify key takeaways from this analysis. (2) When designing bikes using algorithms, under what conditions can machines understand the design of a given bike? We train a multitude of classifiers to understand designs, then examine the behavior of these classifiers through confusion matrices and permutation-based interpretability analysis. 3) Can machines learn to synthesize new bicycle designs by studying existing ones? We test Variational Autoencoders on random generation, interpolation, and extrapolation tasks after training on BIKED data. The dataset and code are available online.
In Journal of Mechanical Design 2022
A picture is worth a thousand words, and in design metric estimation, a word may be worth a thousand features. Pictures are awarded this worth because they can encode a plethora of information. When evaluating designs, we aim to capture a range of information as well, including usefulness, uniqueness, and novelty of a design. The subjective nature of these concepts makes their evaluation difficult. Still, many attempts have been made and metrics developed to do so, because design evaluation is integral to the creation of novel solutions. The most common metrics used are the consensual assessment technique (CAT) and the Shah, Vargas-Hernandez, and Smith (SVS) method. While CAT is accurate and often regarded as the “gold standard,” it relies on using expert ratings, making CAT expensive and time-consuming. Comparatively, SVS is less resource-demanding, but often criticized as lacking sensitivity and accuracy. We utilize the complementary strengths of both methods through machine learning. This study investigates the possibility of using machine learning to predict expert creativity assessments from more accessible nonexpert survey results. The SVS method results in a text-rich dataset about a design. We utilize these textual design representations and the deep semantic relationships that words and sentences encode to predict more desirable design metrics, including CAT metrics. We demonstrate the ability of machine learning models to predict design metrics from the design itself and SVS survey information. We show that incorporating natural language processing (NLP) improves prediction results across design metrics, and that clear distinctions in the predictability of certain metrics exist. Our code and additional information about our work are available on the MIT DeCoDE Lab website.1
In Journal of Mechanical Design 2022
Typical engineering design tasks require the effort to modify designs iteratively until they meet certain constraints, i.e., performance or attribute requirements. Past work has proposed ways to solve the inverse design problem, where desired designs are directly generated from specified requirements, thus avoiding the trial and error process. Among those approaches, the conditional deep generative model shows great potential since (1) it works for complex high-dimensional designs and (2) it can generate multiple alternative designs given any range condition. In this work, we propose a conditional deep generative model, range-constrained generative adversarial network, to achieve automatic design synthesis subject to range constraints. The proposed model addresses the sparse conditioning issue in data-driven inverse design problems by introducing a label-aware self-augmentation approach. We also propose a new uniformity loss to ensure the generated designs evenly cover the given requirement range. Through a real-world example of constrained 3D shape generation, we show that the label-aware self-augmentation leads to an average improvement of 14% on the constraint satisfaction for generated 3D shapes, and the uniformity loss leads to a 125% average increase on the uniformity of generated shapes’ attributes. This work laid the foundation for data-driven inverse design problems where we consider range constraints and there are sparse regions in the condition space.
In ASME Open Journal of Engineering 2022
Understanding relationships between different products in a market system and predicting how changes in design impact their market position can be instrumental for companies to create better products. We propose a graph neural network-based method for modeling relationships between products, where nodes in a network represent products and edges represent their relationships. Our modeling enables a systematic way to predict the relationship links between unseen products for future years. When applied to a Chinese car market case study, our method based on an inductive graph neural network approach, GraphSAGE, yields double the link prediction performance compared to an existing network modeling method—exponential random graph model-based method for predicting the car co-consideration relationships. Our work also overcomes scalability and multiple data type-related limitations of the traditional network modeling methods by modeling a larger number of attributes, mixed categorical and numerical attributes, and unseen products. While a vanilla GraphSAGE requires a partial network to make predictions, we augment it with an “adjacency prediction model” to circumvent the limitation of needing neighborhood information. Finally, we demonstrate how insights obtained from a permutation-based interpretability analysis can help a manufacturer understand how design attributes impact the predictions of product relationships. Overall, this work provides a systematic data-driven method to predict the relationships between products in a complex network such as the car market.
In Complexity 2022
Statistical network models have been used to study the competition among different products and how product attributes influence customer decisions. However, in existing research using network-based approaches, product competition has been viewed as binary (i.e., whether a relationship exists or not), while in reality, the competition strength may vary among products. In this paper, we model the strength of the product competition by employing a statistical network model, with an emphasis on how product attributes affect which products are considered together and which products are ultimately purchased by customers. We first demonstrate how customers’ considerations and choices can be aggregated as weighted networks. Then, we propose a weighted network modeling approach by extending the valued exponential random graph model to investigate the effects of product features and network structures on product competition relations. The approach that consists of model construction, interpretation, and validation is presented in a step-by-step procedure. Our findings suggest that the weighted network model outperforms commonly used binary network baselines in predicting product competition as well as market share. Also, traditionally when using binary network models to study product competitions and depending on the cutoff values chosen to binarize a network, the resulting estimated customer preferences can be inconsistent. Such inconsistency in interpreting customer preferences is a downside of binary network models but can be well addressed by the proposed weighted network model. Lastly, this paper is the first attempt to study customers’ purchase preferences (i.e., aggregated choice decisions) and car competition (i.e., customers’ co-consideration decisions) together using weighted directed networks.
In Collective Intelligence 2022
As the volume and complexity of distributed online work increases, the collaboration among people who have never worked together in the past is becoming increasingly necessary. Recent research has proposed algorithms to maximize the performance of such teams by grouping workers according to a set of predefined decision criteria. This approach micro-manages workers, who have no say in the team formation process. Depriving users of control over who they will work with stifles creativity, causes psychological discomfort and results in less-than-optimal collaboration results. In this work, we propose an alternative model, called Self-Organizing Teams (SOTs), which relies on the crowd of online workers itself to organize into effective teams. Supported but not guided by an algorithm, SOTs are a new human-centered computational structure, which enables participants to control, correct and guide the output of their collaboration as a collective. Experimental results, comparing SOTs to two benchmarks that do not offer user agency over the collaboration, reveal that participants in the SOTs condition produce results of higher quality and report higher teamwork satisfaction. We also find that, similarly to machine learning-based self-organization, human SOTs exhibit emergent collective properties, including the presence of an objective function and the tendency to form more distinct clusters of compatible teammates.
In Applied Soft Computing 2021
Multi-objective optimization is key to solving many Engineering Design problems, where design parameters are optimized for several performance indicators. However, optimization results are highly dependent on how the designs are parameterized. Researchers have shown that deep generative models can learn compact design representations, providing a new way of parameterizing designs to achieve faster convergence and improved optimization performance. Despite their success in capturing complex distributions, existing generative models face three challenges when used for design problems- (1) generated designs have limited design space coverage, (2) the generator ignores design performance, and 3) the new parameterization is unable to represent designs beyond training data. To address these challenges, we propose MO-PaDGAN, which adds a Determinantal Point Processes based loss function to the generative adversarial network to simultaneously model diversity and (multi-variate) performance. MO-PaDGAN can thus improve the performances and coverage of generated designs, and even generate designs with performances exceeding those from training data. When using MO-PaDGAN as a new parameterization in multi-objective optimization, we can discover much better Pareto fronts even though the training data do not cover those Pareto fronts. In a real-world multi-objective airfoil design example, we demonstrate that MO-PaDGAN achieves, on average, an over 180% improvement in the hypervolume indicator when compared to the vanilla GAN or other state-of-the-art parameterization methods.
In Journal of Mechanical Design 2021
Deep generative models are proven to be a useful tool for automatic design synthesis and design space exploration. When applied in engineering design, existing generative models face three challenges- 1) generated designs lack diversity and do not cover all areas of the design space, 2) it is difficult to explicitly improve the overall performance or quality of generated designs, and 3) existing models generate do not generate novel designs, outside the domain of the training data. In this paper, we simultaneously address these challenges by proposing a new Determinantal Point Processes based loss function for probabilistic modeling of diversity and quality. With this new loss function, we develop a variant of the Generative Adversarial Network, named “Performance Augmented Diverse Generative Adversarial Network” or PaDGAN, which can generate novel high-quality designs with good coverage of the design space. Using three synthetic examples and one real-world airfoil design example, we demonstrate that PaDGAN can generate diverse and high-quality designs. In comparison to a vanilla Generative Adversarial Network, on average, it generates samples with 28% higher mean quality score with larger diversity and without the mode collapse issue. Unlike typical generative models that usually generate new designs by interpolating within the boundary of training data, we show that PaDGAN expands the design space boundary outside the training data towards high-quality regions. The proposed method is broadly applicable to many tasks including design space exploration, design optimization, and creative solution recommendation.
In Journal of Mechanical Design 2020
Design variety metrics measure how much a design space is explored. This article proposes that a generalized class of entropy metrics based on Sharma–Mittal entropy offers advantages over existing methods to measure design variety. We show that an exemplar metric from Sharma–Mittal entropy, namely, the Herfindahl–Hirschman index for design (HHID) has the following desirable advantages over existing metrics (a) more accuracy- it better aligns with human ratings compared to existing and commonly used tree-based metrics for two new datasets; (b) higher sensitivity- it has higher sensitivity compared to existing methods when distinguishing between the variety of sets; (c) allows efficient optimization- it is a submodular function, which enables one to optimize design variety using a polynomial time greedy algorithm; and (d) generalizes to multiple metrics- many existing metrics can be derived by changing the parameters of this metric, which allows a researcher to fit the metric to better represent variety for new domains. This article also contributes a procedure for comparing metrics used to measure variety via constructing ground truth datasets from pairwise comparisons. Overall, our results shed light on some qualities that good design variety metrics should possess and the nontrivial challenges associated with collecting the data needed to measure those qualities.
In Computer Methods in Applied Mechanics and Engineering 2020
Metamaterials are emerging as a new paradigmatic material system to render unprecedented and tailorable properties for a wide variety of engineering applications. However, the inverse design of metamaterial and its multiscale system is challenging due to high-dimensional topological design space, multiple local optima, and high computational cost. To address these hurdles, we propose a novel data-driven metamaterial design framework based on deep generative modeling. A variational autoencoder (VAE) and a regressor for property prediction are simultaneously trained on a large metamaterial database to map complex microstructures into a low-dimensional, continuous, and organized latent space. We show in this study that the latent space of VAE provides a distance metric to measure shape similarity, enable interpolation between microstructures and encode meaningful patterns of variation in geometries and properties. Based on these insights, systematic data-driven methods are proposed for the design of microstructure, graded family, and multiscale system. For microstructure design, the tuning of mechanical properties and complex manipulations of microstructures are easily achieved by simple vector operations in the latent space. The vector operation is further extended to generate metamaterial families with a controlled gradation of mechanical properties by searching on a constructed graph model. For multiscale metamaterial systems design, a diverse set of microstructures can be rapidly generated using VAE for target properties at different locations and then assembled by an efficient graph-based optimization method to ensure compatibility between adjacent microstructures. We demonstrate our framework by designing both functionally graded and heterogeneous metamaterial systems that achieve desired distortion behaviors.
In Journal of Mechanical Design 2020
Data-driven design of mechanical metamaterials is an increasingly popular method to combat costly physical simulations and immense, often intractable, geometrical design spaces. Using a precomputed dataset of unit cells, a multiscale structure can be quickly filled via combinatorial search algorithms, and machine learning models can be trained to accelerate the process. However, the dependence on data induces a unique challenge- an imbalanced dataset containing more of certain shapes or physical properties can be detrimental to the efficacy of data-driven approaches. In answer, we posit that a smaller yet diverse set of unit cells leads to scalable search and unbiased learning. To select such subsets, we propose METASET, a methodology that (1) uses similarity metrics and positive semi-definite kernels to jointly measure the closeness of unit cells in both shape and property spaces and (2) incorporates Determinantal Point Processes for efficient subset selection. Moreover, METASET allows the trade-off between shape and property diversity so that subsets can be tuned for various applications. Through the design of 2D metamaterials with target displacement profiles, we demonstrate that smaller, diverse subsets can indeed improve the search process as well as structural performance. By eliminating inherent overlaps in a dataset of 3D unit cells created with symmetry rules, we also illustrate that our flexible method can distill unique subsets regardless of the metric employed. Our diverse subsets are provided publicly for use by any designer.
In Journal of Mechanical Design 2020
Collaborative work often benefits from having teams or organizations with heterogeneous members. In this paper, we present a method to form such diverse teams from people arriving sequentially over time. We define a monotone submodular objective function that combines the diversity and quality of a team and proposes an algorithm to maximize the objective while satisfying multiple constraints. This allows us to balance both how diverse the team is and how well it can perform the task at hand. Using crowd experiments, we show that, in practice, the algorithm leads to large gains in team diversity. Using simulations, we show how to quantify the additional cost of forming diverse teams and how to address the problem of simultaneously maximizing diversity for several attributes (e.g., country of origin and gender). Our method has applications in collaborative work ranging from team formation, the assignment of workers to teams in crowdsourcing, and reviewer allocation to journal papers arriving sequentially. Our code is publicly accessible for further research.
In Journal of Mechanical Design 2019
Assessing similarity between design ideas is an inherent part of many design evaluations to measure novelty. In such evaluation tasks, humans excel at making mental connections among diverse knowledge sets to score ideas on their uniqueness. However, their decisions about novelty are often subjective and difficult to explain. In this paper, we demonstrate a way to uncover human judgment of design idea similarity using two-dimensional (2D) idea maps. We derive these maps by asking participants for simple similarity comparisons of the form “Is idea A more similar to idea B or to idea C?” We show that these maps give insight into the relationships between ideas and help understand the design domain. We also propose that novel ideas can be identified by finding outliers on these idea maps. To demonstrate our method, we conduct experimental evaluations on two datasets—colored polygons (known answer) and milk frother sketches (unknown answer). We show that idea maps shed light on factors considered by participants in judging idea similarity and the maps are robust to noisy ratings. We also compare physical maps made by participants on a white-board to their computationally generated idea maps to compare how people think about spatial arrangement of design items. This method provides a new direction of research into deriving ground truth novelty metrics by combining human judgments and computational methods.
In Design Science 2018
Bisociative knowledge discovery is an approach that combines elements from two or more ‘incompatible’ domains to generate creative solutions and insight. Inspired by Koestler’s notion of bisociation, in this paper we propose a computational framework for the discovery of new connections between domains to promote creative discovery and inspiration in design. Specifically, we propose using topic models on a large collection of unstructured text ideas from multiple domains to discover creative sources of inspiration. We use these topics to generate a Bisociative Information Network – a graph that captures conceptual similarity between ideas – that helps designers find creative links within that network. Using a dataset of thousands of ideas from OpenIDEO, an online collaborative community, our results show usefulness of representing conceptual bridges through collections of words (topics) in finding cross-domain inspiration. We show that the discovered links between domains, whether presented on their own or via ideas they inspired, are perceived to be more novel and can also be used as creative stimuli for new idea generation.
In CSCW 2018
Following successful crowd ideation contests, organizations in search of the "next big thing" are left with hundreds of ideas. Expert-based idea filtering is lengthy and costly; therefore, crowd-based strategies are often employed. Unfortunately, these strategies typically (1) do not separate the mediocre from the excellent, and (2) direct all the attention to certain idea concepts, while others starve. We introduce DBLemons - a crowd-based idea filtering strategy that addresses these issues by (1) asking voters to identify the worst rather than the best ideas using a "bag of lemons'' voting approach, and (2) by exposing voters to a wider idea spectrum, thanks to a dynamic diversity-based ranking system balancing idea quality and coverage. We compare DBLemons against two state-of-the-art idea filtering strategies in a real-world setting. Results show that DBLemons is more accurate, less time-consuming, and reduces the idea space in half while still retaining 94% of the top ideas.
In Journal of Mechanical Design 2018
When selecting ideas or trying to find inspiration, designers often must sift through hundreds or thousands of ideas. This paper provides an algorithm to rank design ideas such that the ranked list simultaneously maximizes the quality and diversity of recommended designs. To do so, we first define and compare two diversity measures using determinantal point processes (DPP) and additive submodular functions. We show that DPPs are more suitable for items expressed as text and that a greedy algorithm diversifies rankings with both theoretical guarantees and empirical performance on what is otherwise an NP-Hard problem. To produce such rankings, this paper contributes a novel way to extend quality and diversity metrics from sets to permutations of ranked lists. These rank metrics open up the use of multi-objective optimization to describe trade-offs between diversity and quality in ranked lists. We use such trade-off fronts to help designers select rankings using indifference curves. However, we also show that rankings on trade-off front share a number of top-ranked items; this means reviewing items (for a given depth like the top ten) from across the entire diversity-to-quality front incurs only a marginal increase in the number of designs considered. While the proposed techniques are general purpose enough to be used across domains, we demonstrate concrete performance on selecting items in an online design community (OpenIDEO), where our approach reduces the time required to review diverse, high-quality ideas from around 25 h to 90 min. This makes evaluation of crowd-generated ideas tractable for a single designer. Our code is publicly accessible for further research.
In Applied Soft Computing 2016
This paper presents a constructive solid geometry based representation scheme for structural topology optimization. The proposed scheme encodes the topology using position of few joints and width of segments connecting them. Union of overlapping rectangular primitives is calculated using constructive solid geometry technique to obtain the topology. A valid topology in the design domain is ensured by representing the topology as a connected simple graph of nodes. A graph repair operator is applied to ensure a physically meaningful connected structure. The algorithm is integrated with single and multi-objective genetic algorithm and its performance is compared with those of other methods like SIMP. The multi-objective analysis provides the trade-off front between compliance and material availability, unveiling common design principles among optimized solutions. The proposed method is generic and can be easily extended to any two or three-dimensional topology optimization problem by using different shape primitives.
In Applied Soft Computing 2013
Selection of players for a sports team within a finite budget is a complex task which can be viewed as a constrained multi-objective optimization and a multiple criteria decision making problem. The task is specially challenging for the game of cricket where a team requires players who are efficient in multiple roles. In the formation of a good and successful cricket team, batting strength and bowling strength of a team are major factors affecting its performance and an optimum trade-off needs to be reached. We propose a novel gene representation scheme and a multi-objective approach using the NSGA-II algorithm to optimize the overall batting and bowling strength of a team with 11 players as variables. Fielding performance and a number of other cricketing criteria are also used in the optimization and decision-making process. Using the information from the trade-off front obtained, a multi-criteria decision making approach is then proposed for the final selection of team. Case studies using a set of players auctioned in Indian Premier League (IPL) 4th edition are illustrated and players’ current statistical data is used to define performance indicators. The proposed computational techniques are ready to be extended according to individualistic preferences of different franchises and league managers in order to form a preferred team within the budget constraints. It is also shown how such an analysis can help in dynamic auction environments, like selecting a team under player-by-player auction. The methodology is generic and can be easily extended to other sports like American football, baseball and other league games.
In Soft Computing 2013
A multi-objective vehicle path planning method has been proposed to optimize path length, path safety, and path smoothness using the elitist non-dominated sorting genetic algorithm—a well-known soft computing approach. Four different path representation schemes that begin their coding from the start point and move one grid at a time towards the destination point are proposed. Minimization of traveled distance and maximization of path safety are considered as objectives of this study while path smoothness is considered as a secondary objective. This study makes an extensive analysis of a number of issues related to the optimization of path planning task-handling of constraints associated with the problem, identifying an efficient path representation scheme, handling single versus multiple objectives, and evaluating the proposed algorithm on large-sized grids and having a dense set of obstacles. The study also compares the performance of the proposed algorithm with an existing GA-based approach. The evaluation of the proposed procedure against extreme conditions having a dense (as high as 91 %) placement of obstacles indicates its robustness and efficiency in solving complex path planning problems. The paper demonstrates the flexibility of evolutionary computing approaches in dealing with large-scale and multi-objective optimization problems.
In ICLR 2026
Bayesian optimization (BO) effectively optimizes expensive black-box functions but faces significant challenges in high-dimensional spaces (dimensions exceeding 100) due to the curse of dimensionality. Existing high-dimensional BO methods typically leverage low-dimensional embeddings or structural assumptions to mitigate this challenge, yet these approaches frequently incur considerable computational overhead and rigidity due to iterative surrogate retraining and fixed assumptions. To address these limitations, we propose Gradient-Informed Bayesian Optimization using Tabular Foundation Models (GIT-BO), an approach that utilizes a pre-trained tabular foundation model (TFM) as a surrogate, leveraging its gradient information to adaptively identify low-dimensional subspaces for optimization. We propose a way to exploit internal gradient computations from the TFM's forward pass by creating a gradient-informed diagnostic matrix that reveals the most sensitive directions of the TFM's predictions, enabling optimization in a continuously re-estimated active subspace without the need for repeated model retraining. Extensive empirical evaluation across 23 synthetic and real-world benchmarks demonstrates that GIT-BO consistently outperforms four state-of-the-art Gaussian process-based high-dimensional BO methods, showing superior scalability and optimization performances, especially as dimensionality increases up to 500 dimensions. This work establishes foundation models, augmented with gradient-informed adaptive subspace identification, as highly competitive alternatives to traditional Gaussian process-based approaches for high-dimensional Bayesian optimization tasks.
In NeurIPS 2025
Model merging, a method that combines the parameters and embeddings of multiple fine-tuned large language models (LLMs), offers a promising approach to enhance model performance across various tasks while maintaining computational efficiency. This paper introduces Activation-Informed Merging (AIM), a technique that integrates the information from the activation space of LLMs into the merging process to improve performance and robustness. AIM is designed as a flexible, complementary solution that is applicable to any existing merging method. It aims to preserve critical weights from the base model, drawing on principles from continual learning (CL) and model compression. Utilizing a task-agnostic calibration set, AIM selectively prioritizes essential weights during merging. We empirically demonstrate that AIM significantly enhances the performance of merged models across multiple benchmarks. Our findings suggest that considering the activation-space information can provide substantial advancements in the model merging strategies for LLMs, with up to a 40% increase in benchmark performance.
In NeurIPS 2025
Structural topology optimization (TO) is central to engineering design but remains computationally intensive due to complex physics and hard constraints. Existing deep-learning methods are limited to fixed square grids, a few hand-coded boundary conditions, and post-hoc optimization, preventing general deployment. We introduce Optimize Any Topology (OAT), a foundation-model framework that directly predicts minimum-compliance layouts for arbitrary aspect ratios, resolutions, volume fractions, loads, and fixtures. OAT combines a resolution- and shape-agnostic autoencoder with an implicit neural-field decoder and a conditional latent-diffusion model trained on OpenTO, a new corpus of 2.2 million optimized structures covering 2 million unique boundary-condition configurations. On four public benchmarks and two challenging unseen tests, OAT lowers mean compliance up to 90% relative to the best prior models and delivers sub-1 second inference on a single GPU across resolutions from 64 x 64 to 256 x 256 and aspect ratios as high as 10:1. These results establish OAT as a general, fast, and resolution-free framework for physics-aware topology optimization and provide a large-scale dataset to spur further research in generative modeling for inverse design.
In NeurIPS 2025
Computer-Aided Design (CAD) is a time-consuming and complex process, requiring precise, long-horizon user interactions with intricate 3D interfaces. While recent advances in AI-driven user interface (UI) agents show promise, most existing datasets and methods focus on short, low-complexity tasks in mobile or web applications, failing to capture the demands of professional engineering tools. In this work, we introduce VideoCAD, the first attempt at engineering UI interaction learning for precision tasks. Specifically, VideoCAD is a large-scale synthetic dataset consisting of over 41K annotated video recordings of CAD operations, generated using an automated framework for collecting high-fidelity UI action data from human-made CAD designs. Compared to existing datasets, VideoCAD offers an order of magnitude higher complexity in UI interaction learning for real-world engineering tasks, having up to a 20x longer time horizon than other datasets. We show two important downstream applications of VideoCAD: learning UI interactions from professional precision 3D CAD tools and a visual question-answering (VQA) benchmark designed to evaluate multimodal large language models' (LLM) spatial reasoning and video understanding abilities. To learn the UI interactions, we propose VideoCADFormer - a state-of-the-art model in learning CAD interactions directly from video, which outperforms multiple behavior cloning baselines. Both VideoCADFormer and the VQA benchmark derived from VideoCAD reveal key challenges in the current state of video-based UI understanding, including the need for precise action grounding, multi-modal and spatial reasoning, and long-horizon dependencies.
In NeurIPS 2025
We introduce Bike-Bench, an engineering design benchmark for evaluating generative models on problems with multiple real-world objectives and constraints. As generative AI's reach continues to grow, evaluating its capability to understand physical laws, human guidelines, and hard constraints grows increasingly important. Engineering product design lies at the intersection of these difficult tasks, providing new challenges for AI capabilities. Bike-Bench evaluates AI models' capability to generate designs that not only resemble the dataset, but meet specific performance objectives and constraints. To do so, Bike-Bench quantifies a variety of human-centered and multiphysics performance characteristics, such as aerodynamics, ergonomics, structural mechanics, human-rated usability, and similarity to subjective text or image prompts. Supporting the benchmark are several datasets of simulation results, a dataset of 10K human-rated bicycle assessments, and a synthetically-generated dataset of 1.4M designs, each with a parametric, CAD/XML, SVG, and PNG representation. Bike-Bench is uniquely configured to evaluate tabular generative models, LLMs, design optimization, and hybrid algorithms side-by-side. Our experiments indicate that LLMs and tabular generative models fall short of optimization and optimization-augmented generative models in both validity and optimality scores, suggesting significant room for improvement. We hope Bike-Bench, a first-of-its-kind benchmark, will help catalyze progress in generative AI for constrained multi-objective engineering design problems.
In IDETC 2025
BlendedNet is a publicly available aerodynamic dataset of 999 blended wing body (BWB) geometries. Each geometry is simulated across about nine flight conditions, yielding 8830 converged RANS cases with the Spalart-Allmaras model and 9 to 14 million cells per case. The dataset is generated by sampling geometric design parameters and flight conditions, and includes detailed pointwise surface quantities needed to study lift and drag. We also introduce an end-to-end surrogate framework for pointwise aerodynamic prediction. The pipeline first uses a permutation-invariant PointNet regressor to predict geometric parameters from sampled surface point clouds, then conditions a Feature-wise Linear Modulation (FiLM) network on the predicted parameters and flight conditions to predict pointwise coefficients Cp, Cfx, and Cfz. Experiments show low errors in surface predictions across diverse BWBs. BlendedNet addresses data scarcity for unconventional configurations and enables research on data-driven surrogate modeling for aerodynamic design.
In IDETC 2025
Efficient creation of accurate and editable 3D CAD models is critical in engineering design, significantly impacting cost and time-to-market in product innovation. Current manual workflows remain highly time-consuming and demand extensive user expertise. While recent developments in AI-driven CAD generation show promise, existing models are limited by incomplete representations of CAD operations, inability to generalize to real-world images, and low output accuracy. This paper introduces CAD-Coder, an open-source Vision-Language Model (VLM) explicitly fine-tuned to generate editable CAD code (CadQuery Python) directly from visual input. Leveraging a novel dataset that we created--GenCAD-Code, consisting of over 163k CAD-model image and code pairs--CAD-Coder outperforms state-of-the-art VLM baselines such as GPT-4.5 and Qwen2.5-VL-72B, achieving a 100% valid syntax rate and the highest accuracy in 3D solid similarity. Notably, our VLM demonstrates some signs of generalizability, successfully generating CAD code from real-world images and executing CAD operations unseen during fine-tuning. The performance and adaptability of CAD-Coder highlights the potential of VLMs fine-tuned on code to streamline CAD workflows for engineers and designers.
In IDETC 2025
The subjective evaluation of early stage engineering designs, such as conceptual sketches, traditionally relies on human experts. However, expert evaluations are time-consuming, expensive, and sometimes inconsistent. Recent advances in vision-language models (VLMs) offer the potential to automate design assessments, but it is crucial to ensure that these AI ``judges'' perform on par with human experts. However, no existing framework assesses expert equivalence. This paper introduces a rigorous statistical framework to determine whether an AI judge's ratings match those of human experts. We apply this framework in a case study evaluating four VLM-based judges on key design metrics (uniqueness, creativity, usefulness, and drawing quality). These AI judges employ various in-context learning (ICL) techniques, including uni- vs. multimodal prompts and inference-time reasoning. The same statistical framework is used to assess three trained novices for expert-equivalence. Results show that the top-performing AI judge, using text- and image-based ICL with reasoning, achieves expert-level agreement for uniqueness and drawing quality and outperforms or matches trained novices across all metrics. In 6/6 runs for both uniqueness and creativity, and 5/6 runs for both drawing quality and usefulness, its agreement with experts meets or exceeds that of the majority of trained novices. These findings suggest that reasoning-supported VLM models can achieve human-expert equivalence in design evaluation. This has implications for scaling design evaluation in education and practice, and provides a general statistical framework for validating AI judges in other domains requiring subjective content evaluation.
In IDETC 2025
We introduce the concept of 'Design Agents' for engineering applications, particularly focusing on the automotive design process, while emphasizing that our approach can be readily extended to other engineering and design domains. Our framework integrates AI-driven design agents into the traditional engineering workflow, demonstrating how these specialized computational agents interact seamlessly with engineers and designers to augment creativity, enhance efficiency, and significantly accelerate the overall design cycle. By automating and streamlining tasks traditionally performed manually, such as conceptual sketching, styling enhancements, 3D shape retrieval and generative modeling, computational fluid dynamics (CFD) meshing, and aerodynamic simulations, our approach reduces certain aspects of the conventional workflow from weeks and days down to minutes. These agents leverage state-of-the-art vision-language models (VLMs), large language models (LLMs), and geometric deep learning techniques, providing rapid iteration and comprehensive design exploration capabilities. We ground our methodology in industry-standard benchmarks, encompassing a wide variety of conventional automotive designs, and utilize high-fidelity aerodynamic simulations to ensure practical and applicable outcomes. Furthermore, we present design agents that can swiftly and accurately predict simulation outcomes, empowering engineers and designers to engage in more informed design optimization and exploration. This research underscores the transformative potential of integrating advanced generative AI techniques into complex engineering tasks, paving the way for broader adoption and innovation across multiple engineering disciplines.
In Dynamic Data Driven Applications Systems (DDDAS) 2024
Generative Artificial Intelligence has the potential to transform engineering sectors by enhancing design innovation and automating processes. However, despite advances in their data, training, and architectures, generative models still struggle to effectively and reliably satisfy constraints. This shortcoming presents a significant challenge with their adoption in engineering design tasks, where design constraints are ubiquitous. This difficulty is rooted in the similarity-based training objective of generative AI models, in which they learn to mimic the statistical distribution of a dataset of constraint-satisfying examples (positive data). We assert that generative models can be more effectively trained by examining constraint-violating examples (negative data) in addition to positive data. These “Negative Data Generative Models” (NDGMs) can thereby learn to avoid sampling from constraint-violating regions of the sample space. To demonstrate this principle, we propose a type of NDGM, then benchmark this formulation against vanilla models on two 2D test problems and two engineering design problems related to gearbox and concrete beam design. We showcase that NDGMs achieve significantly (2-30x) better constraint satisfaction compared to vanilla generative models. Moreover, they learn these constraints with only a fraction of the training data compared to vanilla generative models. Since NDGMs require only a handful of example to adjust their learned densities, they are significantly more agile and adaptable than vanilla generative models and may be much more effective in continuous data streams as seen in Dynamic Data-Driven Application Systems (DDDAS). Our findings suggest that NDGMs could play a crucial role in overcoming the constraints satisfaction challenges in current generative models, thereby broadening the scope and applicability of generative AI in critical engineering domains.
In NeurIPS 2024
We present DrivAerNet++, the largest and most comprehensive multimodal dataset for aerodynamic car design. DrivAerNet++ comprises 8,000 diverse car designs modeled with high-fidelity computational fluid dynamics (CFD) simulations. The dataset includes diverse car configurations such as fastback, notchback, and es- tateback, with different underbody and wheel designs to represent both internal combustion engines and electric vehicles. Each entry in the dataset features detailed 3D meshes, parametric models, aerodynamic coefficients, and extensive flow and surface field data, along with segmented parts for car classification and point cloud data. This dataset supports a wide array of machine learning applications including data-driven design optimization, generative modeling, surrogate model training, CFD simulation acceleration, and geometric classification. With more than 39 TB of publicly available engineering data, DrivAerNet++ fills a significant gap in available resources, providing high-quality, diverse data to enhance model training, promote generalization, and accelerate automotive design processes. Along with rigorous dataset validation, we also provide ML benchmarking results on the task of aerodynamic drag prediction, showcasing the breadth of applications supported by our dataset. This dataset is set to significantly impact automotive design and broader engineering disciplines by fostering innovation and improving the fidelity of aerodynamic evaluations.
In IDETC 2024
Topology optimization is a ubiquitous task in engineering design, involving the optimal distribution of material in a prescribed spatial domain. Recently, data-driven methods such as deep generative AI models have been proposed as an alternative to iterative optimization methods. However, existing data-driven approaches are often trained on datasets using fixed grid resolutions and domain shapes, reducing their applicability to different resolutions or different domain shapes. In this paper, we introduce two key innovations — a fast TO solver and a neural implicit field architecture to address these limitations. First, we introduce a fast, parallelizable, iterative GPU-based TO solver optimized for high-throughput dataset generation for 3D unstructured meshes. Our solver generated 122K optimized 3D topologies, an order of magnitude more than the largest existing public dataset. Second, we introduce a new resolution-free data-driven method for 3D topologies using neural fields, called NITO-3D. A single NITO-3D model trains and predicts for a variety of resolutions and aspect ratios. By also eliminating the need for computationally intensive physical field conditioning, NITO-3D offers a faster, more flexible alternative for 3D topology optimization. On average, NITO-3D generates topologies roughly 2000 times faster and with only 0.3% higher compliance than state-of-the-art iterative solvers. With 10 steps of iterative fine-tuning, NITO-3D is on average 15 times faster and generates topologies that are under 0.1% more compliant than SIMP’s. We open-source all data and code associated with this work at https://github.com/Lyleregenwetter/NITO-3D/.
In IDETC 2024
Our study introduces a Generative AI method that employs a cooling-guided diffusion model to optimize the layout of battery cells, a crucial step for enhancing the cooling performance and efficiency of battery thermal management systems. Traditional design processes, which rely heavily on iterative optimization and extensive guesswork, are notoriously slow and inefficient, often leading to suboptimal solutions. In contrast, our innovative method uses a parametric denoising diffusion probabilistic model (DDPM) with classifier and cooling guidance to generate optimized cell layouts with enhanced cooling paths, significantly lowering the maximum temperature of the cells. By incorporating position-based classifier guidance, we ensure the feasibility of generated layouts. Meanwhile, cooling guidance directly optimizes cooling-efficiency, making our approach uniquely effective. When compared to two advanced models, the Tabular Denoising Diffusion Probabilistic Model (TabDDPM) and the Conditional Tabular GAN (CTGAN), our cooling-guided diffusion model notably outperforms both. It is five times more effective than TabDDPM and sixty-six times better than CTGAN across key metrics such as feasibility, diversity, and cooling efficiency. This research marks a significant leap forward in the field, aiming to optimize battery cell layouts for superior cooling efficiency, thus setting the stage for the development of more effective and dependable battery thermal management systems.
In IDETC 2024
This research introduces DesignQA, a novel benchmark aimed at evaluating the proficiency of multimodal large language models (MLLMs) in comprehending and applying engineering requirements in technical documentation. Developed with a focus on real-world engineering challenges, DesignQA uniquely combines multimodal data-including textual design requirements, CAD images, and engineering drawings-derived from the Formula SAE student competition. Different from many existing MLLM benchmarks, DesignQA contains document-grounded visual questions where the input image and input document come from different sources. The benchmark features automatic evaluation metrics and is divided into segments-Rule Comprehension, Rule Compliance, and Rule Extraction-based on tasks that engineers perform when designing according to requirements. We evaluate state-of-the-art models like GPT4 and LLaVA against the benchmark, and our study uncovers the existing gaps in MLLMs' abilities to interpret complex engineering documentation. Key findings suggest that while MLLMs demonstrate potential in navigating technical documents, substantial limitations exist, particularly in accurately extracting and applying detailed requirements to engineering designs. This benchmark sets a foundation for future advancements in AI-supported engineering design processes. DesignQA is publicly available at: https://github.com/anniedoris/design_qa/.
In IDETC 2024
This study introduces a generative imputation model leveraging graph attention networks and tabular diffusion models for completing missing parametric data in engineering designs. This model functions as an AI design co-pilot, providing multiple design options for incomplete designs, which we demonstrate using the bicycle design CAD dataset. Through comparative evaluations, we demonstrate that our model significantly outperforms existing classical methods, such as MissForest, hotDeck, PPCA, and tabular generative method TabCSDI in both the accuracy and diversity of imputation options. Generative modeling also enables a broader exploration of design possibilities, thereby enhancing design decision-making by allowing engineers to explore a variety of design completions. The graph model combines GNNs with the structural information contained in assembly graphs, enabling the model to understand and predict the complex interdependencies between different design parameters. The graph model helps accurately capture and impute complex parametric interdependencies from an assembly graph, which is key for design problems. By learning from an existing dataset of designs, the imputation capability allows the model to act as an intelligent assistant that autocompletes CAD designs based on user-defined partial parametric design, effectively bridging the gap between ideation and realization. The proposed work provides a pathway to not only facilitate informed design decisions but also promote creative exploration in design.
In IDETC 2024 (Awarded "Papers of Distinction")
This study introduces DrivAerNet, a large-scale high- fidelity CFD dataset of 3D industry-standard car shapes, and RegDGCNN, a dynamic graph convolutional neural network model, both aimed at aerodynamic car design through machine learning. DrivAerNet, with its 4000 detailed 3D car meshes using 0.5 million surface mesh faces and comprehensive aerodynamic performance data comprising of full 3D pressure, velocity fields, and wall-shear stresses, addresses the critical need for extensive datasets to train deep learning models in engineering applica- tions. It is 60% larger than the previously available largest public dataset of cars, and is the only open-source dataset that also models wheels and underbody. RegDGCNN leverages this large- scale dataset to provide high-precision drag estimates directly from 3D meshes, bypassing traditional limitations such as the need for 2D image rendering or Signed Distance Fields (SDF). By enabling fast drag estimation in seconds, RegDGCNN facili- tates rapid aerodynamic assessments, offering a substantial leap towards integrating data-driven methods in automotive design. Together, DrivAerNet and RegDGCNN promise to accelerate the car design process and contribute to the development of more efficient vehicles. To lay the groundwork for future innovations in the field, the dataset and code used in our study are publicly accessible at https://github.com/Mohamedelrefaie/DrivAerNet1.
In IDETC 2024
Text-to-image generative models have increasingly been used to assist designers during concept generation in various creative domains, such as graphic design, user interface design, and fashion design. However, their applications in engineering design remain limited due to the models' challenges in generating images of feasible designs concepts. To address this issue, this paper introduces a method that improves the design feasibility by prompting the generation with feasible CAD images. In this work, the usefulness of this method is investigated through a case study with a bike design task using an off-the-shelf text-to-image model, Stable Diffusion 2.1. A diverse set of bike designs are produced in seven different generation settings with varying CAD image prompting weights, and these designs are evaluated on their perceived feasibility and novelty. Results demonstrate that the CAD image prompting successfully helps text-to-image models like Stable Diffusion 2.1 create visibly more feasible design images. While a general tradeoff is observed between feasibility and novelty, when the prompting weight is kept low around 0.35, the design feasibility is significantly improved while its novelty remains on par with those generated by text prompts alone. The insights from this case study offer some guidelines for selecting the appropriate CAD image prompting weight for different stages of the engineering design process. When utilized effectively, our CAD image prompting method opens doors to a wider range of applications of text-to-image models in engineering design.
In International Marine Design Conference 2024
Ship design is a complex design process that may take a team of naval architects many years to complete. Improving the ship design process can lead to significant cost savings, while still delivering high-quality designs to customers. A new technology for ship hull design is diffusion models, a type of generative artificial intelligence. Prior work with diffusion models for ship hull design created high-quality ship hulls with reduced drag and larger displaced volumes. However, the work could not generate hulls that meet specific design constraints. This paper proposes a conditional diffusion model that generates hull designs given specific constraints, such as the desired principal dimensions of the hull. In addition, this diffusion model leverages the gradients from a total resistance regression model to create low-resistance designs. Five design test cases compared the diffusion model to a design optimization algorithm to create hull designs with low resistance. In all five test cases, the diffusion model was shown to create diverse designs with a total resistance less than the optimized hull, having resistance reductions over 25%. The diffusion model also generated these designs without retraining. This work can significantly reduce the design cycle time of ships by creating high-quality hulls that meet user requirements with a data-driven approach.
In DESIGN 2024
Sketch2Prototype is an AI-based framework that transforms a hand-drawn sketch into a diverse set of 2D images and 3D prototypes through sketch-to-text, text-to-image, and image-to-3D stages. This framework, shown across various sketches, rapidly generates text, image, and 3D modalities for enhanced early-stage design exploration. We show that using text as an intermediate modality outperforms direct sketch-to-3D baselines for generating diverse and manufacturable 3D models. We find limitations in current image-to-3D techniques, while noting the value of the text modality for user-feedback.
In NeurIPS 2023
Generative models have had a profound impact on vision and language, paving the way for a new era of multimodal generative applications. While these successes have inspired researchers to explore using generative models in science and engineering to accelerate the design process and reduce the reliance on iterative optimization, challenges remain. Specifically, engineering optimization methods based on physics still outperform generative models when dealing with constrained environments where data is scarce and precision is paramount. To address these challenges, we introduce Diffusion Optimization Models (DOM) and Trajectory Alignment (TA), a learning framework that demonstrates the efficacy of aligning the sampling trajectory of diffusion models with the optimization trajectory derived from traditional physics-based methods. This alignment ensures that the sampling process remains firmly grounded in the underlying physical principles. Our method allows for generating feasible and high-performance designs in as few as two steps without the need for expensive preprocessing, external surrogate models, or additional labeled data. DOM also integrates an efficient conditioning approximation to speed up inference and a few steps of direct optimization to guide the process explicitly toward regions with superior manufacturability and performance. We apply our framework to structural topology optimization, a fundamental problem in mechanical design, evaluating its performance on in- and out-of-distribution configurations. Our results demonstrate that Trajectory Alignment outperforms state-of-the-art deep generative models on in-distribution configurations and halves the inference computational cost. When coupled with a few steps of optimization, it also improves manufacturability for out-of-distribution conditions. DOM shows the effectiveness of combining learning and optimization trajectories. By significantly improving engineering performance and inference efficiency, it enables us to generate high-quality designs in just a few steps and guide them toward regions of high performance and manufacturability, paving the way for the widespread application of generative models in large-scale data-driven design.
In IDETC 2023
We introduce Multi-Objective Counterfactuals for Design (MCD), a novel method for counterfactual optimization in design problems. Counterfactuals are hypothetical situations that can lead to a different decision or choice. In this paper, the authors frame the counterfactual search problem as a design recommendation tool that can help identify modifications to a design, leading to better functional performance. MCD improves upon existing counterfactual search methods by supporting multi-objective queries, which are crucial in design problems, and by decoupling the counterfactual search and sampling processes, thus enhancing efficiency and facilitating objective tradeoff visualization. The paper demonstrates MCD's core functionality using a two-dimensional test case, followed by three case studies of bicycle design that showcase MCD's effectiveness in real-world design problems. In the first case study, MCD excels at recommending modifications to query designs that can significantly enhance functional performance, such as weight savings and improvements to the structural safety factor. The second case study demonstrates that MCD can work with a pre-trained language model to suggest design changes based on a subjective text prompt effectively. Lastly, the authors task MCD with increasing a query design's similarity to a target image and text prompt while simultaneously reducing weight and improving structural performance, demonstrating MCD's performance on a complex multimodal query. Overall, MCD has the potential to provide valuable recommendations for practitioners and design automation researchers looking for answers to their "What if" questions by exploring hypothetical design modifications and their impact on multiple design objectives.
In IDETC 2023 (Awarded "Papers of Distinction")
Generative AI models have made significant progress in automating the creation of 3D shapes, which has the potential to transform car design. In engineering design and optimization, evaluating engineering metrics is crucial. To make generative models performance-aware and enable them to create high-performing designs, surrogate modeling of these metrics is necessary. However, the currently used representations of three-dimensional (3D) shapes either require extensive computational resources to learn or suffer from significant information loss, which impairs their effectiveness in surrogate modeling. To address this issue, we propose a new two-dimensional (2D) representation of 3D shapes. We develop a surrogate drag model based on this representation to verify its effectiveness in predicting 3D car drag. We construct a diverse dataset of 9,070 high-quality 3D car meshes labeled by drag coefficients computed from computational fluid dynamics (CFD) simulations to train our model. Our experiments demonstrate that our model can accurately and efficiently evaluate drag coefficients with an R^2 value above 0.84 for various car categories. Moreover, the proposed representation method can be generalized to many other product categories beyond cars. Our model is implemented using deep neural networks, making it compatible with recent AI image generation tools (such as Stable Diffusion) and a significant step towards the automatic generation of drag-optimized car designs. We have made the dataset and code publicly available at https://decode.mit.edu/projects/dragprediction/.
In IDETC 2023
Accurate vehicle rating prediction can facilitate designing and configuring good vehicles. This prediction allows vehicle designers and manufacturers to optimize and improve their designs in a timely manner, enhance their product performance, and effectively attract consumers. However, most of the existing data-driven methods rely on data from a single mode, e.g., text, image, or parametric data, which results in a limited and incomplete exploration of the available information. These methods lack comprehensive analyses and exploration of data from multiple modes, which probably leads to inaccurate conclusions and hinders progress in this field. To overcome this limitation, we propose a multi-modal learning model for more comprehensive and accurate vehicle rating predictions. Specifically, the model simultaneously learns features from the parametric specifications, text descriptions, and images of vehicles to predict five vehicle rating scores, including the total score, critics score, performance score, safety score, and interior score. We compare the multi-modal learning model to the corresponding unimodal models and find that the multi-modal model's explanatory power is 4% - 12% higher than that of the unimodal models. On this basis, we conduct sensitivity analyses using SHAP to interpret our model and provide design and optimization directions to designers and manufacturers. Our study underscores the importance of the data-driven multi-modal learning approach for vehicle design, evaluation, and optimization. We have made the code publicly available at https://decode.mit.edu/projects/vehicleratings/.
In IDETC 2023
Computational Fluid Dynamics (CFD) is widely used in different engineering fields, but accurate simulations are dependent upon proper meshing of the simulation domain. While highly refined meshes may ensure precision, they come with high computational costs. Similarly, adaptive remeshing techniques require multiple simulations and come at a great computational cost. This means that the meshing process is reliant upon expert knowledge and years of experience. Automating mesh generation can save significant time and effort and lead to a faster and more efficient design process. This paper presents a machine learning-based scheme that utilizes Graph Neural Networks (GNN) and expert guidance to automatically generate CFD meshes for aircraft models. In this work, we introduce a new 3D segmentation algorithm that outperforms two state-of-the-art models, PointNet++ and PointMLP, for surface classification. We also present a novel approach to project predictions from 3D mesh segmentation models to CAD surfaces using the conformal predictions method, which provides marginal statistical guarantees and robust uncertainty quantification and handling. We demonstrate that the addition of conformal predictions effectively enables the model to avoid under-refinement, hence failure, in CFD meshing even for weak and less accurate models. Finally, we demonstrate the efficacy of our approach through a real-world case study that demonstrates that our automatically generated mesh is comparable in quality to expert-generated meshes, and enables the solver to converge and produce accurate results. The code and data for this project is made publicly available at https://github.com/ahnobari/AutoSurf.
In IDETC 2023
Exploiting the recent advancements in artificial intelligence, showcased by ChatGPT and DALL-E, in real-world applications necessitates vast, domain-specific, and publicly accessible datasets. Unfortunately, the scarcity of such datasets poses a significant challenge for researchers aiming to apply these breakthroughs in engineering design. Synthetic datasets emerge as a viable alternative. However, practitioners are often uncertain about generating high-quality datasets that accurately represent real-world data and are suitable for the intended downstream applications. This study aims to fill this knowledge gap by proposing comprehensive guidelines for generating, annotating, and validating synthetic datasets. The trade-offs and methods associated with each of these aspects are elaborated upon. Further, the practical implications of these guidelines are illustrated through the creation of a turbo-compressors dataset. The study underscores the importance of thoughtful sampling methods to ensure the appropriate size, diversity, utility, and realism of a dataset. It also highlights that design diversity does not equate to performance diversity or realism. By employing test sets that represent uniform, real, or task-specific samples, the influence of sample size and sampling strategy is scrutinized. Overall, this paper offers valuable insights for researchers intending to create and publish synthetic datasets for engineering design, thereby paving the way for more effective applications of AI advancements in the field. The code and data for the dataset and methods are made publicly accessible at https://github.com/cyrilpic/radcomp.
In IDETC 2023
Machine learning has recently made significant strides in reducing design cycle time for complex products. Ship design, which currently involves years-long cycles and small batch production, could greatly benefit from these advancements. By developing a machine learning tool for ship design that learns from the design of many different types of ships, trade-offs in ship design could be identified and optimized. However, the lack of publicly available ship design datasets currently limits the potential for leveraging machine learning in generalized ship design. To address this gap, this paper presents a large dataset of 30,000 ship hulls, each with design and functional performance information, including parameterization, mesh, point-cloud, and image representations, as well as 32 hydrodynamic drag measures under different operating conditions. The dataset is structured to allow human input and is also designed for computational methods. Additionally, the paper introduces a set of 12 ship hulls from publicly available CAD repositories to showcase the proposed parameterizations ability to accurately reconstruct existing hulls. A surrogate model was developed to predict the 32 wave drag coefficients, which was then implemented in a genetic algorithm case study to reduce the total drag of a hull by 60 percent while maintaining the shape of the hulls cross section and the length of the parallel midbody. Our work provides a comprehensive dataset and application examples for other researchers to use in advancing data-driven ship design.
In IDETC 2023 (Awarded "Papers of Distinction")
When designing evidence-based policies and programs, decision-makers must distill key information from a vast and rapidly growing literature base. Identifying relevant literature from raw search results is time and resource intensive, and is often done by manual screening. In this study, we develop an AI agent based on a bidirectional encoder representations from transformers (BERT) model and incorporate it into a human team designing an evidence synthesis product for global development. We explore the effectiveness of the human-AI hybrid team in accelerating the evidence synthesis process. To further improve team efficiency, we enhance the human-AI hybrid team through active learning (AL). Specifically, we explore different sampling strategies, including random sampling, least confidence (LC) sampling, and highest priority (HP) sampling, to study their influence on the collaborative screening process. Results show that incorporating the BERT-based AI agent into the human team can reduce the human screening effort by 68.5% compared to the case of no AI assistance and by 16.8% compared to the case of using a support vector machine (SVM)-based AI agent for identifying 80% of all relevant documents. When we apply the HP sampling strategy for AL, the human screening effort can be reduced even more: by 78.3% for identifying 80% of all relevant documents compared to no AI assistance. We apply the AL-enhanced human-AI hybrid teaming workflow in the design process of three evidence gap maps (EGMs) for USAID and find it to be highly effective. These findings demonstrate how AI can accelerate the development of evidence synthesis products and promote timely evidence-based decision making in global development in a human-AI hybrid teaming context.
In IDETC 2023
Topology Optimization seeks to find the best design that satisfies a set of constraints while maximizing system performance. Traditional iterative optimization methods like SIMP can be computationally expensive and get stuck in local minima, limiting their applicability to complex or large-scale problems. Learning-based approaches have been developed to accelerate the topology optimization process, but these methods can generate designs with floating material and low performance when challenged with out-of-distribution constraint configurations. Recently, deep generative models, such as Generative Adversarial Networks and Diffusion Models, conditioned on constraints and physics fields have shown promise, but they require extensive pre-processing and surrogate models for improving performance. To address these issues, we propose a Generative Optimization method that integrates classic optimization like SIMP as a refining mechanism for the topology generated by a deep generative model. We also remove the need for conditioning on physical fields using a computationally inexpensive approximation inspired by classic ODE solutions and reduce the number of steps needed to generate a feasible and performant topology. Our method allows us to efficiently generate good topologies and explicitly guide them to regions with high manufacturability and high performance, without the need for external auxiliary models or additional labeled data. We believe that our method can lead to significant advancements in the design and optimization of structures in engineering applications, and can be applied to a broader spectrum of performance-aware engineering design problems.
In AAAI 2023
Structural topology optimization, which aims to find the optimal physical structure that maximizes mechanical performance, is vital in engineering design applications in aerospace, mechanical, and civil engineering. Generative adversarial networks (GANs) have recently emerged as a popular alternative to traditional iterative topology optimization methods. However, these models are often difficult to train, have limited generalizability, and due to their goal of mimicking optimal structures, neglect manufacturability and performance objectives like mechanical compliance. We propose TopoDiff - a conditional diffusion-model-based architecture to perform performance-aware and manufacturability-aware topology optimization that overcomes these issues. Our model introduces a surrogate model-based guidance strategy that actively favors structures with low compliance and good manufacturability. Our method significantly outperforms a state-of-art conditional GAN by reducing the average error on physical performance by a factor of eight and by producing eleven times fewer infeasible samples. By introducing diffusion models to topology optimization, we show that conditional diffusion models have the ability to outperform GANs in engineering design synthesis applications too. Our work also suggests a general framework for engineering optimization problems using diffusion models and external performance with constraint-aware guidance. We publicly share the data, code, and trained models.
In IDETC 2022
In this paper, we introduce LINKS, a dataset of 100 million one degree of freedom planar linkage mechanisms and 1.1 billion coupler curves, which is more than 1000 times larger than any existing database of planar mechanisms and is not limited to specific kinds of mechanisms such as four-bars, six-bars, etc. which are typically what most databases include. LINKS is made up of various components including 100 million mechanisms, the simulation data for each mechanism, normalized paths generated by each mechanism, a curated set of paths, the code used to generate the data and simulate mechanisms, and a live web demo for interactive design of linkage mechanisms. The curated paths are provided as a measure for removing biases in the paths generated by mechanisms that enable a more even design space representation. In this paper, we discuss the details of how we can generate such a large dataset and how we can overcome major issues with such scales. To be able to generate such a large dataset we introduce a new operator to generate 1-DOF mechanism topologies, furthermore, we take many steps to speed up slow simulations of mechanisms by vectorizing our simulations and parallelizing our simulator on a large number of threads, which leads to a simulation 800 times faster than the simple simulation algorithm. This is necessary given on average, 1 out of 500 candidates that are generated are valid~(and all must be simulated to determine their validity), which means billions of simulations must be performed for the generation of this dataset. Then we demonstrate the depth of our dataset through a bi-directional chamfer distance-based shape retrieval study where we show how our dataset can be used directly to find mechanisms that can trace paths very close to desired target paths.
In IDETC 2022
Deep Generative Machine Learning Models have been growing in popularity across the design community thanks to their ability to learn and mimic complex data distributions. While early works are promising, further advancement will depend on addressing several critical considerations such as design quality, feasibility, novelty, and targeted inverse design. We propose the Design Target Achievement Index (DTAI), a differentiable, tunable metric that scores a design’s ability to achieve designer-specified minimum performance targets. We demonstrate that DTAI can drastically improve the performance of generated designs when directly used as a training loss in Deep Generative Models. We apply the DTAI loss to a Performance- Augmented Diverse GAN (PaDGAN) and demonstrate superior generative performance compared to a set of baseline Deep Generative Models including a Multi-Objective PaDGAN and specialized tabular generation algorithms like the Conditional Tabular GAN (CTGAN).We further enhance PaDGAN with an auxiliary feasibility classifier to encourage feasible designs. To evaluate methods, we propose a comprehensive set of evaluation metrics for generative methods that focus on feasibility, diversity, and satisfaction of design performance targets. Methods are tested on a challenging benchmarking problem- the FRAMED bicycle frame design dataset featuring mixed-datatype parametric data, heavily skewed and multimodal distributions, and ten competing performance objectives.
In IDETC 2022
Measuring design creativity is an indispensable component of innovation in engineering design. Properly assessing the creativity of a design requires a rigorous evaluation of the outputs. Traditional methods to evaluate designs are slow, expensive, and difficult to scale because they rely on human expert input. An alternative approach is to use computational methods to evaluate designs. However, most existing methods have limited utility because they are constrained to unimodal design representations (e.g., texts or sketches) and small datasets. To overcome these limitations, we propose a multimodal transfer learning-based machine learning model to predict five design metrics- drawing quality, uniqueness, elegance, usefulness, and creativity. The proposed model utilizes knowledge from large external datasets through transfer learning and simultaneously processes text and sketch data from early-phase concepts through multi-modal learning. Through six unimodal models using only texts or sketches, we show that transfer learning improves the predictive validity of text learning and sketch learning by 2%–18% and 9%–24%, respectively, for design metric evaluation. By comparing our multimodal model with the best unimodal models, we demonstrate that joining unimodal text and sketch learning models further increases the predictive validity of the approach by 4%–10%. The proposed models are generalizable to many application contexts beyond design concepts. Our findings highlight the importance of analyzing designs from multiple perspectives for design assessment. Finally, we discuss the challenges and opportunities in developing AI models for design metric evaluation.
In IDETC 2022
The placement of objects on a ship is critical to many facets of the performance of a ship. Most notably, the mass distribution properties of objects in a ship affect the ship’s stability, trim, and structural loading. Information gathered from object placement optimization can allow naval architects to further optimize the design of the whole ship by potentially reducing the structural weight of the vessel, and adjusting the shape of the hull or the general arrangements based on available space in the ship. This paper presents a novel, many-objective bin packing problem for object placement across multiple decks on a ship. This problem is also highly constrained to avoid object intersection and protrusion. The problem was optimized with the NSGA-II algorithm, utilizing a heuristic population initialization and by separating the objectives into a bilevel optimization scheme. The bilevel scheme decouples certain objectives and design variables from the rest of the problem and sequences the evaluation for the objectives in a two-stage process. The hypervolume of the final population measured the performance of the optimization test. The results indicate that sequencing the objectives with a bilevel scheme produces an 80.3% larger hypervolume than an all-in-one optimization for the same problem. The findings from this study provide a systematic way by combining concepts from many-objective optimization, bin packing heuristics, and bilevel optimization to sequence the optimization of many-objective, object placement problems.
In Design 2022
Deep learning (DL) from various representations have succeeded in many fields. However, we know little about the machine learnability of distinct design representations when using DL to predict design performance. This paper proposes a graph representation for designs and compares it to the common image representation. We employ graph neural networks (GNNs) and convolutional neural networks (CNNs) respectively to learn them to predict drone performance. GCNs outperform CNNs by 2.6-8.1% in predictive validity. We argue that graph learning is a powerful and generalizable method for such tasks.
In ACM KDD 2021
Engineering design tasks often require synthesizing new designs that meet desired performance requirements. The conventional design process, which requires iterative optimization and performance evaluation, is slow and dependent on initial designs. Past work has used conditional generative adversarial networks (cGANs) to enable direct design synthesis for given target performances. However, most existing cGANs are restricted to categorical conditions. Recent work on Continuous conditional GAN (CcGAN) tries to address this problem, but still faces two challenges- 1) it performs poorly on non-uniform performance distributions, and 2) the generated designs may not cover the entire design space. We propose a new model, named Performance Conditioned Diverse Generative Adversarial Network (PcDGAN), which introduces a singular vicinal loss combined with a Determinantal Point Processes (DPP) based loss function to enhance diversity. PcDGAN uses a new self-reinforcing score called the Lambert Log Exponential Transition Score (LLETS) for improved conditioning. Experiments on synthetic problems and a real-world airfoil design problem demonstrate that PcDGAN outperforms state-of-the-art GAN models and improves the conditioning likelihood by 69% in an airfoil generation task and up to 78% in synthetic conditional generation tasks and achieves greater design space coverage. The proposed method enables efficient design synthesis and design space exploration with applications ranging from CAD model generation to metamaterial selection.
In IDETC 2021
In this paper, we present “BIKED,” a dataset comprised of 4500 individually designed bicycle models sourced from hundreds of designers. We expect BIKED to enable a variety of data-driven design applications for bicycles and support the development of data-driven design methods. The dataset is comprised of a variety of design information including assembly images, component images, numerical design parameters, and class labels. In this paper, we first discuss the processing of the dataset, then highlight some prominent research questions that BIKED can help address. Of these questions, we further explore the following in detail- 1) Are there prominent gaps in the current bicycle market and design space? We explore the design space using unsupervised dimensionality reduction methods. 2) How does one identify the class of a bicycle and what factors play a key role in defining it? We address the bicycle classification task by training a multitude of classifiers using different forms of design data and identifying parameters of particular significance through permutation-based interpretability analysis. 3) How does one synthesize new bicycles using different representation methods? We consider numerous machine learning methods to generate new bicycle models as well as interpolate between and extrapolate from existing models using Variational Autoencoders. The dataset is available along with referenced code.
In IDETC 2021
Modern machine learning techniques, such as deep neural networks, are transforming many disciplines ranging from image recognition to language understanding, by uncovering patterns in big data and making accurate predictions. They have also shown promising results for synthesizing new designs, which is crucial for creating products and enabling innovation. Generative models, including generative adversarial networks (GANs), have proven to be effective for design synthesis with applications ranging from product design to metamaterial design. These automated computational design methods can support human designers, who typically create designs by a time-consuming process of iteratively exploring ideas using experience and heuristics. However, there are still challenges remaining in automatically synthesizing ‘creative’ designs. GAN models, however, are not capable of generating unique designs, a key to innovation and a major gap in AI-based design automation applications. This paper proposes an automated method, named CreativeGAN, for generating novel designs. It does so by identifying components that make a design unique and modifying a GAN model such that it becomes more likely to generate designs with identified unique components. The method combines state-of-art novelty detection, segmentation, novelty localization, rewriting, and generative models for creative design synthesis. Using a dataset of bicycle designs, we demonstrate that the method can create new bicycle designs with unique frames and handles, and generalize rare novelties to a broad set of designs. Our automated method requires no human intervention and demonstrates a way to rethink creative design synthesis and exploration.
In IDETC 2021
Typical engineering design tasks require the effort to modify designs iteratively until they meet certain constraints, i.e., performance or attribute requirements. Past work has proposed ways to solve the inverse design problem, where desired designs are directly generated from specified requirements, thus avoid the trial and error process. Among those approaches, the conditional deep generative model shows great potential since 1) it works for complex high-dimensional designs and 2) it can generate multiple alternative designs given any condition. In this work, we propose a conditional deep generative model, Range-GAN, to achieve automatic design synthesis subject to range constraints. The proposed model addresses the sparse conditioning issue in data-driven inverse design problems by introducing a label-aware self-augmentation approach. We also propose a new uniformity loss to ensure generated designs evenly cover the given requirement range. Through a real-world example of constrained 3D shape generation, we show that the label-aware self-augmentation leads to an average improvement of 14% on the constraint satisfaction for generated 3D shapes, and the uniformity loss leads to a 125% average increase on the uniformity of generated shapes’ attributes. This work laid the foundation for data-driven inverse design problems where we consider range constraints and there are sparse regions in the condition space.
In IDETC 2021
A picture is worth a thousand words, and in design metric estimation, a word may be worth a thousand features. Pictures are awarded this worth because of their ability to encode a plethora of information. When evaluating designs, we aim to capture a range of information as well, information including usefulness, uniqueness, and novelty of a design. The subjective nature of these concepts makes their evaluation difficult. Despite this, many attempts have been made and metrics developed to do so, because design evaluation is integral to innovation and the creation of novel solutions. The most common metrics used are the consensual assessment technique (CAT) and the Shah, Vargas-Hernandez, and Smith (SVS) method. While CAT is accurate and often regarded as the “gold standard,” it heavily relies on using expert ratings as a basis for judgement, making CAT expensive and time consuming. Comparatively, SVS is less resource-demanding, but it is often criticized as lacking sensitivity and accuracy. We aim to take advantage of the distinct strengths of both methods through machine learning. More specifically, this study seeks to investigate the possibility of using machine learning to facilitate automated creativity assessment. The SVS method results in a text-rich dataset about a design. In this paper we utilize these textual design representations and the deep semantic relationships that words and sentences encode, to predict more desirable design metrics, including CAT metrics. We demonstrate the ability of machine learning models to predict design metrics from the design itself and SVS Survey information. We demonstrate that incorporating natural language processing (NLP) improves prediction results across all of our design metrics, and that clear distinctions in the predictability of certain metrics exist.
In IDETC 2021
Estimating the form and functional performance of a design in the early stages can be crucial for a designer for effective ideation Humans have an innate ability to guess the size, shape, and type of a design from a single view. The brain fills in the unknowns in a fraction of a second. However, humans may struggle with estimating the performance of designs in the early stages of the design process without making prototypes or doing back-of-the-envelope calculations. In contrast, machines need information about the full 3D model of a design to understand its structure. Machines can estimate the performance using pre-defined rules, expensive numerical simulations, or machine learning models. In this paper, we show how information about the form and functional performance of a design can be estimated from a single image using machine learning methods. Specifically, we leverage the image-to-image translation method to predict multiple projections of an image-based design. We then train deep neural network models on the predicted projections to provide estimates of design performance. We demonstrate the effectiveness of our method by predicting the aerodynamic performance from images of aircraft models. To estimate ground truth aero-dynamic performance, we run CFD simulations for 4045 3D aircraft models from the ShapeNet dataset and use their lift-to-drag ratio as the performance metric. Our results show that single images do carry information for both form and functional performance. From a single image, we are able to produce six additional images of a design in different orientations, with an average Structural Similarity Index score of 0.872. We also find image-translation methods provide a promising direction in estimating the performance of design. Using multiple images of a design (gathered through image-translation) to predict design performance yields a recall value of 47%, which is 14% higher than a base guess, and 3% higher than using a single image. Our work identifies the potential and provides a framework for using a single image to predict the form and functional performance of a design during the early-stage design process. Our code and additional information about our work are available.
In IDETC 2021
Graph representation learning has revolutionized many artificial intelligence and machine learning tasks in recent years, ranging from combinatorial optimization, drug discovery, recommendation systems, image classification, social network analysis to natural language understanding. This paper shows their efficacy in modeling relationships between products and making predictions for unseen product networks. By representing products as nodes and their relationships as edges of a graph, we show how an inductive graph neural network approach, named GraphSAGE, can efficiently learn continuous representations for nodes and edges. These representations also capture product feature information such as price, brand, and engineering attributes. They are combined with a classification model for predicting the existence of a relationship between any two products. Using a case study of the Chinese car market, we find that our method yields double the F-1 score compared to an Exponential Random Graph Model-based method for predicting the co-consideration relationship between cars. While a vanilla Graph-SAGE requires a partial network to make predictions, we augment it with an ‘adjacency prediction model’ to circumvent this limitation. This enables us to predict product relationships when no neighborhood information is known. Finally, we demonstrate how a permutation-based interpretability analysis can provide insights on how design attributes impact the predictions of relationships between products. Overall, this work provides a systematic method to predict the relationships between products in a complex engineering system.
In IJCAI 2020
Bipartite b-matching, where agents on one side of a market are matched to one or more agents or items on the other, is a classical model that is used in myriad application areas such as healthcare, advertising, education, and general resource allocation. Traditionally, the primary goal of such models is to maximize a linear function of the constituent matches (e.g., linear social welfare maximization) subject to some constraints. Recent work has studied a new goal of balancing whole-match diversity and economic efficiency, where the objective is instead a monotone submodular function over the matching. Basic versions of this problem are solvable in polynomial time. In this work, we prove that the problem of simultaneously maximizing diversity along several features (e.g., country of citizenship, gender, skills) is NP-hard. To address this problem, we develop the first combinatorial algorithm that constructs provably-optimal diverse b-matchings in pseudo-polynomial time. We also provide a Mixed-Integer Quadratic formulation for the same problem and show that our method guarantees optimal solutions and takes less computation time for a reviewer assignment application.
In IDETC 2020
Deep generative models are proven to be a useful tool for automatic design synthesis and design space exploration. When applied in engineering design, existing generative models face three challenges- 1) generated designs lack diversity and do not cover all areas of the design space, 2) it is difficult to explicitly improve the overall performance or quality of generated designs, and 3) existing models generate do not generate novel designs, outside the domain of the training data. In this paper, we simultaneously address these challenges by proposing a new Determinantal Point Processes based loss function for probabilistic modeling of diversity and quality. With this new loss function, we develop a variant of the Generative Adversarial Network, named “Performance Augmented Diverse Generative Adversarial Network” or PaDGAN, which can generate novel high-quality designs with good coverage of the design space. Using three synthetic examples and one real-world airfoil design example, we demonstrate that PaDGAN can generate diverse and high-quality designs. In comparison to a vanilla Generative Adversarial Network, on average, it generates samples with 28% higher mean quality score with larger diversity and without the mode collapse issue. Unlike typical generative models that usually generate new designs by interpolating within the boundary of training data, we show that PaDGAN expands the design space boundary outside the training data towards high-quality regions. The proposed method is broadly applicable to many tasks including design space exploration, design optimization, and creative solution recommendation.
In IDETC 2020
Statistical network models allow us to study the co-evolution between the products and the social aspects of a market system, by modeling these components and their interactions as graphs. In this paper, we study competition between different car models using network theory, with a focus on how product attributes (like fuel economy and price) affect which cars are considered together and which cars are finally bought by customers. Unlike past work, where most systems have been studied with the assumption that relationships between competitors are binary (i.e., whether a relationship exists or not), we allow relationships to take strengths (i.e., how strong a relationship is). Specifically, we use valued Exponential Random Graph Models and show that our approach provides a significant improvement over the baselines in predicting product co-considerations as well as in the validation of market share. This is also the first attempt to study aggregated purchase preference and car competition using valued directed networks.
In IDETC 2020 (Awarded "Papers of Distinction")
Data-driven design of mechanical metamaterials is an increasingly popular method to combat costly physical simulations and immense, often intractable, geometrical design spaces. Using a precomputed dataset of unit cells, a multiscale structure can be quickly filled via combinatorial search algorithms, and machine learning models can be trained to accelerate the process. However, the dependence on data induces a unique challenge- An imbalanced dataset containing more of certain shapes or physical properties than others can be detrimental to the efficacy of the approaches and any models built on those sets. In answer, we posit that a smaller yet diverse set of unit cells leads to scalable search and unbiased learning. To select such subsets, we propose METASET, a methodology that 1) uses similarity metrics and positive semi-definite kernels to jointly measure the closeness of unit cells in both shape and property space, and 2) incorporates Determinantal Point Processes for efficient subset selection. Moreover, METASET allows the trade-off between shape and property diversity so that subsets can be tuned for various applications. Through the design of 2D metamaterials with target displacement profiles, we demonstrate that smaller, diverse subsets can indeed improve the search process as well as structural performance. We also apply METASET to eliminate inherent overlaps in a dataset of 3D unit cells created with symmetry rules, distilling it down to the most unique families. Our diverse subsets are provided publicly for use by any designer.
In IDETC 2020
Design researchers have long sought to understand the mechanisms that support creative idea development. However, one of the key challenges faced by the design community is how to effectively measure the nebulous construct of creativity. The social science and engineering communities have adopted two vastly different approaches to solving this problem, both of which have been deployed throughout engineering design research. The goal of this paper was to compare and contrast these two approaches using design ratings of nearly 1000 engineering design ideas paired with a qualitative study with expert raters. The results of this study identify that while these two methods provide similar ratings of idea quality, there was a statistically significant negative relationship between these methods for ratings of idea novelty. Qualitative analysis of recordings from expert raters’ think aloud concept mapping points to potential sources of disagreement. In addition, the results show that while quasi-expert and expert raters provided similar ratings of design novelty, there was not significant agreement between these groups for ratings of design quality. The results of this study provide guidance for the deployment of idea ratings in engineering design research and evidence for the development and potential modification of engineering design creativity metrics.
In C&C 2019
Exposing people to concepts created by others can inspire novel combinations of concepts, or conversely, lead people to simply emulate others. But how does the type of exposure affect creative outcomes in online collaboration where dyads interact for short tasks? In this paper, we study the creative outcomes of dyads working together online on a slogan writing task under different types of interactions- providing both the partner's idea and their explanation for that idea, enabling synchronous chat, and only exposing a person to their partner's idea without any explanation. We measure the creative outcome and define text-similarity-based metrics (e.g., mimicry, convergence, and fixation) to disentangle the interactions. The results show that having partners explain their ideas leads to largest improvement in creative outcome. In contrast, participants who chatted were more likely to reach convergence on their final slogans. Our work sheds lights on how different online interactions may create trade-offs in creative collaborations.
In IDETC 2019
In this paper, we propose a new design variety metric based on the Herfindahl index. We also propose a practical procedure for comparing variety metrics via the construction of ground truth datasets from pairwise comparisons by experts. Using two new datasets, we show that this new variety measure aligns with human ratings more than some existing and commonly used tree-based metrics. This metric also has three main advantages over existing metrics- a) It is a super-modular function, which enables us to optimize design variety using a polynomial time greedy algorithm. b) The parametric nature of this metric allows us to fit the metric to better represent variety for new domains. c) It has higher sensitivity in distinguishing between variety of sets of randomly selected designs than existing methods. Overall, our results shed light on some qualities that good design variety metrics should possess and the non-trivial challenges associated with collecting the data needed to measure those qualities.
In IDETC 2018
Assessing similarity between design ideas is an inherent part of many design evaluations to measure novelty. In such evaluation tasks, humans excel at making mental connections among diverse knowledge sets and scoring ideas on their uniqueness. However, their decisions on novelty are often subjective and difficult to explain. In this paper, we demonstrate a way to uncover human judgment of design idea similarity using two dimensional idea maps. We derive these maps by asking humans for simple similarity comparisons of the form “Is idea A more similar to idea B or to idea C?” We show that these maps give insight into the relationships between ideas and help understand the domain. We also propose that the novelty of ideas can be estimated by measuring how far items are on these maps. We demonstrate our methodology through the experimental evaluations on two datasets of colored polygons (known answer) and milk frothers (unknown answer) sketches. We show that these maps shed light on factors considered by raters in judging idea similarity. We also show how maps change when less data is available or false/noisy ratings are provided. This method provides a new direction of research into deriving ground truth novelty metrics by combining human judgments and computational methods.
In IJCAI 2017
Bipartite matching, where agents on one side of a market are matched to agents or items on the other, is a classical problem in computer science and economics, with widespread application in healthcare, education, advertising, and general resource allocation. A practitioner's goal is typically to maximize a matching market's economic efficiency, possibly subject to some fairness requirements that promote equal access to resources. A natural balancing act exists between fairness and efficiency in matching markets, and has been the subject of much research. In this paper, we study a complementary goal-- balancing diversity and efficiency--in a generalization of bipartite matching where agents on one side of the market can be matched to sets of agents on the other. Adapting a classical definition of the diversity of a set, we propose a quadratic programming-based approach to solving a super-modular minimization problem that balances diversity and total weight of the solution. We also provide a scalable greedy algorithm with theoretical performance bounds. We then define the price of diversity , a measure of the efficiency loss due to enforcing diversity, and give a worst-case theoretical bound. Finally, we demonstrate the efficacy of our methods on three real-world datasets, and show that the price of diversity is not bad in practice. Our code is publicly accessible for further research.
In CSCW 2017
This paper describes how to find or filter high-quality ideas submitted by members collaborating together in online communities. Typical means of organizing community submissions, such as aggregating community or crowd votes, suffer from the cold-start problem, the rich-get-richer problem, and the sparsity problem. To circumvent those, our approach learns a ranking model that combines 1) community feedback, 2) idea uniqueness, and 3) text features?e.g., readability, coherence, semantics, etc. This model can then rank order submissions by expected quality, supporting community members in finding content that can inspire them and improve collaboration among members. As illustrative example, we demonstrate the model on OpenIDEO--a collaborative community where high-quality submissions are rewarded by winning design challenges. We find that the proposed ranking model finds winning ideas more effectively than existing ranking techniques (comment sorting), as measured using both Discounted Cumulative Gain and human perceptions of idea quality. We also identify the elements of winning ideas that were highly predictive of subsequent success- 1) engagement with community feedback, 2) submission length, and 3) a submission's uniqueness. Ultimately, our approach enables community members and managers to more effectively manage creative stimuli created by large collaborative communities.
In IDETC 2016
This paper describes how to select diverse, high quality, representative ideas when the number of ideas grow beyond what a person can easily organize. When designers have a large number of ideas, it becomes prohibitively difficult for them to explore the scope of those ideas and find inspiration. We propose a computational method to recommend a diverse set of representative and high quality design ideas and demonstrate the results for design challenges on OpenIDEO — a web-based online design community. Diversity of these ideas is defined using topic modeling to identify latent concepts within the text while the quality is measured from user feedback. Multi-objective optimization then trades off quality and diversity of ideas. The results show that our approach attains a diverse set of high quality ideas and that the proposed method is applicable to multiple domains.
In CORE 2016
Irregular track geometry can incite undesirable vehicle dynamic response modes that increase track loading, reduce component life, and increase the risk of vehicle derailment. Geometric irregularities in track can typically be identified by monitoring wagon-track dynamic activity. Instrumented ore car (IOC) continuous monitoring systems measure a range of response metrics including spring nest deflection, which under nominal service loads and speeds, are a key indicator of geometry induced wagon-track dynamic activity. This study demonstrates the benefits of predictive maintenance approaches facilitated by the trending of continuously measured performance data, as developed for Rio Tinto’s heavy haul iron ore railway network in Australia’s Pilbara region. Predictive maintenance approaches facilitate the improvement of maintenance planning operations resulting in better track surface and line condition, reduced risk to infrastructure and rolling-stock as well a reduction in the need for reactive temporary speed restrictions (TSRs) and unscheduled maintenance activities.
In IHHA 2015
Settlement of railway track caused by the cyclic loading and vibration of network traffic, leads to degradation of geometry which therefore needs to be systematically maintained. Tamping is an effective maintenance procedure which repacks ballast particles in order to restore the correct geometrical position of track. The goal of this study has been the development of a tool to evaluate the effectiveness of track tamping. Continuously measured performance data from instrumented ore cars (IOCs) is used for the analysis. The wagon-track dynamic interaction is studied by investigating the dynamic behaviour of the IOC's suspension system. The wagon suspension response data is then utilized to identify locations where tamping has been effective or ineffective. A maintenance planning system is used to conduct predictive modelling and forecast wagon dynamic responses to identify priority tamping locations. Using linear regression, the rate of track degradation over time and locations where tamping is required can be identified. The results of this work facilitate the development and improvement of maintenance planning operations. Particular tamping strategies or equipment that has had an adverse impact on track can also be identified. It therefore becomes feasible to develop a preventative tamping program that reduces surface and lining requirements and consequently the need for the introduction of temporary speed restrictions.
In BIC-TA 2012
Over the past two decades, structural optimization has been performed extensively by researchers across the world. Most recent investigations have focused on increasing the efficiency and robustness of gradient based optimization techniques and extending them to multidisciplinary objective functions. The existing global optimization techniques suffer with requirement of enormous computational effort due to large number of variables used in grid discretization of problem domain. The paper proposes a novel methodology named as Constructive Geometry Topology Optimization Method (CG-TOM) for topology optimization problems. It utilizes a set of nodes and overlapping primitives to obtain the geometry. A novel graph based repair operator is used to ensure consistent design and real parameter genetic algorithm is used for optimization. Results for standard benchmark problems for compliance minimization have been found to give better results than existing methods in literature. The method is generic and can be extended to any two or three dimensional topology optimization problem using different primitives.
In SocProS 2011
Suspension systems with terrain preview have wide applicability for off-road and military vehicles moving on rough surfaces. Preview control of active suspension systems gives it great flexibility in controlling system behavior. The focus of the study is evolutionary multi-objective optimization of preview controlled active suspension system with several objectives for controller design. The suspension model with base system data and passive response has been explained along with the structure of the preview controller. Multiple conflicting objectives to achieve ride comfort, good handling and road grip are identified and a modified NSGA-II algorithm is used to obtain the trade-off solutions. Thereafter a decision making approach is suggested to select optimum gains for the controller. The obtained optimal solutions are compared with the reference vehicle and other multi-objective optimization strategies. The proposed strategy improves on the reference vehicle objectives along with showing the benefits of multi-criteria approach.
In SEMCCO 2011
Selection of players for a high performance cricket team within a finite budget is a complex task which can be viewed as a constrained multi-objective optimization problem. In cricket team formation, batting strength and bowling strength of a team are the major factors affecting its performance and an optimum trade-off needs to be reached in formation of a good team. We propose a multi-objective approach using NSGA-II algorithm to optimize overall batting and bowling strength of a team and find team members in it. Using the information from trade-off front, a decision making approach is also proposed for final selection of team. Case study using a set of players auctioned in Indian Premier League, 4th edition has been taken and player’s current T-20 statistical data is used as performance parameter. This technique can be used by franchise owners and league managers to form a good team within budget constraints given by the organizers. The methodology is generic and can be easily extended to other sports like soccer, baseball etc.
In ROBIO 2011
Off-line point to point navigation to calculate feasible paths and optimize them for different objectives is computationally difficult. Path planning problem is truly a multi-objective problem, as reaching the goal point in short time is desirable for an autonomous vehicle while ability to generate safe paths in crucial for vehicle viability. Path representation methodologies using piecewise polynomial and B-splines have been used to ensure smooth paths. Multi-objective path planning studies using NSGA-II algorithm to optimize path length and safety measures computed using one of the three metrics (i) an artificial potential field, (ii) extent of obstacle hindrance and (iii) a measure of visibility are implemented. Multiple tradeoff solutions are obtained on complex scenarios. The results indicate the usefulness of treating path planning as a multi-objective problem.
In AAAI AI4Design Workshop, 2024
Generative Artificial Intelligence (AI) has shown tremendous prospects in all aspects of technology, including design. However, due to its heavy demand on resources, it is usually trained on large computing infrastructure and often made available as a cloud-based service. In this position paper, we consider the potential, challenges, and promising approaches for generative AI for design on the edge, i.e., in resource-constrained settings where memory, compute, energy (battery) and network connectivity may be limited. Adapting generative AI for such settings involves overcoming significant hurdles, primarily on how to streamline complex models to function efficiently in low-resource environments. This necessitates innovative approaches in model compression, efficient algorithmic design, and perhaps even leveraging edge computing. The objective is to harness the power of generative AI in creating bespoke solutions for design problems, such as medical interventions, farm equipment maintenance, and educational material design, tailored to the unique constraints and needs of remote areas. These efforts could not only democratize access to advanced technology but also foster sustainable development, ensuring that the benefits of AI-driven design are universally accessible and environmentally considerate.
In Neurips Workshop on Diffusion Models, 2023
Generative models have demonstrated impressive results in vision, language, and speech. However, even with massive datasets, they struggle with precision, generating physically invalid or factually incorrect data. To improve precision while preserving diversity and fidelity, we propose a novel training mechanism that leverages datasets of constraint-violating data points, which we consider invalid. Our approach minimizes the divergence between the generative distribution and the valid prior while maximizing the divergence with the invalid distribution. We demonstrate how generative models like Diffusion Models and GANs that we augment to train with invalid data improve their standard counterparts which solely train on valid data points. We also explore connections between density ratio and guidance in diffusion models. Our proposed mechanism offers a promising solution for improving precision in generative models while preserving diversity and fidelity, particularly in domains where constraint satisfaction is critical and data is limited, such as engineering design, robotics, and medicine.
In Neurips Workshop on Diffusion Models, 2023
Generative models have had a profound impact on vision and language, paving the way for a new era of multimodal generative applications. Yet, challenges persist in constrained environments, such as engineering and science, where data is limited and precision is crucial. We introduce Diffusion Optimization Models (DOM) and Trajectory Alignment (TA), a regularization technique aligning diffusion model sampling with physics-based optimization. By significantly improving performance and inference efficiency, DOM enables us to generate high-quality designs in just a few steps and guide them toward regions of high performance and manufacturability, paving the way for the widespread application of generative models in large-scale data-driven design.
In ICML Workshop on Computational Design, 2022
Deep Generative Machine Learning Models (DGMs) have been growing in popularity across the design community thanks to their ability to learn and mimic complex data distributions. DGMs are conventionally trained to minimize statistical divergence between the distribution over generated data and distribution over the dataset on which they are trained. While sufficient for the task of generating “realistic” fake data, this objective is typically insufficient for design synthesis tasks. Instead, design problems typically call for adherence to design requirements, such as performance targets and constraints. Advancing DGMs in engineering design requires new training objectives which promote engineering design objectives. In this paper, we present the first Deep Generative Model that simultaneously optimizes for performance, feasibility, diversity, and target achievement. We benchmark performance of the proposed method against several Deep Generative Models over eight evaluation metrics that focus on feasibility, diversity, and satisfaction of design performance targets. Methods are tested on a challenging multi-objective bicycle frame design problem with skewed, multimodal data of different datatypes. The proposed framework was found to outperform all Deep Generative Models in six of eight metrics.
In ICML NDSML Workshop 2020
Bipartite b-matching, where agents on one side of a market are matched to one or more agents or items on the other, is widely used in many application areas such as healthcare, advertising, and general resource allocation. Traditionally, the primary goal of such models is to maximize a linear function of the constituent matches subject to some constraints. Recent work has studied a new goal of balancing whole-match diversity and economic efficiency, where the objective was to maximize coverage over some groups. Basic versions of this problem are solvable in polynomial time. In this work, we provide a generalized version of the problem, where the goal is to simultaneously maximize diversity along several features (e.g., country of citizenship, gender, skills) and show that it is NP-hard. We develop the first combinatorial algorithm that constructs provably-optimal diverse b-matchings in pseudo-polynomial time. We show that our method guarantees optimal solutions and is faster than state-of-the-art methods for a reviewer assignment application. We conclude with a discussion on key challenges in diverse matching domain.
In ICML NDSML Workshop 2020
Deep generative models have proven useful for automatic design synthesis and design space exploration. However, they face three challenges when applied to engineering design- 1) generated designs lack diversity, 2) it is difficult to explicitly improve all the performance measures of generated designs, and 3) existing models generally do not generate high-performance novel designs, outside the domain of the training data. To address these challenges, we propose MO-PaDGAN, which contains a new Determinantal Point Processes based loss function for probabilistic modeling of diversity and performances. Through a real-world airfoil design example, we demonstrate that MO-PaDGAN expands the existing boundary of the design space towards high-performance regions and generates new designs with high diversity and performances exceeding training data.
Ph.D. thesis
The primary objective of this dissertation is to investigate research methods to answer the question- ``How (and why) does one measure, learn and optimize novelty and diversity of a set of items?" The computational models we develop to answer this question also provide foundational mathematical techniques to throw light on the following three questions- 1. How does one reliably measure the creativity of ideas? 2. How does one form teams to evaluate design ideas? 3. How does one filter good ideas out of hundreds of submissions? Solutions to these questions are key to enable the effective processing of a large collection of design ideas generated in a design contest. In the first part of the dissertation, we discuss key qualities needed in design metrics and propose new diversity and novelty metrics for judging design products. We show that the proposed metrics have higher accuracy and sensitivity compared to existing alternatives in literature. To measure the novelty of a design item, we propose learning from human subjective responses to derive low dimensional triplet embeddings. To measure diversity, we propose an entropy-based diversity metric, which is more accurate and sensitive than benchmarks. In the second part of the dissertation, we introduce the bipartite b-matching problem and argue the need for incorporating diversity in the objective function for matching problems. We propose new submodular and supermodular objective functions to measure diversity and develop multiple matching algorithms for diverse team formation in offline and online cases. Finally, in the third part, we demonstrate filtering and ranking of ideas using diversity metrics based on Determinantal Point Processes as well as submodular functions. In real-world crowd experiments, we demonstrate that such ranking enables increased efficiency in filtering high-quality ideas compared to traditionally used methods.
M. Tech. thesis
Under Review
Predictive modeling in engineering applications has long been dominated by bespoke models and small, siloed tabular datasets, limiting the applicability of large-scale learning approaches. Despite recent progress in tabular foundation models, the resulting synthetic training distributions used for pre-training may not reflect the statistical structure of engineering data, limiting transfer to engineering regression. We introduce TREDBench, a curated collection of 83 real-world tabular regression datasets with expert engineering/non-engineering labels, and use TabPFN 2.5's dataset-level embedding to study domain structure in a common representation space. We find that engineering datasets are partially distinguishable from non-engineering datasets, while standard procedurally generated datasets are highly distinguishable from engineering datasets, revealing a substantial synthetic-real domain gap. To bridge this gap without training on real engineering samples, we propose an embedding-guided synthetic data curation method: we generate and identify "engineering-like" synthetic datasets, and perform continued pre-training of TabPFN 2.5 using only the selected synthetic tasks. Across 35 engineering regression datasets, this synthetic-only adaptation improves predictive accuracy and data efficiency, outperforming TabPFN 2.5 on 29/35 datasets and AutoGluon on 27/35, with mean multiplicative data-efficiency gains of 1.75x and 4.44x, respectively. More broadly, our results indicate that principled synthetic data curation can convert procedural generators into domain-relevant "data engines," enabling foundation models to improve in data-sparse scientific and industrial domains where real data collection is the primary bottleneck.
Under Review
Despite topology optimization producing high-performance structures, late-stage localized revisions remain brittle: direct density-space edits (e.g., warping pixels, inserting holes, swapping infill) can sever load paths and sharply degrade compliance, while re-running optimization is slow and may drift toward a qualitatively different design. We present TopoEdit, a fast post-optimization editor that demonstrates how structured latent embeddings from a pre-trained topology foundation model (OAT) can be repurposed as an interface for physics-aware engineering edits. Given an optimized topology, TopoEdit encodes it into OAT's spatial latent, applies partial noising to preserve instance identity while increasing editability, and injects user intent through an edit-then-denoise diffusion pipeline. We instantiate three edit operators: drag-based topology warping with boundary-condition-consistent conditioning updates, shell-infill lattice replacement using a lattice-anchored reference latent with updated volume-fraction conditioning, and late-stage no-design region enforcement via masked latent overwrite followed by diffusion-based recovery. A consistency-preserving guided DDIM procedure localizes changes while allowing global structural adaptation; multiple candidates can be sampled and selected using a compliance-aware criterion, with optional short SIMP refinement for warps. Across diverse case studies and large edit sweeps, TopoEdit produces intention-aligned modifications that better preserve mechanical performance and avoid catastrophic failure modes compared to direct density-space edits, while generating edited candidates in sub-second diffusion time per sample.
Under Review
Multi-fidelity (MF) regression often operates in regimes of extreme data imbalance, where the commonly-used Gaussian-process (GP) surrogates struggle with cubic scaling costs and overfit to sparse high-fidelity observations, limiting efficiency and generalization in real-world applications. We introduce FIRE, a training-free MF framework that couples tabular foundation models (TFMs) to perform zero-shot in-context Bayesian inference via a high-fidelity correction model conditioned on the low-fidelity model's posterior predictive distributions. This cross-fidelity information transfer via distributional summaries captures heteroscedastic errors, enabling robust residual learning without model retraining. Across 31 benchmark problems spanning synthetic and real-world tasks (e.g., DrivAerNet, LCBench), FIRE delivers a stronger performance-time trade-off than seven state-of-the-art GP-based or deep learning MF regression methods, ranking highest in accuracy and uncertainty quantification with runtime advantages. Limitations include context window constraints and dependence on the quality of the pre-trained TFM's.
Under Review
Upscaling is central to offshore wind's cost-reduction strategy, with increasingly large rotors and nacelles requiring taller and stronger towers. In Floating Offshore Wind Turbines (FOWTs), this trend amplifies fatigue loads due to coupled wind-wave dynamics and platform motion. Conventional fatigue evaluation requires millions of high-fidelity simulations, creating prohibitive computational costs and slowing design innovation. This paper presents FLOAT (Fatigue-aware Lightweight Optimization and Analysis for Towers), a framework that accelerates fatigue-aware tower design. It integrates three key contributions: a lightweight fatigue estimation method that enables efficient optimization, a Monte Carlo-based probabilistic wind-wave sampling approach that reduces required simulations, and enhanced high-fidelity modeling through pitch/heave-platform calibration and High-Performance Computing (HPC) execution. The framework is applied to the IEA 22 MW FOWT tower, delivering, to the authors' knowledge, the first fatigue-oriented redesign of this benchmark model: FLOAT 22 MW FOWT tower. Validation against 6,468 simulations demonstrates that the optimized tower extends the estimated fatigue life from ~9 months to 25 years while avoiding resonance, and that the lightweight fatigue estimator provides conservative predictions with a mean relative error of -8.6%. Achieving this lifetime requires increased tower mass, and the final design represents the lowest-mass fatigue-compliant configuration within the selected design space. All results and the reported lifetime extension are obtained within the considered fatigue scope, namely DLC 1.2 under aligned wind-wave conditions for the selected site distributions. By reducing simulation requirements by orders of magnitude, FLOAT provides a computationally efficient pathway for reliable and scalable tower design in next-generation FOWTs, bridging industrial needs and academic research while generating high-fidelity datasets that can support data-driven design methodologies.
Under Review
Despite progress in machine learning based aerodynamic surrogates, the scarcity of large, field-resolved datasets limits progress on accurate pointwise prediction and reproducible inverse design for aircraft. We introduce BlendedNet++, a large-scale aerodynamic dataset and benchmark focused on blended wing body (BWB) aircraft. The dataset contains over 12,000 unique geometries, each simulated at a single flight condition, yielding 12,490 aerodynamic results for steady RANS CFD. For every case, we provide (i) integrated force/moment coefficients CL, CD, CM and (ii) dense surface fields of pressure and skin friction coefficients - Cp and (Cfx, Cfy, Cfz). Using this dataset, we standardize a forward-surrogate benchmark to predict pointwise fields across six model families: GraphSAGE, GraphUNet, PointNet, a coordinate Transformer (Transolver-style), a FiLMNet (coordinate MLP with feature-wise modulation), and a Graph Neural Operator Transformer (GNOT). Finally, we present an inverse design task of achieving a specified lift-to-drag ratio under fixed flight conditions, implemented via a conditional diffusion model. To assess performance, we benchmark this approach against gradient-based optimization on the same surrogate and a diffusion-optimization hybrid that first samples with the conditional diffusion model and then further optimizes the designs. BlendedNet++ provides a unified forward and inverse protocol with multi-model baselines, enabling fair, reproducible comparison across architectures and optimization paradigms. We expect BlendedNet++ to catalyze reproducible research in field-level aerodynamics and inverse design; resources (dataset, splits, baselines, and scripts) will be released upon acceptance.
Under Review
Benchmarking has been the cornerstone of progress in computer vision, natural language processing, and the broader deep learning domain, driving algorithmic innovation through standardized datasets and reproducible evaluation protocols. The growing availability of large-scale Computational Fluid Dynamics (CFD) datasets has opened new opportunities for applying machine learning to aerodynamic and engineering design. Yet, despite this progress, there exists no standardized benchmark for large-scale numerical simulations in engineering design. In this work, we introduce CarBench, the first comprehensive benchmark dedicated to large-scale 3D car aerodynamics, performing a large-scale evaluation of state-of-the-art models on DrivAerNet++, the largest public dataset for automotive aerodynamics, containing over 8,000 high-fidelity car simulations. We assess eleven architectures spanning neural operator methods (e.g., Fourier Neural Operator), geometric deep learning (PointNet, RegDGCNN, PointMAE, PointTransformer), transformer-based neural solvers (Transolver, Transolver++, AB-UPT), and implicit field networks (TripNet). Beyond standard interpolation tasks, we perform cross-category experiments in which transformer-based solvers trained on a single car archetype are evaluated on unseen categories. Our analysis covers predictive accuracy, physical consistency, computational efficiency, and statistical uncertainty. To accelerate progress in data-driven engineering, we open-source the benchmark framework, including training pipelines, uncertainty estimation routines based on bootstrap resampling, and pretrained model weights, establishing the first reproducible foundation for large-scale learning from high-fidelity CFD simulations.
Under Review
Projected Gradient Descent (PGD) methods offer a simple and scalable approach to topology optimization (TO), yet they often struggle with nonlinear and multi-constraint problems due to the complexity of active-set detection. This paper introduces PGD-TO, a framework that reformulates the projection step into a regularized convex quadratic problem, eliminating the need for active-set search and ensuring well-posedness even when constraints are infeasible. The framework employs a semismooth Newton solver for general multi-constraint cases and a binary search projection for single or independent constraints, achieving fast and reliable convergence. It further integrates spectral step-size adaptation and nonlinear conjugate-gradient directions for improved stability and efficiency. We evaluate PGD-TO on four benchmark families representing the breadth of TO problems: (i) minimum compliance with a linear volume constraint, (ii) minimum volume under a nonlinear compliance constraint, (iii) multi-material minimum compliance with four independent volume constraints, and (iv) minimum compliance with coupled volume and center-of-mass constraints. Across these single- and multi-constraint, linear and nonlinear cases, PGD-TO achieves convergence and final compliance comparable to the Method of Moving Asymptotes (MMA) and Optimality Criteria (OC), while reducing per-iteration computation time by 10–43x on general problems and 115–312x when constraints are independent. Overall, PGD-TO establishes a fast, robust, and scalable alternative to MMA, advancing topology optimization toward practical large-scale, multi-constraint, and nonlinear design problems. Public code available at: https://github.com/ahnobari/pyFANTOM.
arXiv preprint arXiv:2510.22491
Generating high-fidelity 3D geometries that satisfy specific parameter constraints has broad applications in design and engineering. However, current methods typically rely on large training datasets and struggle with controllability and generalization beyond the training distributions. To overcome these limitations, we introduce LAMP (Linear Affine Mixing of Parametric shapes), a data-efficient framework for controllable and interpretable 3D generation. LAMP first aligns signed distance function (SDF) decoders by overfitting each exemplar from a shared initialization, then synthesizes new geometries by solving a parameter-constrained mixing problem in the aligned weight space. To ensure robustness, we further propose a safety metric that detects geometry validity via linearity mismatch. We evaluate LAMP on two 3D parametric benchmarks: DrivAerNet++ and BlendedNet. We found that LAMP enables (i) controlled interpolation within bounds with as few as 100 samples, (ii) safe extrapolation by up to 100% parameter difference beyond training ranges, and (iii) physics performance-guided optimization under fixed parameters. LAMP significantly outperforms conditional autoencoder and Deep Network Interpolation (DNI) baselines in both extrapolation and data efficiency. Our results demonstrate that LAMP advances controllable, data-efficient, and safe 3D generation for design exploration, dataset generation, and performance-driven optimization.
Under Review
Computational Fluid Dynamics (CFD) simulations are essential in product design, providing insights into fluid behavior around complex geometries in aerospace and automotive applications. However, high-fidelity CFD simulations are computationally expensive, making rapid design iterations challenging. To address this, we propose TripNet, Triplane CFD Network, a machine learning-based framework leveraging triplane representations to predict the outcomes of large-scale, high-fidelity CFD simulations with significantly reduced computation cost. Our method encodes 3D geometry into compact yet information-rich triplane features, maintaining full geometry fidelity and enabling accurate aerodynamic predictions. Unlike graph- and point cloud-based models, which are inherently discrete and provide solutions only at the mesh nodes, TripNet allows the solution to be queried at any point in the 3D space. Validated on high-fidelity DrivAerNet and DrivAerNet++ car aerodynamics datasets, TripNet achieves state-of-the-art performance in drag coefficient prediction, surface field estimation, and full 3D flow field simulations of industry-standard car designs. By utilizing a shared triplane backbone across multiple tasks, our approach offers a scalable, accurate, and efficient alternative to traditional CFD solvers.