MMML Vehicle Rating Prediction
Multi-modal Machine Learning for Vehicle Rating Predictions using Image, Text, and Parametric Data
1MIT
Multi-modal Machine Learning for Vehicle Rating Predictions using Image, Text, and Parametric Data
1MIT
We propose a multi-modal learning model for more comprehensive and accurate vehicle rating predictions. Specifically, the model simultaneously learns features from the parametric specifications, text descriptions, and images of vehicles to predict five vehicle rating scores, including the total score, critics score, performance score, safety score, and interior score. We compare the multi-modal learning model to the corresponding unimodal models and find that the multi-modal model's explanatory power is 4% - 12% higher than that of the unimodal models. On this basis, we conduct sensitivity analyses using SHAP to interpret our model and provide design and optimization directions to designers and manufacturers. Our study underscores the importance of the data-driven multi-modal learning approach for vehicle design, evaluation, and optimization.
Accurate vehicle rating prediction can facilitate designing and configuring good vehicles. This prediction allows vehicle designers and manufacturers to optimize and improve their designs in a timely manner, enhance their product performance, and effectively attract consumers.
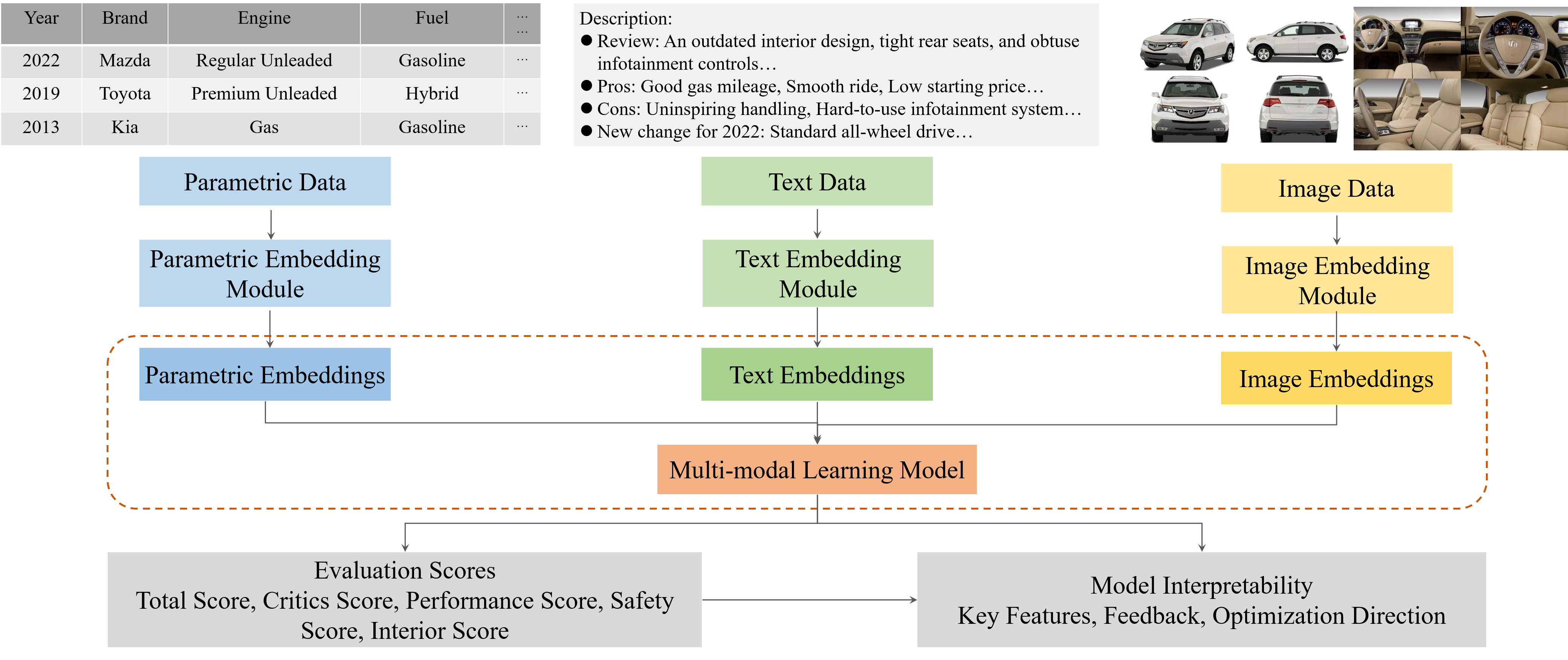
This prediction problem is viewed as a regression task. The multi-modal learning model can be divided into five module. The first module is a pre-processing module to prepare the original data (parametric vehicle specifications, images, and text descriptions). The processed data are the input to the respective unimodal models. The second, third, and fourth modules are the unimodal models capturing features from the parametric, image, or text data, respectively. After the three unimodal models are pre-trained, they can be combined to construct the multi-modal learning model. These models aim to predict five distinct vehicle rating scores, namely the total score, critics score, performance score, safety score, and interior score. The sensitivity analyses using SHAP are capable of interpreting our models and providing more detailed design, optimization, and improvement directions to designers and companies.
The multi-modal learning model incorporates three distinct unimodal models for embedding parametric data, image data, and text data, respectively. In order to facilitate the learning of interactions between these three data modalities, we avoid direct integration of the unimodal models by concatenating their final outputs. Instead, we concatenate the final embeddings of the input parametric, text, and image data derived from their respective unimodal models. This concatenated representation serves as the final joint representation of the multi-modal input data. The ultimate output of the multi-modal learning model is computed through a dense layer employing the ReLU activation function. The figure below summarizes the architecture of the multi-modal model.
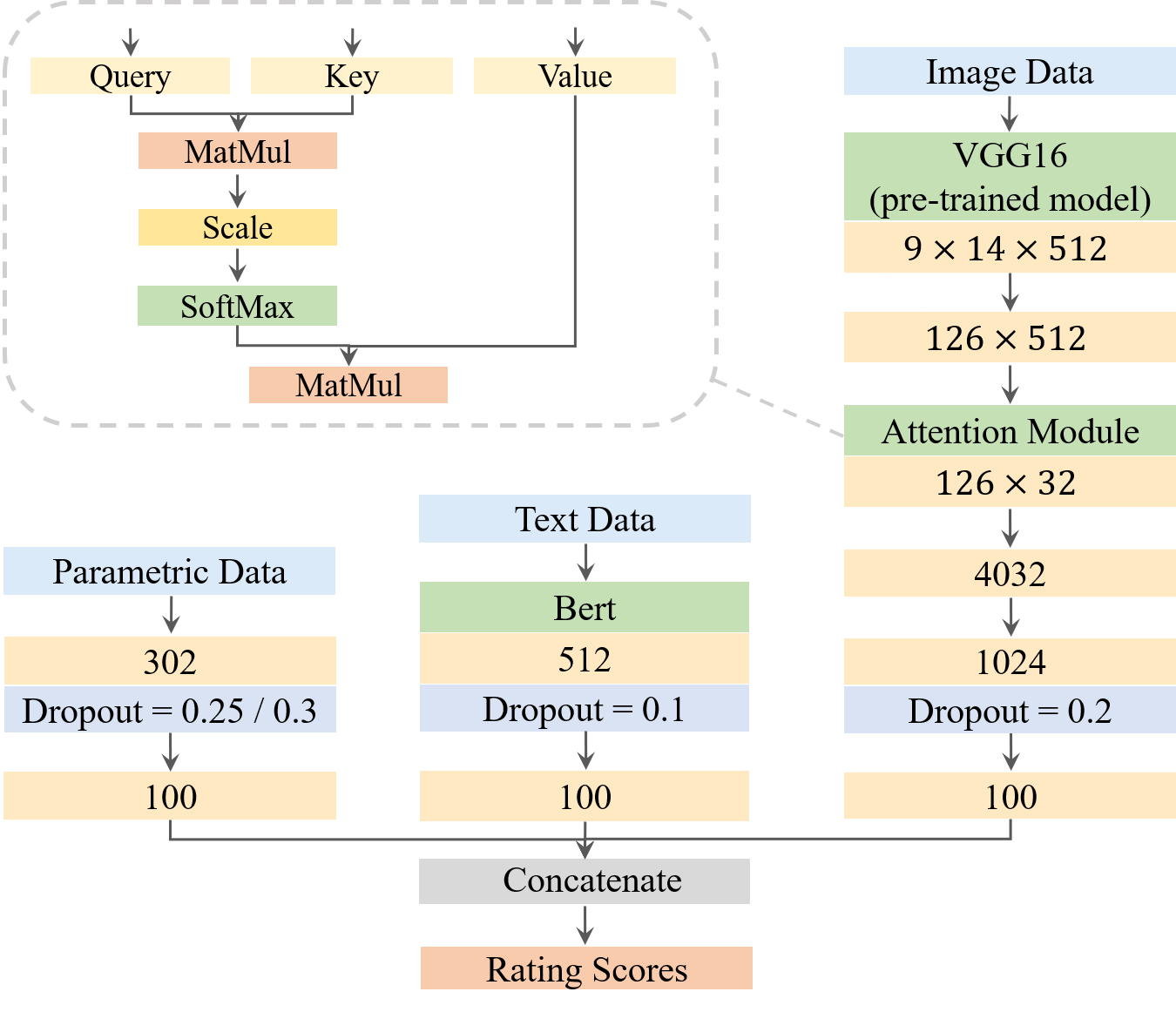
We compare the performances of the three unimodal models and the four multi-modal learning models to verify the effectiveness of the proposed multi-modal learning model. The comparison in performance among the unimodal and multi-modal learning models is shown in the following figure.
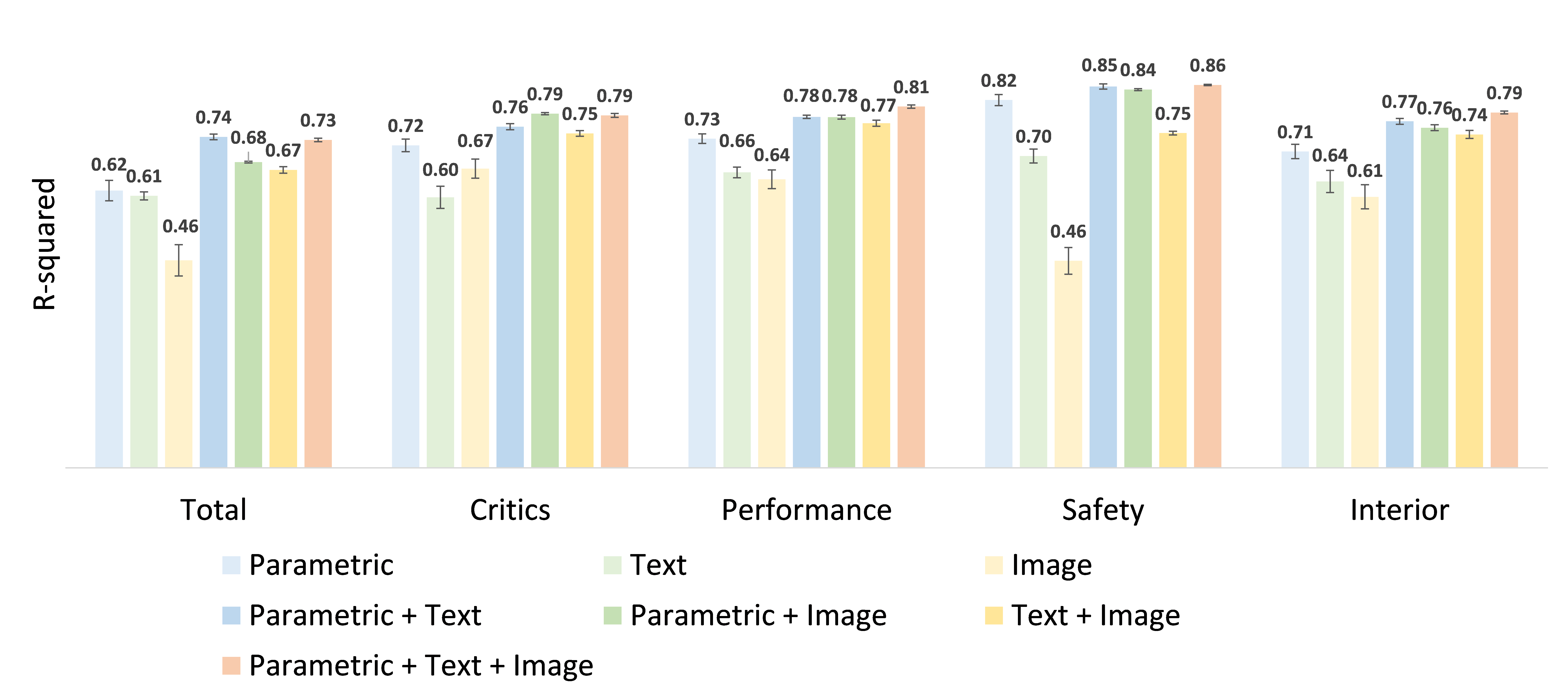
Multi-modal learning models outperform the unimodal models. For predicting all rating scores, the average R-squared values of the multi-modal learning models are significantly higher than that of the corresponding unimodal models. The results suggest that compared to the unimodal models, the joint learning of multi-modal data enables the multi-modal learning models to leverage the complementary features learned from different modalities to better predict the rating scores.
The effect of multi-modal learning varies in predicting different rating scores. Notably, the influence of multi-modal learning is most significant when predicting the total score. In fact, the top-performing multi-modal model (Par+Text-MML$) surpasses the best unimodal model (parametric) by an improvement of 0.12. On the other hand, the effect of multi-modal learning is less apparent when predicting the safety score. The leading multi-modal model (Par+Text+Img-MML) only demonstrates a modest increase of 0.02 in the R-squared value compared to the best unimodal model, which is the parametric model.
A more detailed interpretation of the outputs from the models is needed to inform designers and companies about potential directions to optimizing the inferior design or advertising the superior design of a vehicle. For this purpose, we utilize the SHAP method to interpret the outputs from the image, text, and parametric models. Through backward gradient-based sensitivity analysis, the output SHAP values indicate the influence of each element of the input data on the final prediction made by a model. A higher absolute SHAP score suggests a higher influence. Therefore, the SHAP method can help us interpret how a deep learning model makes its decision.
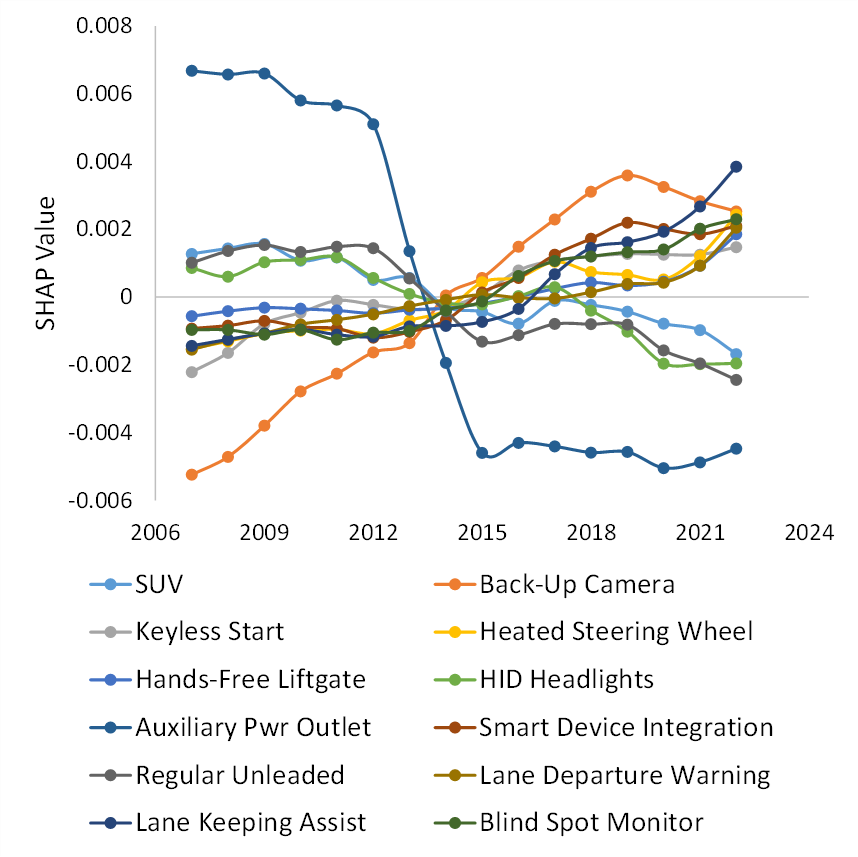
The SHAP values of 12 parametric example features for predicting the total score over time. We observe that the importance of some features such as back-up cameras has increased in the last decade.
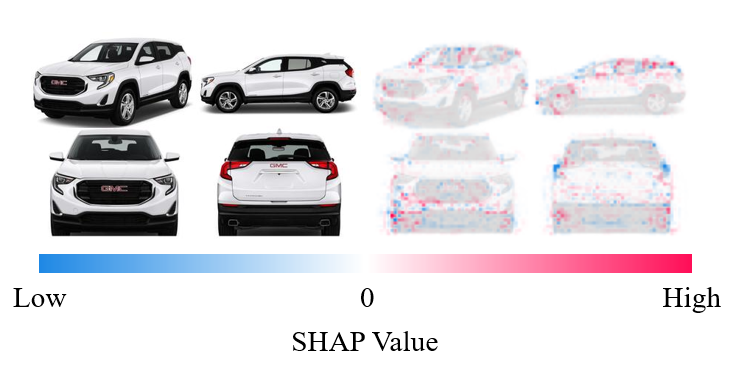
SHAP values of the exterior image regions of the 2020 GMC Terrain for total score prediction. The SHAP values on the right with the corresponding exterior image on the left.

SHAP values of the interior image regions of the 2020 Acura RLX for the interior score prediction. The SHAP values on the right with the corresponding interior image on the left. One can observe that most points are clustered near the dashboard, indicating its importance for ratings.

SHAP values of the words in the 2020 Mazda CX-9's text data for its total score prediction. The red and blue colors imply positive and negative impacts, respectively. Words such as premium cabin and thrilling handling are found to have high importance.
Su, Hanqi, Binyang Song, and Faez Ahmed. "Multi-modal Machine Learning for Vehicle Rating Predictions Using Image, Text, and Parametric Data." arXiv preprint arXiv:2305.15218 (2023).
@article{su2023multi,
title={Multi-modal Machine Learning for Vehicle Rating Predictions Using Image,
Text,
and Parametric Data},
author={Su,
Hanqi and Song,
Binyang and Ahmed,
Faez},
journal={arXiv preprint arXiv:2305.15218},
year={2023}}