
counterfactuals
Counterfactuals for Design: A Model-Agnostic Method For Design Recommendations
1MIT 2ProgressSoft
Counterfactuals for Design: A Model-Agnostic Method For Design Recommendations
1MIT 2ProgressSoft
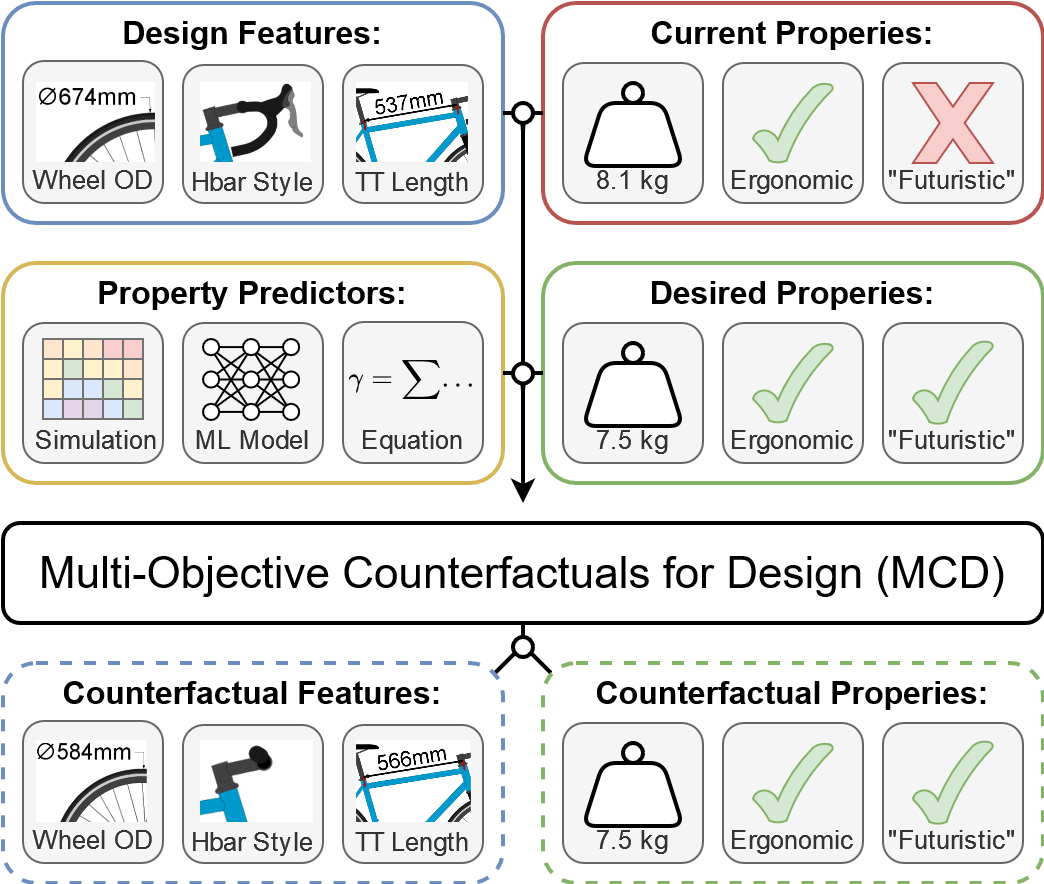
We introduce Multi-Objective Counterfactuals for Design (MCD), a novel method for counterfactual optimization in design problems. MCD provides helps users reimagine their design concepts by recommending targeted modifications. Users can ask questions like: What if my design were lighter? What if my design were more futuristic? MCD reimagines design concepts in these counterfactual scenarios.
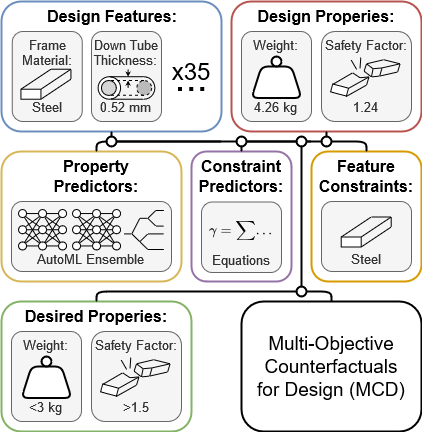
Users query MCD with an existing design concept and a set of desired counterfactual attributes. MCD iteratively queries a set of forward models (ML predictors, simulations, equations, etc.) provided by the user to identify a modification to the query that results in the desired counterfactual attributes.
MCD then recommends a diverse set of design modifications. These design modifications ideally display the counterfactual attributes while being as similar to the original design as possible.
In this case study, MCD was asked to modify an existing bike frame to make it nearly 30% lighter and 20% stronger without changing its material.
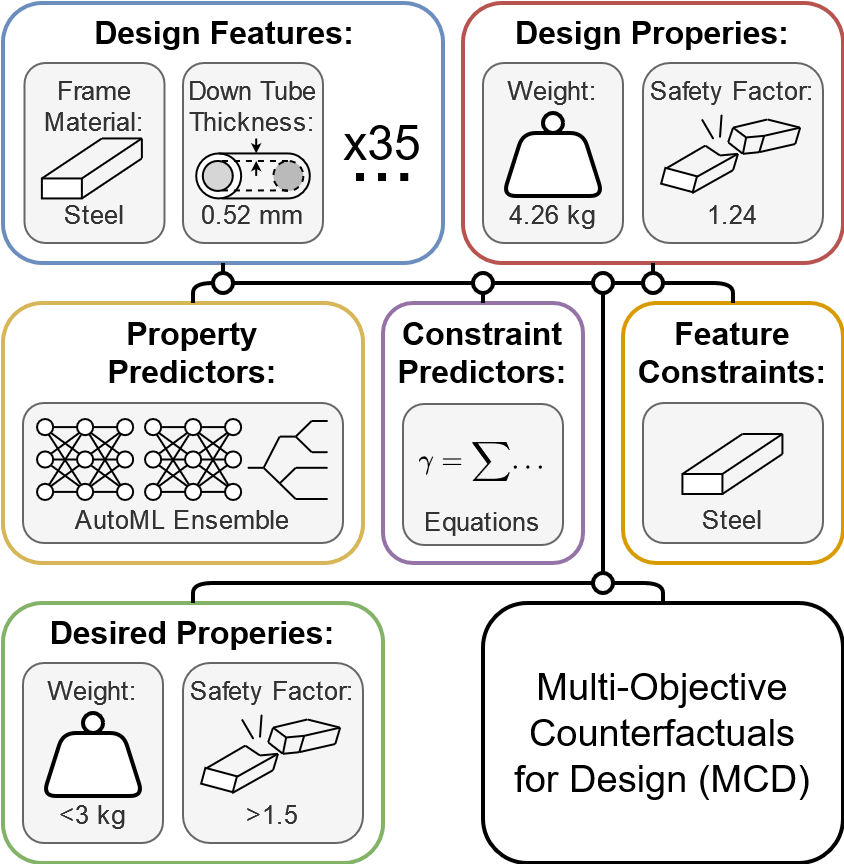
Using a predictive model trained on the FRAMED dataset, MCD was able to identify targeted modifications the the query design, which is represented across 37 continuous and categorical parameters.
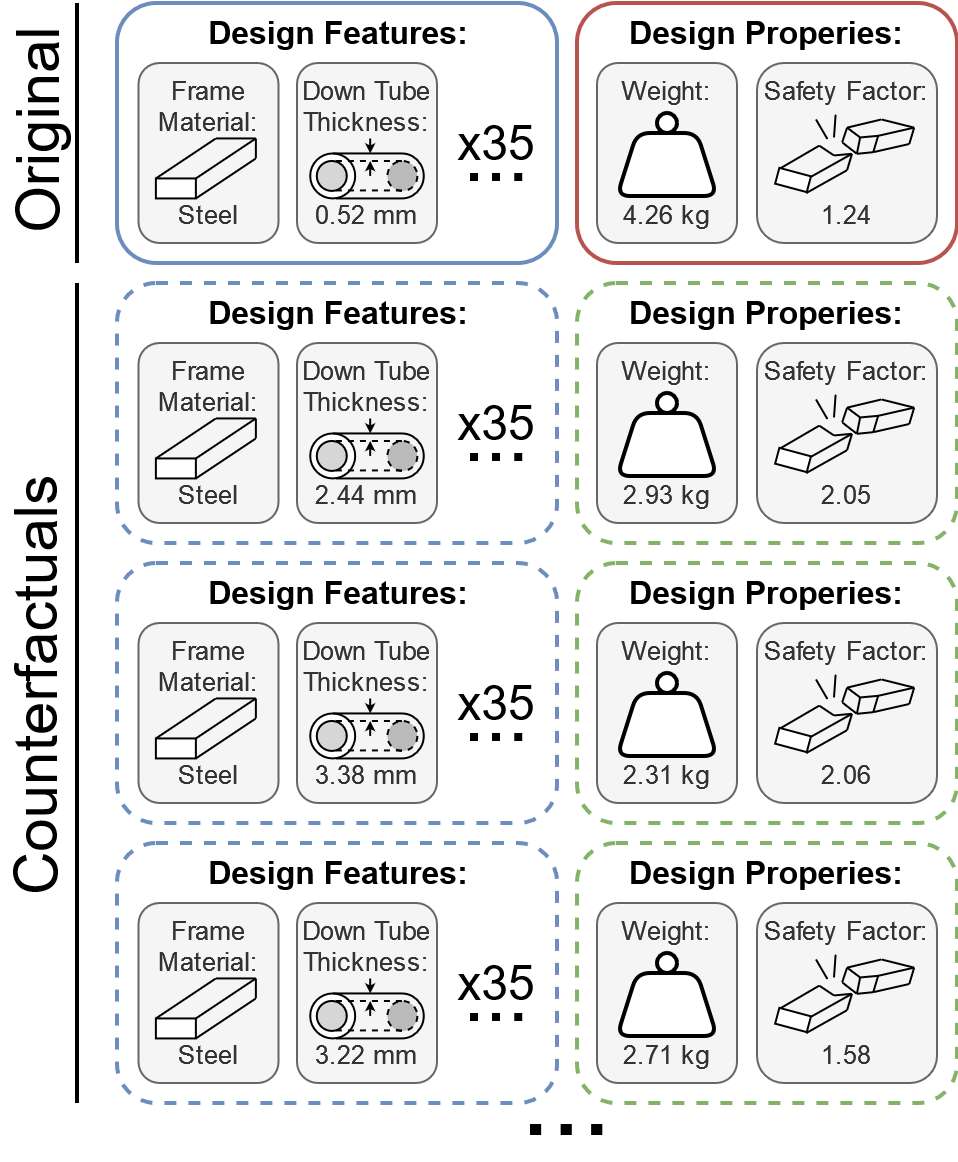
MCD identifies numerous designs that achieve the performance targets. It makes modifications to a number of parameters, but consistently increases the thickness of the down tube, a key structural shortcoming of the original design. By adding material in the down tube, MCD is able to remove weight from other components, achieving the desired weight savings.
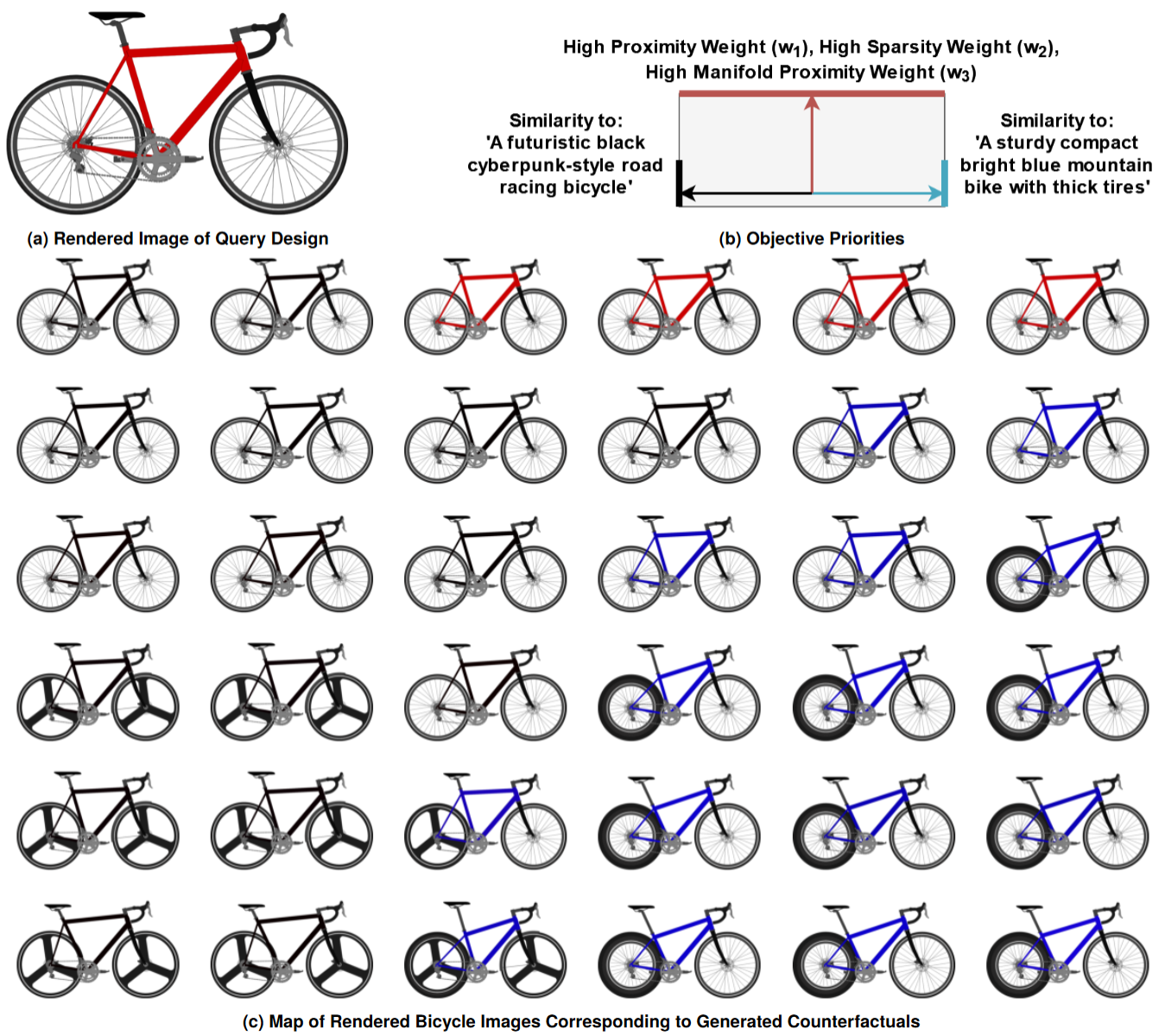
In many design settings, designers may have subjective requirements that are difficult to quantify. We demonstrate that MCD can be queried using text-based counterfactual attributes. To allow us to calculate the match between a design and a textual attribute, we first render an image of each design candidate, then calculate a text-to-image similarity score using a Contrastive Language Image Pretraining (CLIP) model.
In this image, we show a map of designs recommended by MCD when given a red road bike as an input design and two text prompts as counterfactual attributes. Similarity to the input design is prioritized at the top of the map and relaxed towards the bottom, making designs near the top closely resemble the original bike, but allowing designs towards the bottom to differ more significantly. To the left, similarity to the prompt: 'A futuristic black cyberpunk-style road racing bicycle' is prioritized. Towards the right, similarity to 'A sturdy compact bright blue mountain bike with thick tires' is prioritized.
Next, we demonstrate a more complex case where MCD is given a set of multimodal counterfactual attributes: a text prompt, an image, and weight limit, and a minimum structural safety factor.
In this case, the priority of matching the original design is left relatively low across the entire map, allowing MCD to explore varied designs. On the left of the map, similarity to the text prompt: 'A futuristic black cyberpunk-style road racing bicycle' is prioritized, while similarity to the blue mountain bike image is prioritized on the right. Weight reduction is prioritized on the bottom while structural safety factor is prioritized at the top. When given the freedom to deviate far from the original design, the risk of generating infeasible designs increases. Nonetheless, this case study demonstrates the potential use of MCD in multimodal design problems.
Regenwetter, L, Obaideh, Y, Gutfreund, D, & Ahmed, F. Counterfactuals for Design: A Model-Agnostic Method For Design Recommendations. arXiv preprint arXiv:2302.TBD
@article{regenwetter2023counterfactuals,
title={Counterfactuals for Design: A Model-Agnostic Method For Design Recommendations},
author={Regenwetter,
Lyle and Obaideh,
Yazan and Ahmed,
Faez},
journal={arXiv preprint arXiv:2302.TBD},
year={2023}}
We would like to thank Amin Heyrani Nobari for his contributions to the image rendering pipeline that enabled much of the cross-modal work presented. We would also like to thank Tyler Butler for his feedback and edits.