Metrics
Beyond Statistical Similarity: Rethinking Evaluation Metrics for Deep Generative Models in Engineering Design
1MIT 2MIT-IBM Watson AI Laboratory
Beyond Statistical Similarity: Rethinking Evaluation Metrics for Deep Generative Models in Engineering Design
1MIT 2MIT-IBM Watson AI Laboratory
This project explores alternatives to statistical similarity for evaluating deep generative models in engineering design:
Deep generative models (DGMs) are typically evaluated using statistical similarity, which measures how similar a generated set of designs is to a dataset of designs. We consolidate and propose several metrics to evaluate various facets of statistical similarity for deep generative models.
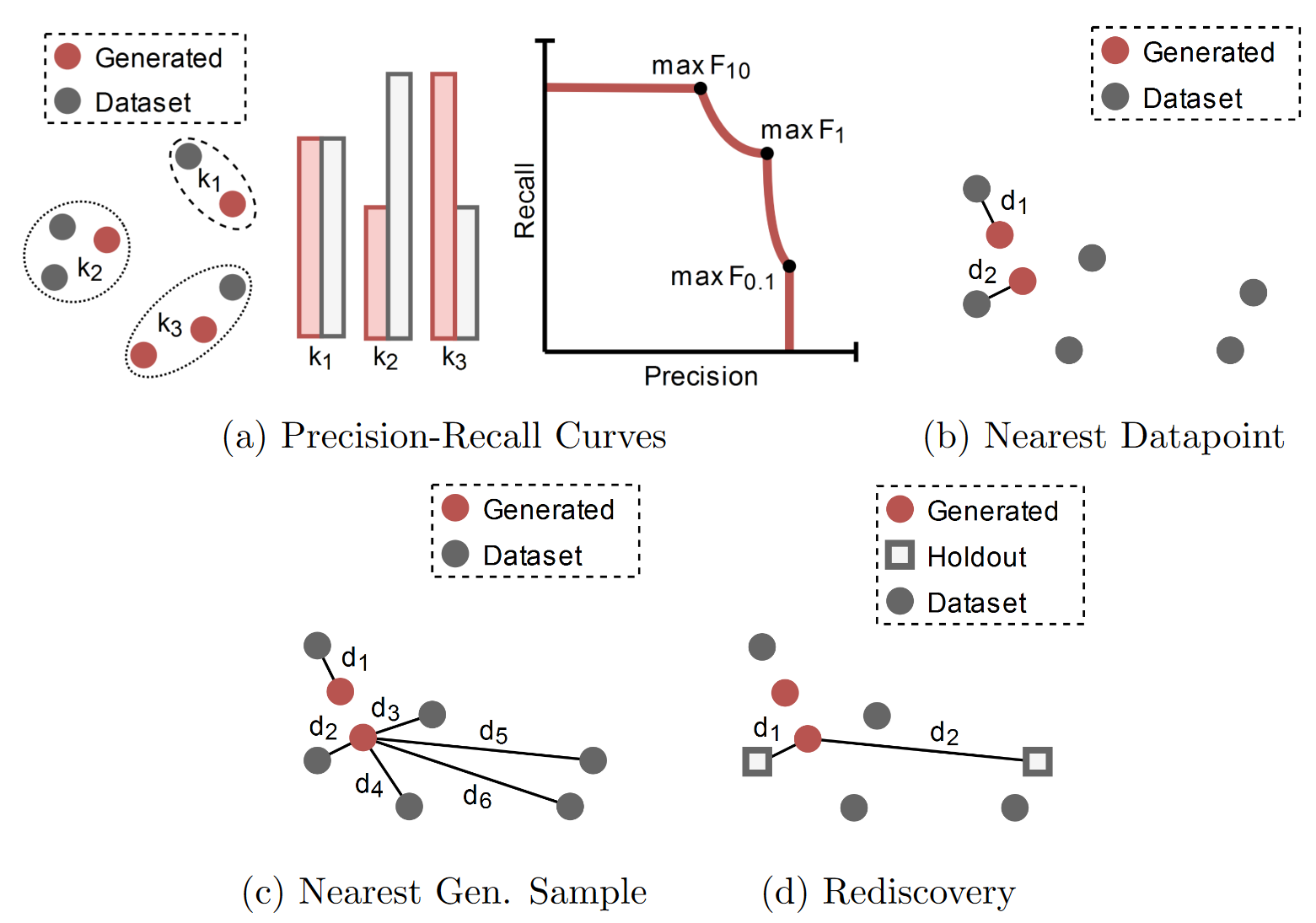
Though similarity is important for deep generative models, it is often overprioritized in design settings where an emphasis on novelty, performance or constraints may be more justified.
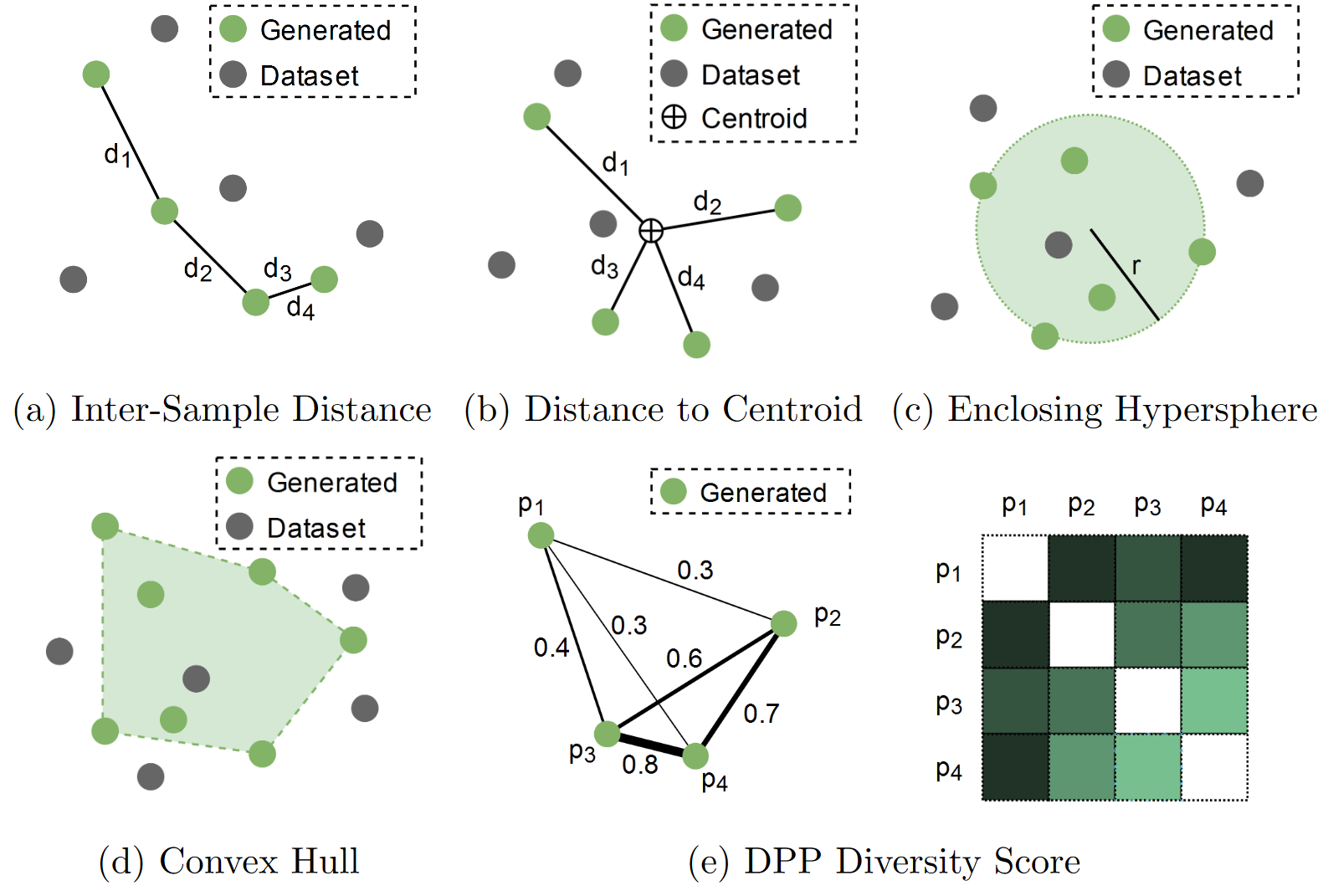
In design, we often desire designs to be novel and when working with deep generative models, we typically want models to generative diverse sets of novel designs. We consolidate numerous metrics from design methodology research and other fields for calculating diversity and novelty of designs.
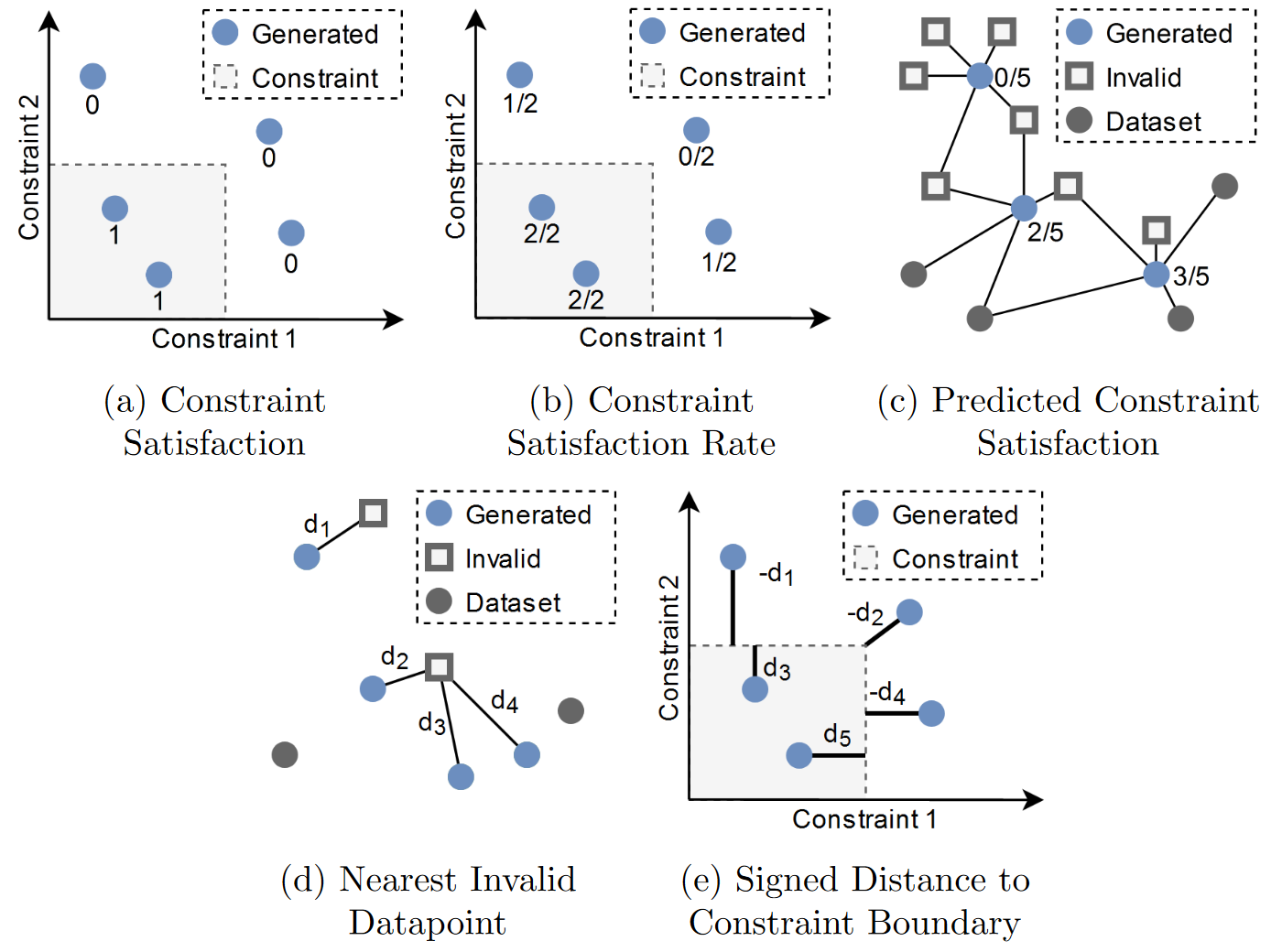
Design problems often have implicit or explicit design constraints. It is often essential that generative models for design observe these constraints and generate constraint-satisfying designs. We present several strategies to evaluate deep generative models in the presence of implicit constraints observed through data or various kinds of explicit constraints.
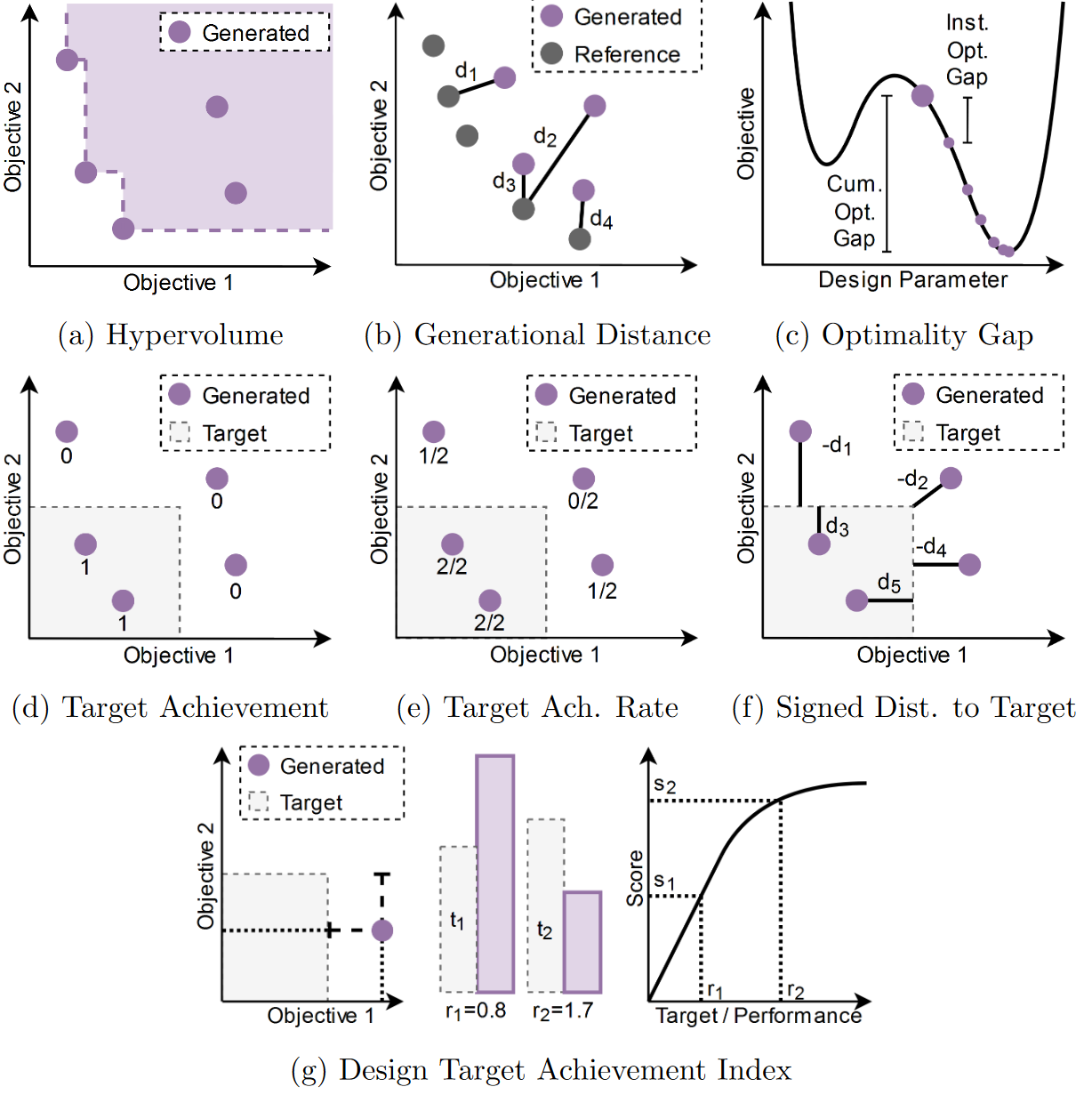
Designs are typically desired to demonstrate certain functional performance characteristics, such as weight, power output, or safety factor. Accordingly, generative models for design should be evaluated based on the quality of the designs that they generate. We provide several techiniques to evaluate functional performance of generated designs in the presence or absence of performance targets or Pareto-optimal reference sets.
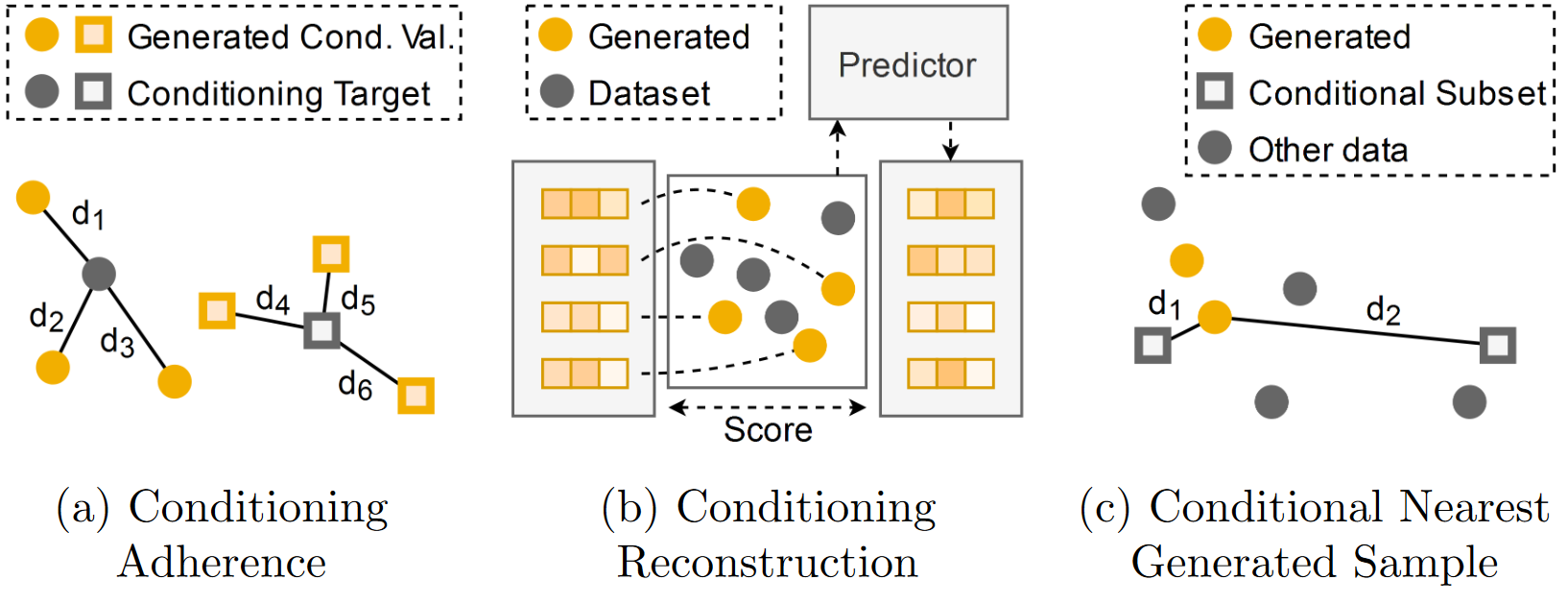
In deep generative models, conditioning refers to the process of incorporating additional information, such as labels or attributes, into the model when generating new data. Conditioning is especially important in design tasks, especially in mass customization settings where we may want to generate the optimal design conditioned on a particular user's objectives and preferences.
We train several deep generative models on the FRAMED bicycle frame dataset. We evaluate models for similarity, design exploration, constraint satisfaction, and functional performance.
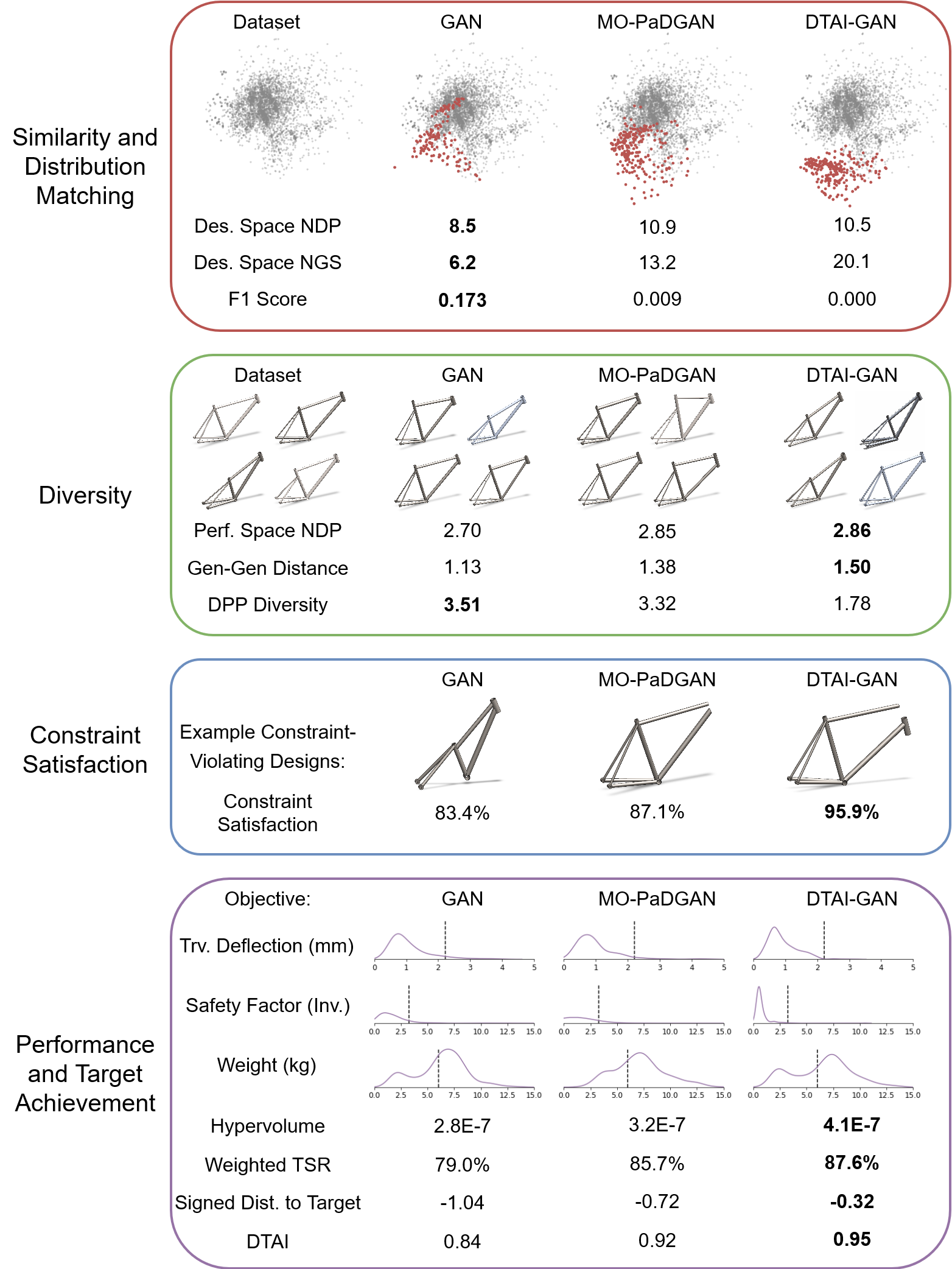
The DTAI-GAN, a GAN variant augmented with auxiliary constraint satisfaction and target achievement loss terms, is able to attain superior constraint satisfaction and target achievement performance. In doing so, it strays from the original data distribution, exploring new regions of the design space.
Next, we consider metrics to evaluate DGMs on optimal topology generation problems. In addition to the standard metrics (complaince error, volue fraction error, load validity, and floating material), we propose three new metrics. One is a variant of distance to constraint boundary, quantifying the amount of floating material. Another is topology novelty, which quantifies how different generated topologies are from the topologies generated by the Solid Isotropic Material with Penalization (SIMP) method. The thirds is the diversity of generated topologies. We test two variants of the TopoDiff model for guided diffusion of topologies. One is conditioned on FEA-generated physical fields, while the other is conditioned on kernel-estimated fields.
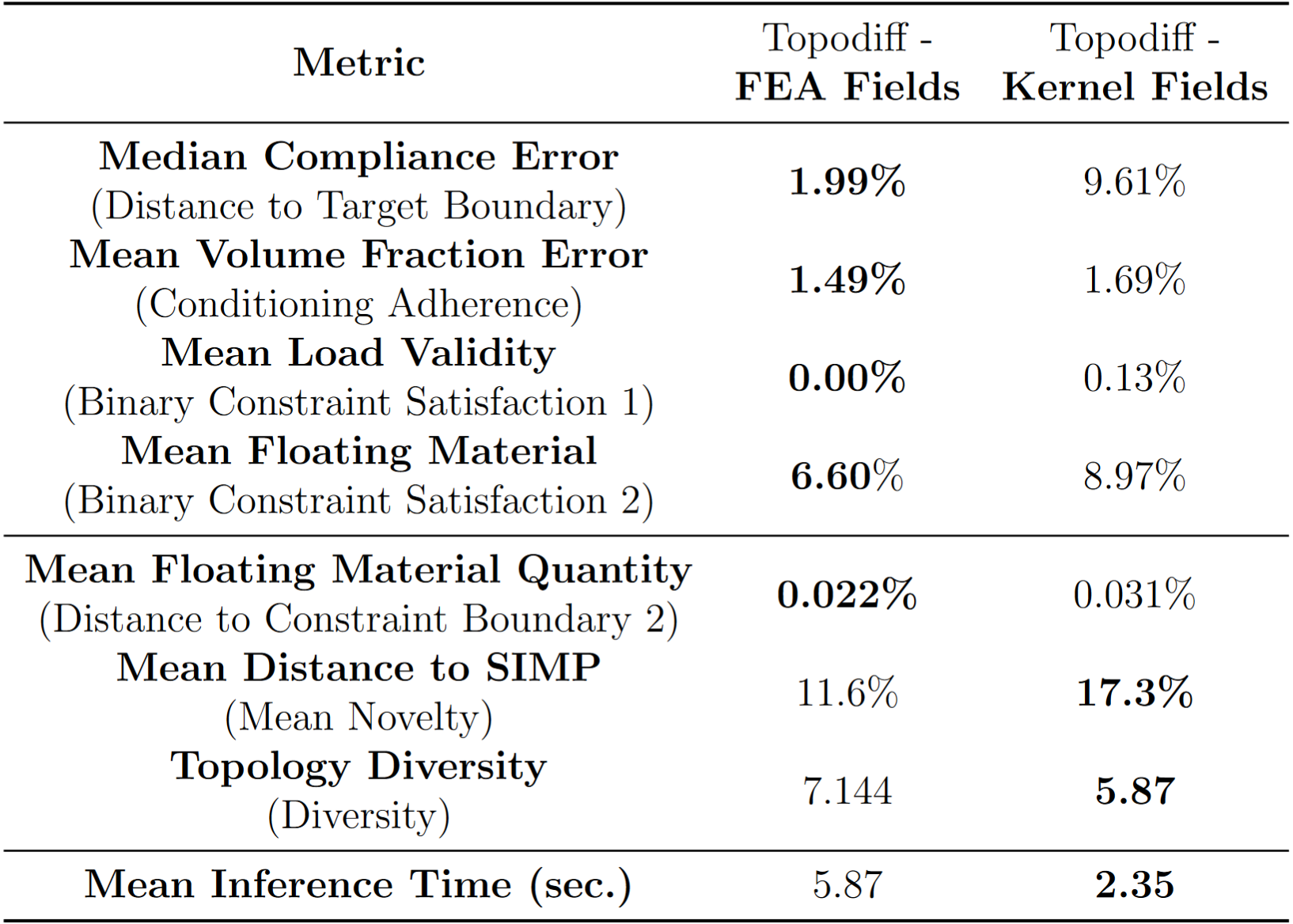
When conditioned on kernel-estimated physical fields, TopoDiff's inference time is significantly improved. Importantly, generated topologies are also more diverse and novel. This can be highly beneficial in identifying optimal topologies that may outperform SIMP. Generated topologies can also be used to re-seed SIMP and have a higher chance of yielding a more optimal topology if they are signficantly different from SIMP's original solution.
As indicated above, kernel-estimated physical fields generally tend to cause TopoDiff to generate more novel topologies that can also be higher performing.
Regenwetter, L, Srivastava, A, Gutfreund, D, & Ahmed, F. Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design. arXiv preprint arXiv:2302.02913
@article{regenwetter2023beyond,
title={Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design},
author={Regenwetter,
Lyle and Srivastava,
Akash and Gutfreund,
Dan and Ahmed,
Faez},
journal={arXiv preprint arXiv:2302.02913},
year={2023}}
The authors acknowledge the MIT-IBM Watson AI Laboratory for support.